06 - Process Synchronization
Problem 1: Critical Section and Mutual Exclusion
Section titled “Problem 1: Critical Section and Mutual Exclusion”What’s a Critical Section? What is mutual exclusion? Write a simple code to show how you would achieve mutual exclusion in a critical section using a mutex lock.
A critical section is a specific segment of code that accesses shared resources—such as global variables, shared data structures—that must not be concurrently accessed by more than one thread or process. If multiple threads execute this section at the same time, it can lead to unpredictable results or race conditions. Mutual exclusion is the programmatic property that ensures this safety; it guarantees that if one thread is executing in its critical section, no other threads are allowed to enter theirs. Essentially, it’s the “one at a time” rule that prevents data corruption in a multi-threaded environment.
Instructor Solution
pthread_mutex_t mutex;pthread_mutex_lock(&mutex);<Critical Section>pthread_mutex_unlock(&mutex);Elaboration (by LLM)
What Is a Critical Section?
A critical section is any region of code where a thread reads from or writes to a shared resource. The danger is simple: if two threads interleave their execution inside this region, the shared state can become inconsistent.
Consider a global counter count being incremented by two threads simultaneously:
// Thread A // Thread Bint temp = count; int temp = count; // Both read 5temp = temp + 1; temp = temp + 1; // Both compute 6count = temp; count = temp; // Both write 6 — one increment lost!The fix is to designate the increment as a critical section and enforce mutual exclusion around it.
What Is Mutual Exclusion?
Mutual exclusion (mutex) is the guarantee that at most one thread is executing inside a critical section at any given time. It is the foundational property that prevents race conditions.
How a Mutex Lock Enforces It
The three-line pattern in the solution is the canonical structure:
pthread_mutex_t mutex; // (1) Declare the mutex (shared between threads)
pthread_mutex_lock(&mutex); // (2) Acquire — blocks if another thread holds the lock/* Critical Section */ // (3) Safe to access shared resources herepthread_mutex_unlock(&mutex); // (4) Release — allows the next waiting thread to proceedWhat happens on lock:
- If the mutex is free → the calling thread acquires it and continues
- If the mutex is held → the calling thread is put to sleep by the OS until the lock is released
What happens on unlock:
- The mutex is marked free
- One of the sleeping threads (if any) is woken up and given the lock
Full Working Example
#include <pthread.h>#include <stdio.h>
int count = 0;pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void *increment(void *arg) { for (int i = 0; i < 100000; i++) { pthread_mutex_lock(&mutex); // Enter critical section count++; // Safe: only one thread at a time pthread_mutex_unlock(&mutex); // Exit critical section } return NULL;}
int main() { pthread_t t1, t2; pthread_create(&t1, NULL, increment, NULL); pthread_create(&t2, NULL, increment, NULL); pthread_join(t1, NULL); pthread_join(t2, NULL); printf("Final count: %d\n", count); // Always 200000}Problem 2: Atomic Instructions
Section titled “Problem 2: Atomic Instructions”What is atomic instruction? In Intel architecture, what’s the name of the atomic instruction used to implement a mutex lock?
Instructor Solution
An atomic instruction is a low-level CPU operation that executes as a single, indivisible unit, meaning it either completes fully or fails entirely with no observable intermediate state. In multi-core systems, these instructions are crucial because they prevent other processors from interfering with a memory location while the operation is in progress, typically by briefly locking the system bus or a specific cache line. In Intel (x86/x64) architecture, the primary atomic instruction used to implement a mutex lock is XCHG Exchange.
Elaboration (by LLM)
Why “Atomic” Matters
Most high-level operations that look like a single step are actually multiple machine instructions under the hood. For example, count++ compiles to three steps: load, increment, store. Between any two of these steps, the OS can context-switch another thread in, causing a race condition.
An atomic instruction collapses a multi-step operation into a single, hardware-guaranteed indivisible step. No thread can observe it mid-execution.
How the CPU Enforces Atomicity
On x86/x64 Intel hardware, atomicity is enforced via one of two mechanisms:
- Bus locking: The CPU asserts a
LOCK#signal on the memory bus for the duration of the instruction, blocking all other cores from accessing memory - Cache line locking (preferred on modern CPUs): If the target memory address is in the L1/L2 cache, the CPU locks only that cache line rather than the entire bus, which is much faster
The XCHG Instruction
XCHG (Exchange) atomically swaps the value in a register with a value in memory. When used with a memory operand, it implicitly asserts the LOCK# prefix — even without explicitly writing LOCK XCHG.
; Spinlock acquire using XCHG; Assume: EAX = 1 (desired "locked" value), [lock_var] starts at 0
spin_loop: MOV EAX, 1 ; Load "locked" value into register XCHG EAX, [lock_var] ; Atomically swap: EAX ← old value, [lock_var] ← 1 TEST EAX, EAX ; Was the old value 0 (was it unlocked)? JNZ spin_loop ; If not, spin and try again
; --- Critical Section ---
MOV [lock_var], 0 ; Release: write 0 back to memoryAtomic Operation Summary
| Instruction | Operation | Atomicity |
|---|---|---|
XCHG reg, mem | Swap register ↔ memory | Always atomic (implicit LOCK) |
LOCK CMPXCHG | Compare-and-swap | Atomic with LOCK prefix |
LOCK XADD | Fetch-and-add | Atomic with LOCK prefix |
LOCK INC | Increment memory | Atomic with LOCK prefix |
Problem 3: Test-and-Set Instruction
Section titled “Problem 3: Test-and-Set Instruction”What’s Test-and-Set instruction? What is it used for? Briefly explain.
Instructor Solution
A Test-and-Set (TSL) instruction is an atomic hardware primitive used to write a value to a memory location and return its old value as a single, indivisible step. It works by “testing” the current state of a flag (usually checking if it is 0 or 1) and “setting” it to a locked state (1) simultaneously. This prevents a race condition where two processes might see a “0” at the same time and both attempt to enter a critical section. It is primarily used to implement low-level synchronization primitives, such as spinlocks, in operating systems and multi-threaded applications. By checking the returned old value, a process can determine if it successfully acquired the lock (if the old value was 0) or if it must continue waiting in a loop (if the old value was 1).
Elaboration (by LLM)
The Core Problem TSL Solves
Without atomicity, a naive “check then set” lock has a fatal race window:
// BROKEN — non-atomic, two threads can both pass the check!while (lock == 1) {} // (1) Thread A sees lock=0, exits looplock = 1; // (2) Thread B ALSO sees lock=0 before A sets it!// Both threads now believe they hold the lock — disaster!TSL eliminates this window by making steps (1) and (2) a single uninterruptible hardware operation.
TSL Pseudocode
// Conceptual pseudocode — executes as ONE atomic hardware instructionint TestAndSet(int *lock) { int old = *lock; // "Test": read the current value *lock = 1; // "Set": unconditionally write 1 (locked) return old; // Return what we found}Using TSL to Build a Spinlock
int lock = 0; // 0 = free, 1 = locked
void acquire(int *lock) { // Spin until we observe old value of 0 (meaning WE set it from 0→1) while (TestAndSet(lock) == 1) { // lock was already 1 — someone else holds it, keep spinning } // We got old value 0 — we successfully acquired the lock}
void release(int *lock) { *lock = 0; // Simple write; no atomicity needed for release}Step-by-Step Execution Trace
Consider two threads A and B racing to acquire the lock:
| Time | Thread A | Thread B | lock value |
|---|---|---|---|
| T1 | TestAndSet(&lock) → returns 0, sets lock=1 | — | 1 |
| T2 | Enters critical section ✅ | TestAndSet(&lock) → returns 1 (spins) | 1 |
| T3 | In critical section | Spinning… | 1 |
| T4 | release() → lock=0 | TestAndSet(&lock) → returns 0, sets lock=1 | 1 |
| T5 | Done | Enters critical section ✅ | 1 |
How It Differs from XCHG
TSL and XCHG are functionally equivalent in purpose. On x86, XCHG is the physical realization of TSL. On other architectures (e.g., ARM), the equivalent is LDREX/STREX (load/store exclusive).
Problem 4: Spinlocks in Single vs. Multiprocessor Systems
Section titled “Problem 4: Spinlocks in Single vs. Multiprocessor Systems”Briefly explain why spinlocks are not appropriate for single processor systems yet are often used in multiprocessor systems.
Instructor Solution
Spinlocks are inappropriate for single-processor systems because if a thread “spins” while waiting for a resource, it consumes 100% of the CPU’s cycles, preventing the very thread that holds the lock from running and releasing it. On a single core, the only way for the lock-holder to finish is if the spinning thread is context-switched out, making the busy-waiting period entirely wasted time. Conversely, spinlocks are favored in multiprocessor systems because the lock-holder can run on a different core simultaneously. If the critical section is short, it is often more efficient to have a thread spin for a few nanoseconds than to incur the heavy overhead of a context switch—which involves saving registers and flushing caches required to put the thread to sleep and wake it up later.
Elaboration (by LLM)
What Does “Spinning” Mean?
A spinlock acquires the lock via a tight busy-wait loop — the thread actively checks the lock condition over and over instead of going to sleep:
// The thread never yields; it hammers the CPU checking the lockwhile (TestAndSet(&lock) == 1) { // Do nothing — just spin and check again}Single-Processor: A Self-Defeating Loop
On a single-core machine, there is only one execution stream at a time. The moment a thread starts spinning, it occupies the CPU 100%. Consider what this means:
Core 0: [ Thread A spins... spins... spins... ] ← uses ALL CPU time Thread B (lock holder) CAN'T RUNThread B — the one that actually holds the lock and needs to release it — cannot make any progress because it never gets CPU time. The only escape is a timer interrupt that forces a context switch, at which point the spinning was entirely wasteful. You’d have been better off blocking immediately.
Multiprocessor: Parallel Progress
On a multiprocessor system, the lock-holder and the spinner can execute simultaneously on different cores:
Core 0: [ Thread A spins... ] ← polls the lock variableCore 1: [ Thread B in critical section → releases lock ] ← runs in parallelThread A checks the lock, sees it free the moment Thread B releases it on Core 1, and immediately enters. No context switch needed at all. This is the ideal case.
The Context-Switch Cost Comparison
| Spinlock | Blocking (Mutex/Semaphore) | |
|---|---|---|
| Acquire (lock free) | ~1–10 ns | ~100–1000 ns |
| Acquire (lock held, short wait) | ~10–100 ns | ~10–100 µs (sleep + wake) |
| Acquire (lock held, long wait) | Wastes CPU cycles | Efficient — thread sleeps |
| CPU usage while waiting | 100% | ~0% |
When Spinlocks Win in Multiprocessor Systems
Spinlocks are the right choice when:
- The critical section is short (a few instructions)
- Lock contention is low (threads rarely collide)
- The overhead of putting a thread to sleep and waking it up would exceed the wait time
Problem 5: Race Condition
Section titled “Problem 5: Race Condition”What’s race condition? Briefly explain.
Instructor Solution
A race condition occurs when the timing or order of execution in a multi-threaded or concurrent system affects the final outcome, leading to unpredictable and often erroneous results. It happens when multiple threads access and manipulate shared data simultaneously, and the final state depends on which thread “wins the race” to finish its operation first. For example, if two threads try to increment a shared counter at the exact same moment, they might both read the same initial value, add one, and write back the same result, causing one of the increments to be lost entirely.
Elaboration (by LLM)
The Classic Counter Race
Consider count++, which looks like one operation but compiles to three machine instructions:
// High-level:count++;
// What the CPU actually does:// (1) LOAD: temp = count ← read from memory// (2) ADD: temp = temp + 1 ← compute// (3) STORE: count = temp ← write back to memoryIf two threads execute this concurrently, they can interleave in a broken way:
| Step | Thread A | Thread B | count in memory |
|---|---|---|---|
| 1 | LOAD → temp_A = 5 | — | 5 |
| 2 | — | LOAD → temp_B = 5 | 5 |
| 3 | ADD → temp_A = 6 | — | 5 |
| 4 | — | ADD → temp_B = 6 | 5 |
| 5 | STORE → count = 6 | — | 6 |
| 6 | — | STORE → count = 6 | 6 ← should be 7! |
One increment is silently lost. This is a race condition.
Key Characteristics of a Race Condition
- Non-deterministic: The bug may only appear under specific timing conditions (high load, certain CPU speeds, scheduler behavior). It can be nearly impossible to reproduce reliably.
- Involves shared mutable state: Read-only shared data cannot race. The danger is always concurrent writes or a mix of reads and writes.
- No guaranteed error signal: The program often doesn’t crash — it just silently produces wrong results, making races especially insidious.
A Broader Example: Read-Modify-Write Pattern
Any “read → modify → write” sequence on shared data is a race condition candidate:
// Example 1: Counter incrementbalance = balance + deposit; // Read-modify-write: RACE
// Example 2: Conditional updateif (list != NULL) { // Check node = list->next; // Use — another thread may have freed list!} // TIME-OF-CHECK vs TIME-OF-USE (TOCTOU) race
// Example 3: Lazy initializationif (instance == NULL) { // Two threads can both see NULL instance = new Singleton(); // Both create an instance — one is leaked}How to Detect Race Conditions
- Thread sanitizers: Tools like
ThreadSanitizer(TSan, built into GCC/Clang with-fsanitize=thread) instrument your code at compile time to detect concurrent accesses at runtime. - Stress testing: Run the program under high concurrency and repetition to increase the probability of triggering a race.
- Static analysis: Tools like
Helgrind(part of Valgrind) can find potential lock-order violations and unprotected accesses.
Problem 6: Critical Section Requirements
Section titled “Problem 6: Critical Section Requirements”List 4 requirements of a critical section.
Instructor Solution
To ensure that concurrent processes function correctly and safely, a solution to the critical section problem must satisfy these four fundamental requirements:
(1) Mutual Exclusion: If a process is executing in its critical section, no other processes can be executing in their critical sections for the same resource at the same time.
(2) Progress: If no process is in its critical section and some processes wish to enter, the selection of the next process to enter cannot be postponed indefinitely, and only those processes not in their remainder section can participate in the decision.
(3) Bounded Waiting (No Starvation): There must be a limit on the number of times other processes are allowed to enter their critical sections after a process has made a request to enter its own and before that request is granted, preventing starvation.
(4) Performance: The overhead of entering and exiting the critical section must be small with respect to the work being done within it.
Elaboration (by LLM)
These four requirements define a correct and practical solution to the critical section problem. Each guards against a different kind of failure:
1. Mutual Exclusion — Correctness
This is the primary safety guarantee. At any point in time, at most one process may be inside the critical section for a given shared resource.
Process A: [entry] → [CRITICAL SECTION] → [exit]Process B: [entry] → BLOCKED → [entry] → [CRITICAL SECTION] ↑ Must wait here — mutual exclusion enforcedWithout it: Race conditions and data corruption occur, as seen in Problem 5.
2. Progress — No Deadlock
If no process is currently in the critical section, and one or more processes want to enter, then a decision about who enters next must be made in finite time. Processes stuck in their “remainder section” (the non-critical parts of their code) cannot block others from deciding.
Without it: The system could deadlock even when no one is in the critical section — all processes freeze waiting for a decision that never comes.
Example of a progress violation: A poorly written lock that checks a flag set by process A, but A is sleeping — no one enters, no one decides.
3. Bounded Waiting — No Starvation
Once a process requests entry to its critical section, there is a finite upper bound on how many times other processes are allowed to enter before this process gets its turn.
Without it: A process could wait forever — technically the system is making progress, but one unlucky process is perpetually skipped (starved).
Example: If a lock always gives preference to the process with the lowest PID, a high-PID process might never get in if lower-PID processes keep arriving.
4. Performance — Practical Efficiency
The overhead of the entry/exit protocol must be proportionally small compared to the work done inside the critical section. A lock that takes 10 ms to acquire is useless for protecting a 1 µs operation.
Considerations:
| Metric | Good Sign | Red Flag |
|---|---|---|
| Lock acquisition time | Nanoseconds | Milliseconds |
| CPU usage while waiting | Low (blocking) or brief (spinning) | 100% spin for long waits |
| Contention overhead | Scales gracefully | Degrades sharply under load |
Summary: What Each Requirement Prevents
| Requirement | Failure Mode It Prevents |
|---|---|
| Mutual Exclusion | Race conditions / data corruption |
| Progress | Deadlock (no one in CS, but no one can enter) |
| Bounded Waiting | Starvation (a process waits forever) |
| Performance | Impractical lock overhead |
Problem 7: Disabling Interrupts for Locks
Section titled “Problem 7: Disabling Interrupts for Locks”List 2 reasons why it is a bad idea to implement locks by disabling interrupts.
Instructor Solution
While disabling interrupts is a simple way to achieve mutual exclusion on a single-processor system, it is generally considered a bad idea for two primary reasons:
(1) System Responsiveness and Safety: Disabling interrupts stops the CPU from responding to external events, such as keyboard input, network packets, or even critical hardware timers. If a thread disables interrupts and then enters an infinite loop or crashes, the entire system will “freeze” because the operating system cannot regain control to preempt the failing thread, potentially leading to a total system hang.
(2) Multiprocessor Ineffectiveness: In modern multiprocessor systems, disabling interrupts only affects the local core where the instruction is executed. Other cores continue to run and can still access shared memory, meaning the “lock” fails to provide mutual exclusion across the entire system. To make it work, the hardware would need to broadcast the “disable” signal to all cores, which is an incredibly slow and inefficient operation that severely degrades performance.
Elaboration (by LLM)
How Interrupt Disabling “Works” as a Lock
On a single-core system, the OS achieves mutual exclusion by briefly disabling hardware interrupts around critical kernel sections:
cli(); // Clear Interrupt Flag — CPU ignores all hardware interrupts/* Critical Section */ // No context switch possible; we "own" the CPUsti(); // Set Interrupt Flag — interrupts re-enabledSince a preemptive context switch is triggered by a timer interrupt, disabling interrupts prevents any thread switch from occurring. This is simple and effective — for kernel code on a single core. But it has two critical flaws:
Flaw 1: System-Wide Responsiveness and Safety
When interrupts are disabled, the CPU becomes deaf to the outside world:
- The keyboard interrupt that handles your keystrokes? Ignored.
- The network card saying “packet arrived”? Ignored.
- The system timer that drives scheduling and
sleep()? Ignored. - A hardware failure signal? Ignored.
Timeline with interrupts disabled:─────────────────────────────────────────────────────Interrupt disabled ──► [thread runs] ──► [BUG: infinite loop] ↑ OS timer can't fire — system hangs FOREVERThis is a security and reliability hazard. User-space code must never be given this power. Even in kernel space, interrupt-disabled regions must be kept extremely short (a handful of instructions).
Flaw 2: Useless on Multiprocessor Systems
The cli instruction (x86 “Clear Interrupt Flag”) only affects the local core’s interrupt flag. All other cores continue executing with interrupts fully enabled:
Core 0: cli() → [Critical Section] ← interrupts disabled here onlyCore 1: [runs freely, can access shared memory!]Core 2: [runs freely, can access shared memory!]There is no mutual exclusion across cores. Thread B on Core 1 can walk right into the “protected” shared data while Thread A on Core 0 thinks it holds an exclusive lock.
The “fix” — broadcasting a “disable interrupts” message to all cores via an Inter-Processor Interrupt (IPI) — is so expensive (microseconds of bus traffic) that it negates any performance advantage and is never used in practice.
Comparison: Interrupt Disabling vs. Proper Locks
| Property | Interrupt Disabling | Mutex / Spinlock |
|---|---|---|
| Single-core correctness | ✅ Yes | ✅ Yes |
| Multi-core correctness | ❌ No | ✅ Yes |
| System responsiveness | ❌ Broken while held | ✅ Unaffected |
| User-space safe | ❌ No (privileged instruction) | ✅ Yes |
| Safe for long critical sections | ❌ Dangerous | ✅ (with blocking) |
Problem 8: Deadlock
Section titled “Problem 8: Deadlock”What’s a deadlock? How does it occur? Briefly explain.
Instructor Solution
A deadlock is a specific state in a concurrent system where a set of processes are permanently blocked because each process is holding a resource and waiting to acquire a resource held by another process in the group. When this happens, none of the involved processes can ever proceed, effectively freezing that portion of the system until external intervention occurs.
Elaboration (by LLM)
The Classic Two-Thread Deadlock
The simplest deadlock involves two threads and two locks, each acquiring them in opposite order:
pthread_mutex_t lock_A = PTHREAD_MUTEX_INITIALIZER;pthread_mutex_t lock_B = PTHREAD_MUTEX_INITIALIZER;
// Thread 1 // Thread 2pthread_mutex_lock(&lock_A); pthread_mutex_lock(&lock_B);// ... does some work ... // ... does some work ...pthread_mutex_lock(&lock_B); // BLOCKS — Thread 2 holds B pthread_mutex_lock(&lock_A); // BLOCKS — Thread 1 holds A
// Neither thread can proceed. Both wait forever.Resource Allocation Graph
A deadlock can be visualized as a cycle in a resource allocation graph:
Thread 1 ──holds──► Lock A ◄──wants── Thread 2Thread 1 ──wants──► Lock B ──holds──► Thread 2If this graph contains a cycle, deadlock either exists or is possible.
The Four Coffman Conditions
A deadlock can only occur when all four of these conditions hold simultaneously. Preventing any one of them prevents deadlock:
| Condition | Description | How to Break It |
|---|---|---|
| Mutual Exclusion | Resources cannot be shared | Use lock-free data structures |
| Hold and Wait | A process holds resources while waiting for more | Require acquiring all locks at once (all-or-nothing) |
| No Preemption | Resources cannot be forcibly taken away | Allow the OS to preempt resources |
| Circular Wait | A cycle exists in the resource-wait graph | Enforce a global lock ordering |
The Most Practical Prevention: Lock Ordering
The simplest and most widely used deadlock prevention technique is enforcing a consistent global ordering on lock acquisition. If every thread always acquires lock_A before lock_B, a cycle can never form:
// Thread 1 — always acquire A before Bpthread_mutex_lock(&lock_A); // ← always firstpthread_mutex_lock(&lock_B); // ← always second// ... work ...pthread_mutex_unlock(&lock_B);pthread_mutex_unlock(&lock_A);
// Thread 2 — same ordering!pthread_mutex_lock(&lock_A); // ← always firstpthread_mutex_lock(&lock_B); // ← always second// ... work ...pthread_mutex_unlock(&lock_B);pthread_mutex_unlock(&lock_A);Deadlock vs. Livelock vs. Starvation
These are related but distinct problems:
| Problem | Description | Threads making progress? |
|---|---|---|
| Deadlock | Threads are permanently blocked waiting for each other | ❌ No |
| Livelock | Threads keep changing state but make no actual progress (e.g., both politely “backing off” forever) | Technically yes, but effectively no |
| Starvation | A thread is perpetually denied a resource by other threads | Some threads yes, the starved one no |
Problem 9: Mutex Lock vs. Binary Semaphore
Section titled “Problem 9: Mutex Lock vs. Binary Semaphore”Compare and contrast a mutex lock to a binary semaphore in terms of purpose and ownership.
Instructor Solution
While a mutex and a binary semaphore both use a 0/1 state to manage access, they differ fundamentally in intent. A mutex is strictly a locking mechanism designed for ownership and mutual exclusion; only the thread that successfully “locked” the mutex is permitted to “unlock” it. In contrast, a binary semaphore is a signaling mechanism used for task synchronization and has no concept of ownership. Any thread (or even an interrupt handler) can “signal” (post/up) a semaphore, even if it wasn’t the one that “waited” (pend/down) on it. This allows binary semaphores to coordinate actions between different parts of a system, such as a producer notifying a consumer that data is ready, whereas a mutex is purely about protecting a shared resource from concurrent access.
| Feature | Mutex | Binary Semaphore |
|---|---|---|
| Purpose | Mutual Exclusion (Protecting Resources) | Synchronization (Signaling Events) |
| Ownership | Yes (Only the locker can unlock) | No (Any thread can signal) |
| Priority Inversion | Often includes protocols to prevent it | Susceptible (No ownership to track) |
| Usage | ”I am using this." | "The data is ready.” |
Elaboration (by LLM)
Mental Model: Two Different Metaphors
Mutex = Bathroom Key 🔑
Only the person who takes the key can return it. The key represents ownership. You lock it when you enter, unlock it when you leave. No one else can “return” your key for you.
Binary Semaphore = Traffic Light 🚦
A red/green signal. The driver that stops at red is not the one who changes it to green — the traffic controller does. There is no “owner” of the signal.
Mutex: Ownership Enforced
The key property of a mutex is that the locking thread must be the unlocking thread. Many implementations (e.g., POSIX) will return an error or invoke undefined behavior if another thread tries to unlock a mutex it didn’t lock.
// Thread Apthread_mutex_lock(&m); /* critical section */pthread_mutex_unlock(&m); // ✅ Thread A unlocks what Thread A locked
// Thread Bpthread_mutex_unlock(&m); // ❌ Undefined behavior / error — Thread B doesn't own itThis ownership model enables important features:
- Deadlock detection: The OS knows which thread holds which mutex
- Priority inheritance: If a high-priority thread waits on a mutex held by a low-priority thread, the OS can temporarily boost the low-priority thread’s priority to prevent priority inversion
Binary Semaphore: No Ownership
A binary semaphore is just an integer constrained to 0 or 1 with two atomic operations:
wait()/down()/P(): Decrement. Block if value is 0.signal()/up()/V(): Increment (up to 1). Wake a blocked thread if any.
sem_t data_ready;sem_init(&data_ready, 0, 0); // Starts at 0 (no data yet)
// Producer threadproduce_data();sem_post(&data_ready); // Signal: "data is ready" — anyone can call this
// Consumer threadsem_wait(&data_ready); // Wait for signal before consumingconsume_data();The consumer did the wait, but the producer did the signal. This cross-thread signaling is impossible with a mutex.
When to Use Which
| Scenario | Use |
|---|---|
| Protecting a shared resource (linked list, counter, file) | Mutex |
| Signaling between producer and consumer | Binary Semaphore |
| One thread waiting for another to complete a task | Binary Semaphore |
| Interrupt handler waking a thread | Binary Semaphore (ISRs can’t block, but can post) |
| Preventing concurrent access to a function | Mutex |
Problem 10: Cross-Thread Mutex Unlock
Section titled “Problem 10: Cross-Thread Mutex Unlock”Is it possible for one thread to lock a mutex lock and another thread to unlock it? Why or why not. Briefly explain.
Instructor Solution
No, in a standard implementation of a mutex, it is not possible for one thread to lock it and a different thread to unlock it. This is because a mutex is built on the principle of ownership; the thread that successfully acquires the lock “owns” the right to the critical section and is the only entity responsible for releasing it once the task is complete.
Elaboration (by LLM)
Why Ownership Is Fundamental to a Mutex
A mutex internally records the thread ID of the acquiring thread at lock time. When unlock is called, the implementation checks whether the calling thread matches the recorded owner. If not, the behavior is either an explicit error or undefined behavior:
// Conceptual internal behavior of pthread_mutex_unlock:int pthread_mutex_unlock(pthread_mutex_t *m) { if (m->owner != current_thread_id()) { return EPERM; // Error: "Operation not permitted" } m->owner = NONE; // ... wake next waiting thread ... return 0;}What Happens If You Try It
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
void *thread_A(void *arg) { pthread_mutex_lock(&m); // Thread A acquires ownership printf("A locked\n"); sleep(1); // A never unlocks — ownership stays with A return NULL;}
void *thread_B(void *arg) { sleep(0.5); pthread_mutex_unlock(&m); // ❌ Thread B does not own this mutex // On Linux with PTHREAD_MUTEX_ERRORCHECK: returns EPERM // On Linux with PTHREAD_MUTEX_DEFAULT: undefined behavior return NULL;}The outcome depends on the mutex type:
| Mutex Type | Cross-thread unlock behavior |
|---|---|
PTHREAD_MUTEX_DEFAULT | Undefined behavior (may appear to “work” but corrupts state) |
PTHREAD_MUTEX_ERRORCHECK | Returns EPERM error code |
PTHREAD_MUTEX_RECURSIVE | Returns EPERM error code |
PTHREAD_MUTEX_ROBUST | Returns EPERM error code |
Why This Rule Enables Important Safety Features
The ownership constraint is not arbitrary — it enables:
Deadlock detection
The OS knows exactly which thread holds which mutex. Tooling (like pthread’s error-checking mode or debuggers) can detect cycles in the wait graph.
Priority inheritance
If a high-priority thread waits on a mutex, the OS can temporarily boost the owner thread’s priority. Without knowing the owner, this is impossible.
If You Need Cross-Thread Signaling — Use a Semaphore
If your design requires one thread to “release” a resource that was “acquired” by a different thread, a binary semaphore (Problem 9) is the correct tool. Semaphores have no ownership and explicitly support this pattern:
sem_t sem;sem_init(&sem, 0, 0); // Starts locked (0)
// Thread A — does the work, then signalsvoid *worker(void *arg) { do_work(); sem_post(&sem); // "Release" — Thread A signals even though it didn't wait return NULL;}
// Thread B — waits for signal from Avoid *waiter(void *arg) { sem_wait(&sem); // Blocks until A posts process_results(); return NULL;}Problem 11: Recursive Locking
Section titled “Problem 11: Recursive Locking”Is recursive locking possible with mutex locks? Is it possible with binary semaphores? Why or why not. Briefly explain.
Instructor Solution
Recursive locking is possible with a recursive mutex, but generally not with a binary semaphore. A recursive mutex allows the owner thread to lock the same resource multiple times without deadlocking itself, provided it performs a matching number of unlocks. A standard mutex does not allow this; if a thread tries to lock it twice, it will typically deadlock because it’s waiting for itself to release the first lock. A binary semaphore is even less suited for this because it lacks the concept of ownership; it doesn’t track which thread called “wait,” so if a thread waits on a semaphore twice, the semaphore simply sees its count hit zero and blocks the thread indefinitely, unaware that the thread already “holds” the signal.
Elaboration (by LLM)
What Is Recursive Locking?
Recursive locking occurs when a thread attempts to acquire a lock it already holds. This commonly arises in recursive functions or when a function that acquires a lock calls another function that also tries to acquire the same lock:
void process_node(Node *n) { pthread_mutex_lock(&tree_lock); // Acquire lock // ... if (n->child) { process_node(n->child); // Calls itself — tries to lock AGAIN! } pthread_mutex_unlock(&tree_lock);}Case 1: Standard (Non-Recursive) Mutex — Deadlock
A standard mutex tracks its owner, but has a lock count of exactly 0 or 1. When the same thread tries to lock it a second time:
Thread A locks mutex → success (count: 0→1, owner: A)Thread A locks mutex again → DEADLOCK Thread A is now waiting for itself to release a lock it holds. No one else can release it. The thread hangs forever.pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER; // Non-recursive by default
pthread_mutex_lock(&m); // ✅ Succeedspthread_mutex_lock(&m); // ❌ Deadlock — thread waits for itselfCase 2: Recursive Mutex — Works With a Counter
A recursive mutex extends the standard mutex with an acquisition count. Each lock increments the count; each unlock decrements it. The mutex is only truly released when the count reaches 0:
pthread_mutexattr_t attr;pthread_mutexattr_init(&attr);pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);pthread_mutex_t m;pthread_mutex_init(&m, &attr);
pthread_mutex_lock(&m); // count: 0 → 1, owner: Thread Apthread_mutex_lock(&m); // count: 1 → 2, same owner — NO DEADLOCKpthread_mutex_lock(&m); // count: 2 → 3
pthread_mutex_unlock(&m); // count: 3 → 2pthread_mutex_unlock(&m); // count: 2 → 1pthread_mutex_unlock(&m); // count: 1 → 0 — mutex truly released, other threads can acquireInternal State of a Recursive Mutex
| State | Standard Mutex | Recursive Mutex |
|---|---|---|
| Stores owner thread ID | ✅ Yes | ✅ Yes |
| Stores acquisition count | ❌ No | ✅ Yes |
| Same-thread re-lock | ❌ Deadlock | ✅ Increments count |
| Release condition | One unlock | unlock count matches lock count |
Case 3: Binary Semaphore — Immediate Deadlock
A binary semaphore has no owner tracking at all. Its state is simply 0 (unavailable) or 1 (available). When any thread calls wait() and the value is 0, it blocks — regardless of whether it was the thread that previously called wait():
Thread A calls sem_wait() → value: 1→0, Thread A continuesThread A calls sem_wait() → value is 0 → BLOCK The semaphore has no idea Thread A already "holds" it. Thread A now waits for a signal that will never come. Deadlock.Binary Semaphore State Machine:
sem_wait() sem_signal() ↓ ↓[value=1] ──wait──► [value=0] ──wait──► [BLOCKED] ↑ No owner concept — blocks foreverSummary Comparison
| Standard Mutex | Recursive Mutex | Binary Semaphore | |
|---|---|---|---|
| Recursive lock by same thread | ❌ Deadlock | ✅ Supported | ❌ Deadlock |
| Ownership tracked | ✅ Yes | ✅ Yes | ❌ No |
| Acquisition count | ❌ No | ✅ Yes | ❌ No |
| Use case | Mutual exclusion | Reentrant functions | Signaling/events |
Problem 12: Purpose of Recursive Locking
Section titled “Problem 12: Purpose of Recursive Locking”What’s the purpose of recursive locking and how do you do it? Briefly explain.
Instructor Solution
The primary purpose of recursive locking (also known as reentrant locking) is to allow a thread to reacquire a lock it already holds without causing a deadlock. This is essential in complex software designs where a function that acquires a lock calls another function that also attempts to acquire that same lock—common in object-oriented programming or nested library calls. Without a recursive mutex, the second acquisition attempt would block the thread indefinitely. Internally, it keeps track of the owner thread and a recursion count; each time the owner locks it, the count increments, and each unlock decrements it. The resource is only truly released to other threads when the count returns to zero.
Elaboration (by LLM)
The Core Problem: Reentrant Functions and Nested Lock Acquisition
Recursive locking becomes necessary whenever a function that holds a lock needs to call another function that also tries to acquire the same lock. This pattern is especially common in:
- Recursive algorithms (tree traversal, graph search) where each call frame acquires the same lock
- Object-oriented designs where a public method calls another public method on the same object
- Library code where an internal helper function and its caller both use the same guard lock
Without a recursive mutex, the second lock() call from the same thread deadlocks immediately — the thread waits for itself to release the lock it already holds.
Motivating Example: Tree Traversal
pthread_mutex_t tree_lock = PTHREAD_MUTEX_INITIALIZER; // standard (non-recursive)
int sum_tree(Node *n) { pthread_mutex_lock(&tree_lock); // Lock acquired (depth 1) if (n == NULL) { pthread_mutex_unlock(&tree_lock); return 0; } int val = n->value + sum_tree(n->left) // ❌ tries to lock again — DEADLOCK + sum_tree(n->right); pthread_mutex_unlock(&tree_lock); return val;}How to Enable Recursive Locking in POSIX
You must explicitly create the mutex with the PTHREAD_MUTEX_RECURSIVE attribute:
pthread_mutex_t lock;pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE); // Key linepthread_mutex_init(&lock, &attr);pthread_mutexattr_destroy(&attr);With this in place, the tree traversal works correctly:
pthread_mutex_t tree_lock; // initialized as RECURSIVE (see above)
int sum_tree(Node *n) { pthread_mutex_lock(&tree_lock); // depth 1: count → 1 if (n == NULL) { pthread_mutex_unlock(&tree_lock); return 0; } int val = n->value + sum_tree(n->left) // depth 2: count → 2 (no deadlock) + sum_tree(n->right); // depth 2: count → 2 pthread_mutex_unlock(&tree_lock); // count → 1 (still locked) return val; // final unlock → count → 0 (truly released)}Internal State: How the Count Works
Thread A calls lock() → owner=A, count=1Thread A calls lock() → owner=A, count=2 (same owner: just increment)Thread A calls lock() → owner=A, count=3Thread A calls unlock() → owner=A, count=2Thread A calls unlock() → owner=A, count=1Thread A calls unlock() → owner=NONE, count=0 ← truly released; Thread B can now acquireAny other thread that calls lock() while count > 0 is blocked as normal.
State Comparison: Standard vs. Recursive Mutex
| Scenario | Standard Mutex | Recursive Mutex |
|---|---|---|
| Thread A locks once | ✅ Succeeds | ✅ Succeeds |
| Thread A locks twice (same thread) | ❌ Deadlock | ✅ count → 2 |
| Thread B locks while A holds | ❌ Blocks (correct) | ❌ Blocks (correct) |
| Required unlock calls | 1 | Must match lock calls |
Problem 13: Bounded Priority Inversion
Section titled “Problem 13: Bounded Priority Inversion”Briefly explain what priority inversion is and how bounded priority inversion occurs.
Instructor Solution
Priority inversion occurs when a high-priority thread is forced to wait for a low-priority thread to release a resource (like a mutex), effectively reversing their intended importance. This “simple” inversion is unavoidable because the high-priority thread must wait for the low-priority thread to release the mutex.
Elaboration (by LLM)
What Is Priority Inversion?
In a priority-based scheduler, a high-priority thread should always be able to preempt and finish before a low-priority thread. Priority inversion breaks this guarantee: a high-priority thread ends up waiting on a low-priority thread, effectively running at the low thread’s priority for some duration.
Bounded Priority Inversion: The Simple Case
Bounded priority inversion involves exactly two threads — one high-priority (H) and one low-priority (L) — and a single shared mutex:
Time →
L: [──acquires lock──][──── critical section ────][──releases lock──] ↑H: [tries to lock — BLOCKED until L releases] ↑ [H resumes here]The inversion is called bounded because the delay imposed on H is strictly limited to the remaining duration of L’s critical section. Once L finishes and releases the lock, H can immediately acquire it and proceed. There is a clear ceiling on how long H waits.
Why It Is Considered “Unavoidable”
This form of inversion is an inherent consequence of mutual exclusion. If H needs a resource that L currently holds, H must wait — there is no way around it short of abandoning the lock entirely. The resource cannot safely be used by two threads simultaneously.
The inversion is “acceptable” precisely because it is bounded: the system designer can reason about the maximum delay H will experience based on the worst-case length of L’s critical section.
Timeline Example
| Time | Low-priority (L) | High-priority (H) | Lock State |
|---|---|---|---|
| T=0 | Acquires lock ✅ | Not started | Held by L |
| T=2 | In critical section | Arrives, tries to lock | Held by L |
| T=2 | In critical section | BLOCKED ⏸ | Held by L |
| T=6 | Releases lock, exits CS | Wakes up, acquires lock ✅ | Held by H |
| T=12 | Done | Finishes critical section | Free |
H’s delay = time L spends in the critical section after H arrives. This is bounded and predictable.
Problem 14: Unbounded Priority Inversion
Section titled “Problem 14: Unbounded Priority Inversion”Briefly explain what priority inversion is and how unbounded priority inversion occurs.
Instructor Solution
Priority inversion occurs when a high-priority thread is blocked by a low-priority thread that currently holds a required resource. Unbounded priority inversion is a severe scenario where a medium-priority thread inadvertently delays the high-priority thread for an indefinite period. This happens because the medium-priority thread does not need the locked resource and can preempt the low-priority thread (the lock-holder) to perform its own work. Since the low-priority thread is “paused” by the medium-priority task, it cannot finish its critical section or release the lock, leaving the high-priority thread stuck in a waiting state despite having the highest urgency in the system.
Elaboration (by LLM)
Setup: Three Threads, One Lock
Unbounded priority inversion requires at least three threads with distinct priorities and one mutex that M does not need:
| Thread | Priority | Needs the lock? |
|---|---|---|
| H | High | ✅ Yes |
| M | Medium | ❌ No |
| L | Low | ✅ Yes |
Step-by-Step: How It Unfolds
Step 1: L acquires the lock and enters its critical section.
L: [────── holds lock, in CS ──────►
Step 2: H wakes up and tries to acquire the lock. L holds it, so H blocks.
L: [────── holds lock, in CS ──────► H: [BLOCKED — waiting for lock]
Step 3: M wakes up. M has higher priority than L and does NOT need the lock. The scheduler preempts L and runs M instead.
L: ◄─── PREEMPTED ─── M: [──────────── running (no lock needed) ────────────► H: [BLOCKED — still waiting]
Step 4: M runs for as long as it wants. L cannot release the lock because it is not scheduled. H cannot proceed because L hasn't released the lock. H is effectively stuck at M's mercy — with NO upper bound on the wait.Timeline Diagram
L acquires lock │ H arrives, blocks M arrives, preempts L ▼ ▼ ▼──────────────────────────────────────────────────────────────► timeL: [──CS──────────────────────────────────────────────]H: [BLOCKED ···································] ← waiting indefinitelyM: [──────────────────────► ← runs freely, no lockWhy the Inversion Is “Unbounded”
In bounded priority inversion (Problem 13), H’s wait is capped by L’s critical section length. Here, M’s execution interposes between L’s lock acquisition and its release — and M can run for any arbitrary duration. If many medium-priority threads exist, or M runs a long computation, H could be delayed indefinitely. The system designer has no way to analytically bound H’s delay.
The Real-World Consequence: Mars Pathfinder (1997)
The Mars Pathfinder rover experienced exactly this bug. A low-priority meteorological data thread held a mutex. A high-priority bus management thread blocked on it. A medium-priority communications thread preempted the low-priority thread repeatedly. The high-priority thread missed its deadline, triggering the watchdog timer, which reset the entire system — causing the rover to reboot repeatedly during its mission.
Problem 15: Priority Ceiling Protocol
Section titled “Problem 15: Priority Ceiling Protocol”Briefly explain how priority ceiling protocol solves the unbounded priority inversion problem.
Instructor Solution
The Priority Ceiling Protocol (PCP) prevents unbounded priority inversion by assigning each resource a “ceiling” priority equal to the highest priority of any thread that could possibly lock it. When a thread acquires a lock, the system temporarily elevates that thread’s priority to the resource’s ceiling priority, ensuring that no medium-priority thread can preempt it. This allows the lock-holder to finish its critical section as quickly as possible and release the resource to the waiting high-priority thread. By effectively “masking” any intermediate threads that fall between the low-priority holder and the high-priority waiter, PCP ensures the inversion is strictly bounded to the time it takes to complete a single critical section.
Elaboration (by LLM)
The Key Idea: Precompute and Preempt
Priority Ceiling Protocol (PCP) is a static, proactive approach. Before runtime, each mutex is assigned a ceiling priority equal to the maximum priority of any thread that will ever lock it. The moment a thread acquires a mutex, its runtime priority is immediately raised to the ceiling — regardless of whether anyone is waiting.
Setup (offline, before runtime): Mutex X can be locked by: L (priority 1), H (priority 3) → ceiling(X) = 3 (highest of all potential lockers)
Runtime: L acquires X → L's runtime priority is boosted to 3 M (priority 2) tries to preempt L → M's priority (2) ≤ ceiling(X) (3) → M is BLOCKED L finishes CS, releases X → L's priority drops back to 1 H acquires X → H runsWhy M Cannot Preempt L
With PCP, the moment L holds the lock, its effective priority equals H’s priority (the ceiling). M, with priority 2, is strictly lower than the current effective priority of L (3). The preemptive scheduler will not switch to M because M is not the highest-priority runnable thread.
Timeline Comparison
Without PCP (unbounded inversion):
L: [acquire lock][──────CS──────]H: [BLOCKED ··········]M: [────runs freely────►H waits for M to finish before L can resume.
With PCP:
L: [acquire lock, boosted to P=3][──CS──][release]H: [runs ►M: [BLOCKED — can't preempt L]H’s wait is bounded to L’s CS duration only.
Full Three-Thread Example
| Time | L (base P=1) | M (P=2) | H (P=3) | Lock X (ceiling=3) |
|---|---|---|---|---|
| T=0 | Acquires X → effective P=3 | — | — | Held by L (P=3) |
| T=2 | In CS (P=3) | Arrives, tries to preempt | — | Held by L |
| T=2 | In CS (P=3) | Blocked (P=2 < 3) | — | Held by L |
| T=4 | In CS (P=3) | Blocked | Arrives, tries to acquire X | Held by L |
| T=4 | In CS (P=3) | Blocked | Blocked (lock held) | Held by L |
| T=6 | Releases X → P drops to 1 | Unblocked, runs | Acquires X ✅ | Held by H |
PCP vs. Priority Inheritance: Key Difference
| Property | Priority Ceiling Protocol | Priority Inheritance (P16) |
|---|---|---|
| When priority is boosted | Immediately on lock acquisition | Only when a higher-priority thread blocks |
| Priority knowledge required | Yes — must know all potential lockers | No — reacts dynamically |
| Prevents deadlock | ✅ Yes (as a side effect) | ❌ Not guaranteed |
| Implementation complexity | Higher (static analysis required) | Lower (purely reactive) |
| Blocking bound | At most one priority inversion per CS | May have chained inversions |
Problem 16: Priority Inheritance Protocol
Section titled “Problem 16: Priority Inheritance Protocol”Briefly explain how priority inheritance protocol solves the unbounded priority inversion problem.
Instructor Solution
The Priority Inheritance Protocol solves unbounded priority inversion by allowing a low-priority thread to “inherit” the priority of a higher-priority thread that is currently waiting on a resource it holds. When a high-priority thread attempts to acquire a mutex held by a low-priority thread, the system temporarily boosts the low-priority thread’s priority to match the high-priority one. This prevents medium-priority threads from preempting the lock-holder, ensuring the low-priority thread can finish its work and release the lock as quickly as possible. Once the lock is released, the thread’s priority drops back to its original level, and the high-priority thread immediately takes over.
Elaboration (by LLM)
The Key Idea: React Dynamically to Blocking
Priority Inheritance Protocol (PIP) is a reactive approach. Unlike PCP, no static analysis is required. Instead, priority is only boosted at the moment a high-priority thread actually blocks on a mutex held by a lower-priority thread.
Runtime event: H (P=3) tries to acquire mutex X, held by L (P=1) → L is blocking H → System boosts L's priority to 3 (inherits from H) → M (P=2) can no longer preempt L → L finishes CS, releases X, priority drops back to 1 → H acquires X and runsStep-by-Step Timeline
L acquires X (P=1) │ H arrives, blocks on X → L inherits P=3 │ │ M arrives → can't preempt L (L now P=3 > M's P=2) ▼ ▼ ▼────────────────────────────────────────────────────────► timeL: [CS·············│boost P=3│·········CS done][release X]H: [BLOCKED ·····················][acquires X ► runs]M: [BLOCKED until H releases or L done]Without PIP, M would preempt L (since M’s P=2 > L’s original P=1), causing unbounded delay for H. With PIP, L’s effective priority (3) exceeds M’s (2), so M cannot preempt.
Priority Propagation in Chained Blocking
PIP handles chained scenarios where multiple locks are involved. If L holds lock X and is itself waiting on lock Z held by LL (even lower priority), the inherited priority propagates through the chain:
H (P=3) waits on X held by L (P=1) → L inherits P=3L (now P=3) waits on Z held by LL (P=0) → LL inherits P=3This ensures the entire blocking chain is elevated and can proceed without medium-priority interference.
Comparison to Priority Ceiling Protocol
Priority Inheritance (reactive):
- Boost only when blocking is detected
- No need to know future lock usage
- Easier to implement incrementally
- May still allow multiple blocking events (chained inversions)
Priority Ceiling (proactive):
- Boost immediately on acquisition
- Requires static knowledge of lock users
- Also prevents deadlock
- Guarantees at most one blocking event per CS
Real-World Usage
PIP is the more commonly deployed protocol in practice because it requires no prior knowledge of which threads will use which locks:
| System | Priority Inheritance Support |
|---|---|
| Linux (POSIX) | pthread_mutexattr_setprotocol(PTHREAD_PRIO_INHERIT) |
| Windows | Implemented internally in kernel dispatcher |
| VxWorks | Default behavior for priority-aware mutexes |
| FreeRTOS | Configurable via configUSE_MUTEXES |
Problem 17: Condition Variables
Section titled “Problem 17: Condition Variables”What’s a condition variable. Why and where do you need them. Briefly explain.
Instructor Solution
A condition variable is a synchronization primitive that allows a thread to suspend its execution (sleep) until a specific condition or shared state is met. Unlike a mutex, which manages access to data, a condition variable manages the waiting for a particular event. You need them to avoid “busy-waiting” or polling, which wastes CPU cycles by repeatedly checking a condition in a loop. They are commonly used inside critical sections protected by mutex locks, where a thread inside the critical section needs to wait for a specific condition to be true and needs to release the mutex lock and sleep somewhere until the condition becomes true. After releasing the mutex lock, another thread comes in, changes the condition and “signals” or “broadcasts” to wake the sleeping thread up.
Elaboration (by LLM)
The Problem: Waiting for a Condition Inside a Critical Section
Consider a consumer thread that must wait until the shared buffer is non-empty before removing an item. A naive approach using a spinlock inside the critical section is self-defeating:
// ❌ BAD: busy-wait inside the lockpthread_mutex_lock(&mutex);while (buffer_empty()) { pthread_mutex_unlock(&mutex); // release so producer can add pthread_mutex_lock(&mutex); // re-acquire to check again // Wastes CPU; still racy between unlock and re-lock}remove_item();pthread_mutex_unlock(&mutex);This is both wasteful (burns CPU cycles) and tricky to get right. A condition variable solves this cleanly.
The Solution: Condition Variable
A condition variable (CV) provides two atomic operations:
wait(cv, mutex)— atomically releases the mutex and puts the thread to sleep. When woken, re-acquires the mutex before returning.signal(cv)— wakes one thread sleeping on the CV.broadcast(cv)— wakes all threads sleeping on the CV.
The atomicity of “release mutex + sleep” is the critical property that eliminates the race between checking the condition and going to sleep.
Canonical Pattern: Producer-Consumer
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;pthread_cond_t not_empty = PTHREAD_COND_INITIALIZER;pthread_cond_t not_full = PTHREAD_COND_INITIALIZER;
// Producervoid produce(int item) { pthread_mutex_lock(&mutex); while (buffer_full()) { // (1) check condition pthread_cond_wait(¬_full, &mutex); // (2) sleep + release mutex atomically } // (3) re-check on wake (spurious wakes!) insert(buffer, item); pthread_cond_signal(¬_empty); // (4) wake a waiting consumer pthread_mutex_unlock(&mutex);}
// Consumervoid consume() { pthread_mutex_lock(&mutex); while (buffer_empty()) { // (1) check condition pthread_cond_wait(¬_empty, &mutex); // (2) sleep + release mutex atomically } int item = remove(buffer); pthread_cond_signal(¬_full); // (4) wake a waiting producer pthread_mutex_unlock(&mutex); return item;}Why while and Not if?
The condition check on wake-up must always be a while loop, never an if:
// ❌ WRONG — vulnerable to spurious wakeupsif (buffer_empty()) pthread_cond_wait(&cv, &mutex);
// ✅ CORRECT — re-checks condition after every wakeupwhile (buffer_empty()) pthread_cond_wait(&cv, &mutex);Spurious wakeups (a thread waking up for no reason, permitted by POSIX) and the case where multiple consumers are woken by broadcast but only one item is available both require re-checking the condition after returning from wait.
The Three-Part Relationship
┌──────────────────────────────────────────────────┐│ Mutex → protects shared state ││ Condition Var → waits for / signals a change ││ Predicate → the actual boolean condition ││ (e.g., "buffer not empty") │└──────────────────────────────────────────────────┘All three must be used together. A CV without a mutexis always incorrect; a mutex without a CV forces busy-waiting.signal vs. broadcast
| Operation | Wakes | Use when |
|---|---|---|
pthread_cond_signal | One waiting thread | Exactly one thread can make progress (e.g., one item produced → one consumer) |
pthread_cond_broadcast | All waiting threads | Multiple threads might be able to proceed, or the condition is complex |
Problem 18: Priority Scheduling with Multiple Locks
Section titled “Problem 18: Priority Scheduling with Multiple Locks”Three threads T1, T2, and T3 have priorities T3 > T2 > T1. That is, T3 has the highest priority and T1 has the lowest priority. The threads execute the following code:
T1:<code sequence A>lock(X);<critical section CS>unlock(X);<code sequence B>T2:<code sequence A>lock(Y);<critical section CS>unlock(Y);<code sequence B>T3:<code sequence A>lock(X);<critical section CS>unlock(X);<code sequence B>X and Y locks are initialized to “unlocked”, i.e., they are free. Code sequence A takes 2 time units to execute, code sequence B takes 4 time units to execute, and critical section CS takes 6 time units to execute. Assume lock() and unlock() are instantaneous, and that context switching is also instantaneous. T1 arrives (starts executing) at time 0, T2 at time 4, and T3 at time 8. There is only one CPU shared by all threads.
(a) Assume that the scheduler uses a priority scheduling policy with preemption: at any time, the highest priority thread that is ready (runnable and not waiting for a lock) will run. If a thread with a higher priority than the currently running thread becomes ready, preemption will occur and the higher priority thread will start running. Diagram the execution of the three threads over time.
Instructor Solution (part a)
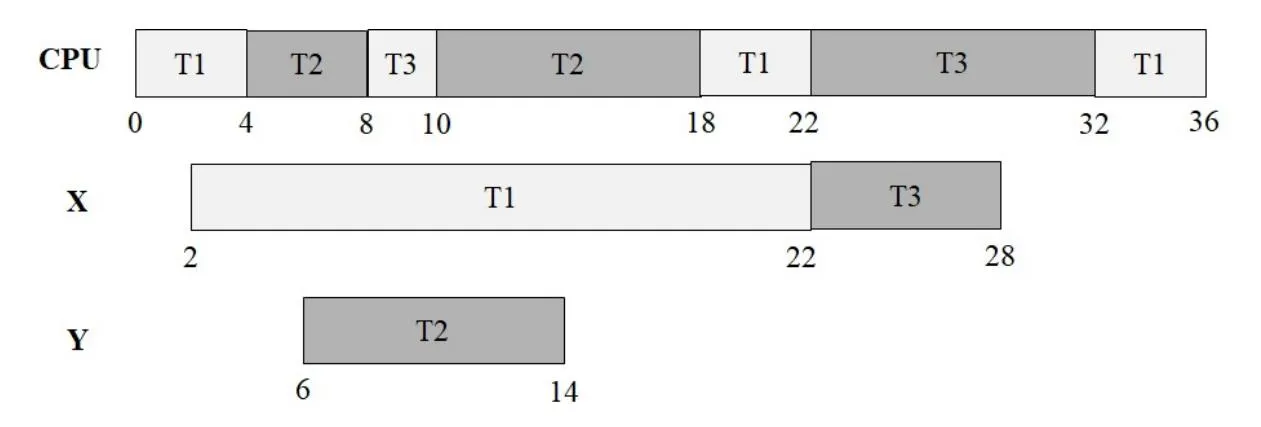
Gantt Chart(s) visualization:
CPU ┌──T1──┬───T2───┬T3┬─────T2──────┬───T1───┬──────T3──────────┬───T1──┐ 0 4 8 10 18 22 32 36
X ┌──────────────T1──────────────┬──────T3──────┐ 2 22 28
Y ┌────────T2────────┐ 6 14Elaboration (by LLM)
Tracing the Execution Step by Step
The key constraint is: the highest-priority ready (not blocked on a lock) thread always runs. Being blocked on a lock means a thread is NOT ready, even if it has high priority.
Event log:
| Time | Event | CPU | Lock X | Lock Y |
|---|---|---|---|---|
| T=0 | T1 arrives, starts running (only thread) | T1 | free | free |
| T=2 | T1 finishes seq A, acquires X | T1 | T1 | free |
| T=4 | T2 arrives (P=2 > T1’s P=1) → preempts T1 | T2 | T1 | free |
| T=6 | T2 finishes seq A, acquires Y | T2 | T1 | T2 |
| T=8 | T3 arrives (P=3 > T2’s P=2) → preempts T2 | T3 | T1 | T2 |
| T=10 | T3 finishes seq A, tries to acquire X → BLOCKED (T1 holds X) | T2 | T1 | T2 |
| T=10 | T2 is next highest ready thread → resumes CS | T2 | T1 | T2 |
| T=18 | T2 finishes CS, releases Y | T2 | T1 | free |
| T=18–22 | T2 runs seq B | T2 | T1 | free |
| T=22 | T2 finishes. T1 is only ready thread (T3 still blocked on X) → T1 resumes CS | T1 | T1 | free |
| T=28 | T1 finishes CS, releases X | T1 | free | free |
| T=28 | T3 unblocked (X now free), P=3 > T1’s P=1 → preempts T1 | T3 | T3 | free |
| T=34 | T3 finishes CS, releases X | T3 | free | free |
| T=34–38 | T3 runs seq B | T3 | free | free |
| T=38 | T3 finishes. T1 resumes seq B | T1 | free | free |
| T=42 | T1 finishes seq B. All done. | — | free | free |
Priority Inversion in Part (a)
T3 (highest priority) is blocked by T1 (lowest priority) on lock X. Meanwhile, T2 (medium priority) runs freely because it uses a different lock (Y). This is a form of bounded priority inversion: T3’s delay is bounded by how long T1 holds X — but because T2 preempted T1 earlier, T1’s time in the CS is stretched, making T3’s wait longer than it would be in isolation.
(b) “Priority inversion” is a phenomenon that occurs when a low-priority thread holds a lock, preventing a high-priority thread from running because it needs the lock. “Priority inheritance” is a technique by which a lock holder inherits the priority of the highest priority process that is also waiting on that lock. Repeat (a), but this time assuming that the scheduler employs priority inheritance. Did priority inheritance help the higher priority thread T3 finish earlier? Why or why not?
Instructor Solution (part b)
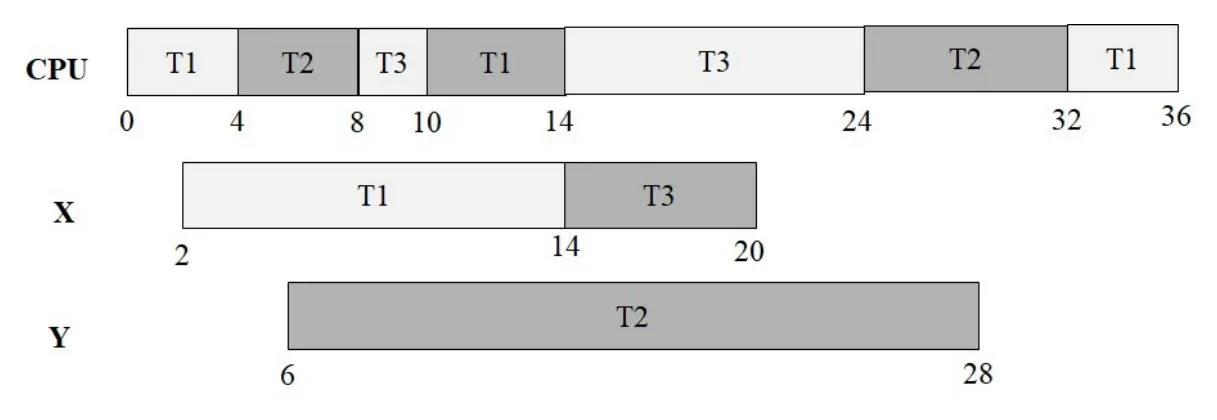
Gantt Chart(s) visualization
CPU ┌─T1─┬──T2──┬─T3─┬─T1─┬────────────T3────────────┬────T2────┬─T1─┐ 0 4 8 10 14 24 32 36
X ┌──────────────T1──────────────┬──────T3──────┐ 2 14 20
Y ┌────────────────────────T2────────────────────────┐ 6 28Yes. Priority inheritance allows T3 to finish at 24 as opposed to 32.
Elaboration (by LLM)
What Changes Under Priority Inheritance
In part (a), when T3 blocks on X (held by T1), T1 continues at its original low priority (P=1) — meaning T2 (P=2) can freely preempt T1 and run. Under Priority Inheritance, the moment T3 blocks on X, T1’s effective priority is boosted to P=3 (T3’s priority). This makes T1 higher priority than T2 (P=2), so T2 cannot preempt T1 any longer.
Step-by-Step Trace with Priority Inheritance
| Time | Event | CPU | T1 effective P | Lock X | Lock Y |
|---|---|---|---|---|---|
| T=0 | T1 arrives | T1 | 1 | free | free |
| T=2 | T1 acquires X | T1 | 1 | T1 | free |
| T=4 | T2 arrives (P=2 > T1’s P=1) → preempts | T2 | 1 | T1 | free |
| T=6 | T2 acquires Y | T2 | 1 | T1 | T2 |
| T=8 | T3 arrives (P=3) → preempts T2 | T3 | 1 | T1 | T2 |
| T=10 | T3 tries to acquire X → BLOCKED, T1 inherits P=3 | T1 | 3 | T1 | T2 |
| T=10 | T1 (now P=3) > T2 (P=2) → T1 runs, resumes CS | T1 | 3 | T1 | T2 |
| T=14 | T1 finishes CS, releases X → T1 priority drops to 1 | — | 1 | free | T2 |
| T=14 | T3 unblocked (P=3, highest ready) → acquires X, runs CS | T3 | 1 | T3 | T2 |
| T=20 | T3 finishes CS, releases X, runs seq B | T3 | 1 | free | T2 |
| T=24 | T3 finishes seq B — T3 done | — | 1 | free | T2 |
| T=24 | T2 is highest ready → runs (was in middle of CS, resumes) | T2 | 1 | free | T2 |
| T=28 | T2 finishes, releases Y, runs seq B | T2 | 1 | free | free |
| T=32 | T2 finishes seq B — T2 done | — | — | free | free |
| T=32 | T1 resumes seq B | T1 | 1 | free | free |
| T=36 | T1 finishes — T1 done | — | — | free | free |
Why T3 Finishes Earlier (24 vs. 32)
The critical difference is what happens at T=10 in each scenario:
Part (a) — No inheritance:
T3 blocks. T2 (P=2 > T1’s P=1) preempts T1 and runs its full CS (6 units) + seq B (4 units) = 10 more units before T1 can resume and finish CS. T3 is stuck until T=28 when T1 finally releases X.
Part (b) — With inheritance:
T3 blocks. T1’s priority is boosted to P=3. T2 (P=2) can no longer preempt T1. T1 immediately resumes and finishes its CS in 4 more units (T=14). T3 acquires X at T=14 and finishes its CS + seq B by T=24.
Speedup Summary
| Thread | Finish time (no inheritance) | Finish time (with inheritance) | Improvement |
|---|---|---|---|
| T3 | T=32 | T=24 | 8 units earlier |
| T2 | T=22 | T=32 | 10 units later (tradeoff) |
| T1 | T=36 | T=36 | Same |
T2 finishes later because it can no longer preempt T1 at T=10, but this is the correct tradeoff — T3’s urgency should take precedence.
Problem 19: Bounded Buffer with Producer Priority
Section titled “Problem 19: Bounded Buffer with Producer Priority”Implement a semaphore-based solution for the bounded buffer problem which adheres to the following specifications:
(1) Producers have priority over consumers. If the buffer is not full and any producer is waiting to insert an item, it has priority over any consumer.
(2) A consumer may remove an item only if there is at least one item in the buffer and no producers are waiting.
(3) Only one process may use the buffer at a time as usual.
You must implement 2 functions, Produce(int item) and Consume(). Assume a producer uses Insert(Q, item) function to insert an item to Q, and a consumer uses Remove(Q) function to remove an item from Q. Simply use these functions and do not show the details of queue manipulation. Be neat in your solution. If I do not understand what you are doing, you will not get any credit. You may use any number of POSIX mutexes, binary or counting semaphores and any other variables such as integers in your solution. Hint: This is a hybrid of two problems we have covered in class.
Instructor Solution
sem_t consumerQ = 1; // To block consumers while producers are in critical sectionmutex_t bufferMutex; // to protect shared buffermutex_t counterMutex; // to protect producerCountint producerCount = 0; // # of producers within the critical sectionsem_t full = 0; // # of full slotssem_t empty = N; // # of empty slots
Produce(item): down(empty); lock(counterMutex); producerCount++; if (producerCount == 1) down(consumerQ); // 1st producer to block consumers unlock(counterMutex); lock(bufferMutex); insert(Q, item); // Place item in Q in CS unlock(bufferMutex); lock(counterMutex); producerCount--; if (producerCount == 0) up(consumerQ); // Last producer to wake up consumers unlock(counterMutex); up(full);
Consume(): down(full); down(consumerQ); lock(bufferMutex); item = remove(Q); // Remove an item from Q in CS unlock(bufferMutex); up(consumerQ); up(empty); return item;Elaboration (by LLM)
Problem Decomposition: What Makes This Non-Standard
The classic bounded buffer (producer-consumer) problem uses symmetric semaphores. This variant adds an asymmetric priority rule: consumers are blocked entirely as long as any producer is active (waiting or inserting). This is a hybrid of:
- The bounded buffer pattern (full/empty semaphores + buffer mutex)
- The readers-writers pattern (a group-entry gate that blocks the other party while any member of the group is active)
The consumerQ semaphore acts as this gate: the first producer to arrive closes it (blocks consumers), and the last producer to leave opens it (releases consumers).
Variable Roles
| Variable | Type | Initial Value | Purpose |
|---|---|---|---|
empty | Counting semaphore | N | Tracks available empty slots; producers block here when buffer full |
full | Counting semaphore | 0 | Tracks filled slots; consumers block here when buffer empty |
bufferMutex | Mutex | unlocked | Mutual exclusion on the buffer data structure itself |
counterMutex | Mutex | unlocked | Mutual exclusion on producerCount |
consumerQ | Binary semaphore | 1 | Gate: 1=consumers may proceed, 0=consumers blocked (producer active) |
producerCount | Integer | 0 | Number of producers currently in or waiting to enter critical section |
Annotated Code Walkthrough
// ─── Shared state ───────────────────────────────────────────────sem_t consumerQ = 1; // consumer gate: open (1) initiallymutex_t bufferMutex; // guards the shared queue Qmutex_t counterMutex; // guards producerCountint producerCount = 0; // # active producers (waiting or in CS)sem_t full = 0; // slots with datasem_t empty = N; // slots available for writing
// ─── Producer ───────────────────────────────────────────────────Produce(item): down(empty); // (1) Wait for a free slot
lock(counterMutex); producerCount++; if (producerCount == 1) down(consumerQ); // (2) First producer: close gate → block consumers unlock(counterMutex);
lock(bufferMutex); insert(Q, item); // (3) Insert into buffer (exclusive access) unlock(bufferMutex);
lock(counterMutex); producerCount--; if (producerCount == 0) up(consumerQ); // (4) Last producer: open gate → allow consumers unlock(counterMutex);
up(full); // (5) Signal one more item available
// ─── Consumer ───────────────────────────────────────────────────Consume(): down(full); // (1) Wait until at least one item exists down(consumerQ); // (2) Wait until no producers are active lock(bufferMutex); item = remove(Q); // (3) Remove from buffer (exclusive access) unlock(bufferMutex); up(consumerQ); // (4) Release gate for next consumer up(empty); // (5) Signal one more empty slot return item;Why down(consumerQ) / up(consumerQ) in the Consumer?
A consumer does not hold consumerQ across the entire operation — it only needs to verify that no producers are active at the moment it enters. The sequence down → lock buffer → remove → unlock buffer → up ensures that:
- Only one consumer accesses the buffer at a time (via
bufferMutex) - The gate is re-opened immediately after, so other consumers (or checking producer status again) can proceed
Execution Trace: Producer Priority in Action
State: buffer has 2 items, 1 consumer waiting, 1 producer arrives
Consumer: down(full) ✅ (full=2→1), down(consumerQ)... waiting for valueProducer: down(empty) ✅, counterMutex: producerCount=1, down(consumerQ)=1→0 → Consumer is now blocked (consumerQ=0)Producer: inserts item, producerCount=0, up(consumerQ)=0→1 → Consumer can now proceedConsumer: down(consumerQ) ✅ (1→0), removes item, up(consumerQ) (0→1)The Readers-Writers Analogy
This pattern directly mirrors the readers-writers problem with writer priority, where writers (here: producers) block readers (consumers) as a group:
| Readers-Writers | Bounded Buffer (this problem) |
|---|---|
readerCount | producerCount |
db semaphore (blocks writers) | consumerQ semaphore (blocks consumers) |
| Reader gate mutex | counterMutex |
| Shared database | Shared buffer Q |
| Writer = exclusive access | Producer = priority access |
Problem 20: Process Precedence Constraints
Section titled “Problem 20: Process Precedence Constraints”Let 9 processes, p1 to p9, have the following precedence constraints. Initially, only p1 and p2 start. p3 and p4 start only after both p1 and p2 finish. p5, p6, and p7 start only when p4 finishes. p8 starts only after p3 and p5 finish. The last process, p9, starts only when p6, p7, and p8 finish. Show how these constraints can be implemented using semaphores. Appropriate wait and signal operations should be inserted at the beginning and end of the code for each process.
Instructor Solution
sem_t P1_done = 0;sem_t P2_done = 0;sem_t P3_done = 0;sem_t P4_done = 0;sem_t P5_done = 0;sem_t P6_done = 0;sem_t P7_done = 0;sem_t P8_done = 0;
P1: <execute> signal(P1_done); // Let go off P3 signal(P1_done); // Let go off P4
P2: <execute> signal(P2_done); // Let go off P3 signal(P2_done); // Let go off P4
P3: wait(P1_done); wait(P2_done); <execute> signal(P3_done); // Let go off P8
P4: wait(P1_done); wait(P2_done); <execute> signal(P4_done); // Let go off P5 signal(P4_done); // Let go off P6 signal(P4_done); // Let go off P7
P5: wait(P4_done); <execute> signal(P5_done); // Let go off P8
P6: wait(P4_done); <execute> signal(P6_done); // Let go off P9
P7: wait(P4_done); <execute> signal(P7_done); // Let go off P9
P8: wait(P3_done); wait(P5_done); <execute> signal(P8_done); // Let go off P9
P9: wait(P6_done); wait(P7_done); wait(P8_done); <execute>Elaboration (by LLM)
Understanding the Dependency Graph
Before writing any semaphore code, it helps to draw the precedence graph. Each directed edge means “must finish before the next starts”:
p1 ──┐ ┌── p5 ──┐ ├──► p3 ──┤ ├──► p8 ──┐ p2 ──┤ └── p6 ──┤ ├──► p9 │ │ │ └──► p4 ────────── ┤ │ │ └── p7 ──┘ └─────────────────────────────► (p5, p6, p7 all fan out from p4)More precisely:
p1, p2 ──► p3, p4 (fan-out: 1 process signals 2 dependents)p4 ──► p5, p6, p7 (fan-out: 1 process signals 3 dependents)p3, p5 ──► p8 (fan-in: 2 processes must both finish)p6, p7, p8 ──► p9 (fan-in: 3 processes must all finish)The Two Fundamental Semaphore Patterns
This problem is built entirely from two recurring patterns:
Fan-out (one signals many):
Process A must finish before B, C, and D all start. A signals its semaphore once per dependent:
// A<execute>signal(A_done); // for Bsignal(A_done); // for Csignal(A_done); // for D
// B, C, D each independently:wait(A_done);<execute>Because A_done is a counting semaphore, each signal increments the count by 1, and each wait decrements it — so three signals allow exactly three waiters to proceed.
Fan-in (many signal one):
Process D may only start after A, B, and C all finish. D waits on each predecessor’s semaphore:
// A, B, C each independently:<execute>signal(X_done); // one signal each
// D waits on all predecessors:wait(A_done);wait(B_done);wait(C_done);<execute>D is only unblocked once all three signals have been posted — regardless of order.
Why P1 and P2 Each Signal Twice
P3 and P4 both depend on P1 finishing. Each of them does wait(P1_done), so P1 must post P1_done twice — once to unblock P3’s wait, once to unblock P4’s wait. A counting semaphore accumulates these signals:
// P1signal(P1_done); // count: 0 → 1 (P3 can proceed)signal(P1_done); // count: 1 → 2 (P4 can proceed)
// P3wait(P1_done); // count: 2 → 1 ✅ proceeds immediately if P1 already done
// P4wait(P1_done); // count: 1 → 0 ✅ proceeds immediately if P1 already doneIf P1 hasn’t finished yet when P3 or P4 call wait, they block until P1 posts the signal. The order of arrival doesn’t matter — the semaphore handles it correctly either way.
Annotated Full Dependency Map
| Process | Waits for | Signals (how many times) | Reason |
|---|---|---|---|
| P1 | — | P1_done × 2 | P3 and P4 each need one |
| P2 | — | P2_done × 2 | P3 and P4 each need one |
| P3 | P1, P2 | P3_done × 1 | Only P8 depends on P3 |
| P4 | P1, P2 | P4_done × 3 | P5, P6, P7 each need one |
| P5 | P4 | P5_done × 1 | Only P8 depends on P5 |
| P6 | P4 | P6_done × 1 | Only P9 depends on P6 |
| P7 | P4 | P7_done × 1 | Only P9 depends on P7 |
| P8 | P3, P5 | P8_done × 1 | Only P9 depends on P8 |
| P9 | P6, P7, P8 | — | Terminal process |
Problem 21: Thread Termination Order with Semaphores
Section titled “Problem 21: Thread Termination Order with Semaphores”Consider a process, where the main thread creates 3 additional threads T1, T2 and T3. Assume that we want the termination order of the threads to be the following: T2, T1, T3. That is, T2 terminates first, then T1 terminates and finally T3 terminates. Use binary semaphores to achieve this coordination. You must write the code for threads T1, T2 and T3. Use any number of binary semaphores. Show their initial values. The main thread terminates after T1, T2 and T3 terminate.
Instructor Solution
sem_t T1_done = 0;sem_t T2_done = 0;sem_t T3_done = 0;sem_t notify_main = 0;
T1: wait(T2_done); // Wait for T2 to be done <execute> signal(T1_done); // Let go off T3 signal(notify_main); // Notify the main thread
T2: <execute> signal(T2_done); // Let go off T1 signal(notify_main); // Notify the main thread
T3: wait(T1_done); <execute> signal(notify_main); // Notify the main thread
main: CreateThread(T1); CreateThread(T2); CreateThread(T3); for (int i=0; i<3; i++) wait(notify_main); // Wait for all 3 threads to terminate printf("Main done");Elaboration (by LLM)
Translating the Ordering Constraint
The required termination order T2 → T1 → T3 encodes two sequencing constraints:
- T1 must not terminate until T2 has terminated
- T3 must not terminate until T1 has terminated
This is a linear chain of dependencies, which maps directly to two semaphores:
T2 finishes ──► unblocks T1 ──► unblocks T3Design Decisions
Ordering semaphores (T1_done, T2_done):
Each semaphore represents a “completion event” that the next thread in the chain waits on. Initial value = 0 so the waiter always blocks until the signal is posted.
notify_main counting semaphore:
Main needs to know when all three threads are done. Rather than joining each thread individually, each thread signals notify_main once on exit, and main loops wait three times.
Thread-by-Thread Walkthrough
sem_t T2_done = 0; // T2 completion eventsem_t T1_done = 0; // T1 completion eventsem_t notify_main = 0; // counts completions for main (0→3 over runtime)
// T2 — terminates FIRST, no dependenciesT2: <execute> signal(T2_done); // unblocks T1 (T2_done: 0 → 1) signal(notify_main); // tells main T2 is done (notify_main: N → N+1)
// T1 — terminates SECOND, waits for T2T1: wait(T2_done); // blocks until T2 signals (T2_done: 1 → 0) <execute> signal(T1_done); // unblocks T3 (T1_done: 0 → 1) signal(notify_main); // tells main T1 is done
// T3 — terminates LAST, waits for T1T3: wait(T1_done); // blocks until T1 signals (T1_done: 1 → 0) <execute> signal(notify_main); // tells main T3 is done
// Main — waits for all threemain: CreateThread(T1); CreateThread(T2); CreateThread(T3); wait(notify_main); // waits for first completion wait(notify_main); // waits for second completion wait(notify_main); // waits for third completion printf("Main done\n");Execution Trace
All threads are created simultaneously. Because T1 immediately wait(T2_done) and T3 immediately wait(T1_done), only T2 can actually execute initially:
| Time | T1 | T2 | T3 | T2_done | T1_done | notify_main |
|---|---|---|---|---|---|---|
| Start | blocks on T2_done | executes | blocks on T1_done | 0 | 0 | 0 |
| T2 finishes | unblocked ✅ | — signals → | still blocked | 1→0 | 0 | 1 |
| T1 finishes | — signals → | done | unblocked ✅ | 0 | 1→0 | 2 |
| T3 finishes | done | done | — signals → | 0 | 0 | 3 |
| Main | wait × 3 satisfied | 3→0 |
The termination order is guaranteed to be T2, T1, T3 regardless of how the OS schedules the threads, because the semaphores enforce it structurally.
Why Not Use pthread_join?
pthread_join is the standard way to wait for a thread to finish, but it couples the waiter to a specific thread and does not allow expressing ordering constraints between threads. Semaphores generalize this — any thread can wait for any other thread’s completion event, making them more flexible for complex ordering requirements.
Problem 22: Thread Scheduling with Semaphores
Section titled “Problem 22: Thread Scheduling with Semaphores”Consider the following 3 threads T1, T2 and T3 that arrive at a system at time 0 in the order T1, T2 and T3. Assume that T1 has the highest priority and T3 has the lowest priority.
| Declaration | T1 | T2 | T3 |
|---|---|---|---|
sem_t sem1 = 0; | Compute(5); | Compute(5); | Compute(5); |
sem_t sem2 = 0; | wait(&sem1); | wait(&sem2); | signal(&sem1); |
Compute(5); | Compute(8); | Compute(2); | |
signal(&sem2); | |||
Compute(5); |
Compute(n) means that the thread will do computation (use CPU) for “n” units of time. For each of the following scheduling algorithms, draw the Gantt chart.
(1) Preemptive priority scheduling
Instructor Solution (part 1)
| T1 | T2 | T3 | T1 | T3 | T2 | T3 | |
|---|---|---|---|---|---|---|---|
| 5 | 1 | 0→15 | 20 | 0→2 | 2→3 | 0→35 |
Elaboration (by LLM)
Understanding the Thread Structures
First, lay out each thread’s code as a sequence of operations with their semaphore dependencies:
T1 (highest priority): Compute(5) ← CPU burst, 5 units wait(sem1) ← blocks until T3 signals Compute(5) ← CPU burst, 5 unitsT2 (medium priority): Compute(5) ← CPU burst, 5 units wait(sem2) ← blocks until T3 signals Compute(8) ← CPU burst, 8 unitsT3 (lowest priority): Compute(5) ← CPU burst, 5 units signal(sem1) ← unblocks T1 Compute(2) ← CPU burst, 2 units signal(sem2) ← unblocks T2 Compute(5) ← CPU burst, 5 unitsStep-by-Step Trace: Preemptive Priority Scheduling
The rule is: always run the highest-priority thread that is ready (not blocked on a semaphore).
| Time | Event | Running | Ready (not blocked) | sem1 | sem2 |
|---|---|---|---|---|---|
| 0 | All arrive. T1 highest priority. | T1 | T2, T3 | 0 | 0 |
| 5 | T1 hits wait(sem1) → blocks (sem1=0). T2 next highest. | T2 | T3 | 0 | 0 |
| 6 | T2 hits wait(sem2) → blocks (sem2=0). T3 only ready thread. | T3 | — | 0 | 0 |
| 11 | T3 executes signal(sem1) → T1 unblocked. T1 (higher priority) preempts T3. | T1 | T3 | 1→0 | 0 |
| 16 | T1 finishes Compute(5). T1 done. T3 resumes (only ready thread). | T3 | — | 0 | 0 |
| 18 | T3 executes signal(sem2) → T2 unblocked. T2 (higher priority) preempts T3. | T2 | T3 | 0 | 1→0 |
| 26 | T2 finishes Compute(8). T2 done. T3 resumes. | T3 | — | 0 | 0 |
| 31 | T3 finishes Compute(5). All done. | — | — | 0 | 0 |
Gantt Chart
T1 T2 T3 T1 T3 T2 T3┌─────────┬─────┬─────────┬─────────┬─────┬───┬──────────────┬─────────┐0 5 6 11 16 18 19 27 32Key Insight: Semaphores Force a Specific Execution Order
Even though T1 and T2 have higher priority than T3, they both end up blocked and must wait for T3 to produce their signals. The semaphores create an involuntary dependency on the lowest-priority thread — a real-world scenario where priority alone does not determine who runs when.
(2) Round Robin (RR) scheduling with quanta = 4
Instructor Solution (part 2)

Gantt Chart(s) visualization
┌────T1────┬────T2────┬────T3────┬─T1─┬T2┬───T3───┬────T1────┬────T2────┬───T3───┬T1┬────T2────┐0 4 8 12 13 14 18 22 26 30 31 35Elaboration (by LLM)
Round Robin Rules
Under RR with quantum = 4, threads take turns on the CPU for at most 4 time units. If a thread blocks on a semaphore mid-quantum, it is removed from the ready queue immediately (it does not hold the CPU while blocked). When it is unblocked, it rejoins the back of the ready queue.
Ready Queue Evolution
All three threads arrive at T=0. Initial queue order (arrival order): [T1, T2, T3].
| Interval | Running | Reason for stop | Queue after | sem1 | sem2 |
|---|---|---|---|---|---|
| 0–4 | T1 | Quantum expires (used 4 of 5 compute units, 1 remaining) | [T2, T3, T1] | 0 | 0 |
| 4–8 | T2 | Quantum expires (used 4 of 5 compute units, 1 remaining) | [T3, T1, T2] | 0 | 0 |
| 8–12 | T3 | Quantum expires (used 4 of 5 compute units, 1 remaining) | [T1, T2, T3] | 0 | 0 |
| 12–13 | T1 | Finishes remaining 1 unit of Compute(5), hits wait(sem1) → blocks | [T2, T3] | 0 | 0 |
| 13–14 | T2 | Finishes remaining 1 unit of Compute(5), hits wait(sem2) → blocks | [T3] | 0 | 0 |
| 14–18 | T3 | Finishes remaining 1 unit of Compute(5) (T=15), then signal(sem1) → T1 unblocked, joins queue. Runs on: Compute(2) starts. | [T1, T3] | 1→0 | 0 |
| 18 | T3 finishes Compute(2) at T=18, executes signal(sem2) → T2 unblocked | 0 | 1→0 |
Wait — let’s carefully re-examine the T=14 to T=18 window:
- T=14: T3 has 1 unit of
Compute(5)left → runs to T=15, then executessignal(sem1). T1 is unblocked and added to the ready queue. - T=15: T3 enters
Compute(2). Queue:[T1, T3]. T3 is currently running, continues its quantum. - T=15–18: T3’s current quantum (started at 14) expires at 18. T3 runs
Compute(2)completing at T=17, then executessignal(sem2)at T=17. T2 joins queue. - T=18: Quantum ends. Queue:
[T1, T2, T3].
| Interval | Running | Event | Queue after | sem1 | sem2 |
|---|---|---|---|---|---|
| 18–22 | T1 | Compute(5): runs 4 units, 1 remaining | [T2, T3, T1] | 0 | 0 |
| 22–26 | T2 | Compute(8): runs 4 units, 4 remaining | [T3, T1, T2] | 0 | 0 |
| 26–30 | T3 | Compute(5): runs 4 units, 1 remaining | [T1, T2, T3] | 0 | 0 |
| 30–31 | T1 | Finishes last 1 unit. T1 done. | [T2, T3] | 0 | 0 |
| 31–35 | T2 | Compute(8): runs remaining 4 units. T2 done. | [T3] | 0 | 0 |
| 35–36 | T3 | Finishes last 1 unit. T3 done. | [] | 0 | 0 |
Gantt Chart
┌────T1────┬────T2────┬────T3────┬─T1─┬T2┬──T3──┬────T1────┬────T2────┬────T3────┬T1┬────T2────┐0 4 8 12 13 14 18 22 26 30 31 35Comparison: Priority vs. Round Robin
| Metric | Preemptive Priority | Round Robin (q=4) |
|---|---|---|
| T1 finishes | ~16 | 31 |
| T2 finishes | ~26 | 35 |
| T3 finishes | ~31 | 36 |
| Fairness | Low (high-priority threads dominate) | High (all threads share CPU equally) |
| T1 wait after sem1 signal | Immediate (preempts T3) | Must wait for its queue turn |
Problem 23: Monitor Alarm Clock
Section titled “Problem 23: Monitor Alarm Clock”Write a monitor using POSIX mutexes and condition variables that implements an alarm clock that enables a calling thread to delay itself for a specified number of time units (ticks). You may assume the existence of a real hardware clock, which invokes a procedure “Tick” in your monitor at regular intervals.
Instructor Solution
Monitor AlarmClock { pthread_mutex_t mutex = 1; pthread_cond_t cond; int currTime = 0;
Wait(int numOfTicksToWait) { pthread_mutex_lock(&mutex); int time2Wakeup = currTime + numOfTicksToWait; while (time2Wakeup < currTime) pthread_cond_wait(&cond, &mutex); pthread_mutex_unlock(&mutex); } // end-Wait
Tick() { // Tick is automatically called by the hardware pthread_mutex_lock(&mutex); currTime++; pthread_cond_broadcast(&cond); pthread_mutex_unlock(&mutex); } // end-Tick}; // end-AlarmClockElaboration (by LLM)
What a Monitor Is
A monitor is a high-level synchronization construct that bundles shared state and the procedures that operate on it into a single module, with the guarantee that only one thread executes inside the monitor at a time. In POSIX C, there is no native monitor keyword — we implement the concept manually using a mutex (to enforce the “one at a time” rule) and condition variables (to allow waiting threads to sleep without holding the lock).
Design Walkthrough
The alarm clock needs:
- A shared
currTimecounter that the hardware increments each tick - A way for threads to sleep until
currTimereaches their target wakeup time - A broadcast mechanism so all sleeping threads can re-check their condition on every tick
pthread_mutex_t mutex; // Monitor lock — only one thread inside at a timepthread_cond_t cond; // Condition variable — threads sleep here waiting for ticksint currTime = 0; // Shared clock, incremented by hardware
// Called by a thread that wants to delay itself by numOfTicksToWait ticksWait(int numOfTicksToWait): pthread_mutex_lock(&mutex); int time2Wakeup = currTime + numOfTicksToWait; // (1) compute target time while (currTime < time2Wakeup) // (2) re-check on every wakeup pthread_cond_wait(&cond, &mutex); // (3) sleep, release mutex atomically pthread_mutex_unlock(&mutex); // (4) done — exit monitor
// Called automatically by hardware at each clock tickTick(): pthread_mutex_lock(&mutex); currTime++; // (1) advance the clock pthread_cond_broadcast(&cond); // (2) wake ALL sleeping threads to re-check pthread_mutex_unlock(&mutex);Why broadcast and Not signal?
Multiple threads may be sleeping in Wait, each with a different time2Wakeup. On each tick:
- Some threads’ wakeup time may have arrived → they should proceed
- Others may still need to wait → they will go back to sleep after re-checking
pthread_cond_signal only wakes one sleeping thread. If that thread’s time hasn’t arrived yet, it goes back to sleep — but the thread whose time has arrived remains sleeping, never woken. pthread_cond_broadcast wakes all sleeping threads, each of which re-evaluates its own while condition and either proceeds or sleeps again.
Tick fires at currTime=10: Thread A: time2Wakeup=10 → while(10 < 10) is FALSE → exits Wait ✅ Thread B: time2Wakeup=15 → while(10 < 15) is TRUE → goes back to sleep 💤 Thread C: time2Wakeup=10 → while(10 < 10) is FALSE → exits Wait ✅The while Loop Is Mandatory
The condition check must be a while, not an if, for two reasons:
- Spurious wakeups: POSIX permits
pthread_cond_waitto return without a matching broadcast. Thewhileloop catches these. - Multiple waiters: After a broadcast, multiple threads wake up and compete for the mutex. By the time a thread reacquires the mutex and checks the condition, another thread may have already “consumed” the wakeup event. Re-checking ensures correctness.
Bug in the Instructor’s Solution
Interaction Diagram
Thread: Wait(5) called ├─ lock mutex ├─ time2Wakeup = currTime + 5 ├─ while(currTime < time2Wakeup): │ pthread_cond_wait → releases mutex, sleeps │ │Hardware: Tick() called repeatedly ├─ lock mutex ├─ currTime++ ├─ broadcast → thread wakes, reacquires mutex ├─ unlock mutex │ │Thread: ├─ re-checks while(currTime < time2Wakeup) │ if still true → sleeps again │ if false → proceeds └─ unlock mutex, returns to callerProblem 24: Alarm Clock with Semaphores
Section titled “Problem 24: Alarm Clock with Semaphores”Implement the same problem described above using POSIX mutexes and semaphores. You may use any number of mutex locks, binary and counting semaphores, and any other variables that might be necessary.
(a) Assume that there is only one thread waiting to be woken up.
Instructor Solution (part a)
pthread_mutex_t mutex;sem_t sem = 0;int threadWakeupTime = 0;int currTime = -1;
Wait(int numOfTicksToWait) { pthread_mutex_lock(&mutex); threadWakeupTime = currTime + numOfTicks; pthread_mutex_unlock(&mutex); sem_wait(&sem); // Wait until the timer expires} // end-Wait
Tick() { // Tick is automatically called by the hardware pthread_mutex_lock(&mutex); ++currTime; if (currTime == threadWakeupTime) sem_post(&sem); // Wake up the sleeping thread pthread_mutex_unlock(&mutex);} // end-TickElaboration (by LLM)
How This Differs from the Monitor (Problem 23)
The condition variable approach in Problem 23 wakes all threads on every tick and has each thread re-check its own wakeup time. The semaphore approach inverts this: the Tick() function itself checks the wakeup time and only posts the semaphore when the exact target time is reached. The sleeping thread does not need to re-evaluate — when it unblocks from sem_wait, its time has definitively arrived.
Monitor (P23): broadcast every tick → threads self-check → correct ones wake upSemaphore (P24a): Tick checks → posts only when time matches → thread wakes exactly onceAnnotated Code
pthread_mutex_t mutex; // protects currTime and threadWakeupTimesem_t sem = 0; // sleeping thread blocks here; Tick() posts when readyint threadWakeupTime = 0; // the tick count at which the thread should wakeint currTime = -1; // current clock value; starts at -1 so first Tick → 0
Wait(int numOfTicksToWait): pthread_mutex_lock(&mutex); threadWakeupTime = currTime + numOfTicksToWait; // record target tick pthread_mutex_unlock(&mutex); sem_wait(&sem); // block until Tick() posts (exactly when currTime == wakeupTime)
Tick(): pthread_mutex_lock(&mutex); ++currTime; // advance the clock if (currTime == threadWakeupTime) // has the sleeping thread's time arrived? sem_post(&sem); // yes — wake it up exactly once pthread_mutex_unlock(&mutex);Why the Mutex Is Released Before sem_wait
In Wait(), the mutex is unlocked before calling sem_wait. This is critical: if the thread held the mutex while sleeping on the semaphore, Tick() would be unable to acquire the mutex to increment currTime and post the semaphore — a deadlock.
WRONG: CORRECT: lock(mutex) lock(mutex) set wakeupTime set wakeupTime sem_wait(sem) ← holds mutex! unlock(mutex) unlock(mutex) sem_wait(sem) ← mutex free for Tick()Execution Trace: Wait(3) called when currTime = -1
| Tick # | currTime | threadWakeupTime | sem_post? | Thread state |
|---|---|---|---|---|
| — | -1 | — | — | calls Wait(3), sets wakeupTime = 2, blocks on sem_wait |
| 1st | 0 | 2 | No (0 ≠ 2) | sleeping 💤 |
| 2nd | 1 | 2 | No (1 ≠ 2) | sleeping 💤 |
| 3rd | 2 | 2 | Yes ✅ | wakes up, proceeds |
Limitation: Exactly One Waiting Thread
This design stores only a single threadWakeupTime. If two threads call Wait() concurrently, the second write overwrites the first, losing the first thread’s wakeup time entirely. Part (b) addresses this.
(b) Describe how you would extend your code if there are more than one thread waiting to be woken.
Instructor Solution (part b)
When multiple threads are waiting, a single threadWakeupTime variable is insufficient. To extend this, we would need to store the wake-up times for all waiting threads in a list or a priority queue (sorted by the earliest wake-up time). In Wait(), each thread would add its target time to this collection and then wait on its own private semaphore. In Tick(), we would iterate through the list (or check the head of the priority queue), compare the currTime to the stored values, and call sem_post() for every thread whose time has arrived.
Elaboration (by LLM)
The Core Problem with a Single Wakeup Time
In part (a), threadWakeupTime is a single shared integer. With multiple threads calling Wait(), the last writer wins — earlier registrations are silently overwritten. Each thread also shares the same semaphore, so a sem_post by Tick() wakes an arbitrary thread, not necessarily the one whose time has arrived.
The Two Required Changes
1. Per-thread wakeup registration:
Replace the single threadWakeupTime with a collection that maps each waiting thread to its target tick. A min-heap (priority queue) sorted by wakeup time is ideal: it allows Tick() to efficiently check only the earliest entries rather than scanning the entire list.
2. Per-thread semaphore:
Replace the single sem with one private semaphore per waiting thread. Each thread sleeps on its own semaphore. Tick() posts only the semaphores of threads whose time has arrived — other threads are not disturbed.
Extended Data Structure
// Entry in the priority queuetypedef struct { int wakeup_tick; // the tick count at which this thread should wake sem_t *thread_sem; // pointer to this thread's private semaphore} WaiterEntry;
// Min-heap ordered by wakeup_tick (smallest first)MinHeap waiters; // shared priority queue of WaiterEntrypthread_mutex_t mutex; // protects waiters and currTimeint currTime = -1;
Wait(int numOfTicksToWait): sem_t my_sem; sem_init(&my_sem, 0, 0); // create private semaphore, initially 0
pthread_mutex_lock(&mutex); int target = currTime + numOfTicksToWait; heap_insert(&waiters, {target, &my_sem}); // register in priority queue pthread_mutex_unlock(&mutex);
sem_wait(&my_sem); // sleep on private semaphore sem_destroy(&my_sem); // clean up after wakeup
Tick(): pthread_mutex_lock(&mutex); ++currTime; // Wake all threads whose time has arrived (may be more than one) while (!heap_empty(&waiters) && heap_min(&waiters).wakeup_tick <= currTime) { WaiterEntry e = heap_pop(&waiters); sem_post(e.thread_sem); // wake this specific thread } pthread_mutex_unlock(&mutex);Why a Priority Queue?
Using a sorted structure means Tick() only needs to look at the front of the queue. Once the minimum wakeup time exceeds currTime, there is nothing more to do — no need to scan all entries:
Heap state: [(tick=3, T2), (tick=5, T1), (tick=10, T3)]currTime = 4: → peek: tick=3 ≤ 4 → pop, sem_post(T2's sem) ✅ → peek: tick=5 > 4 → stop. T1 and T3 remain sleeping.This gives per wakeup event rather than for a linear scan.
Correctness Properties of the Extended Design
| Property | Part (a) — single thread | Part (b) — multiple threads |
|---|---|---|
| Each thread has its own semaphore | ❌ Shared | ✅ Private per thread |
| Wakeup times stored correctly | ❌ Last write wins | ✅ All registrations kept |
| Tick wakes correct thread(s) | ❌ Arbitrary thread | ✅ Exactly those whose time arrived |
| Efficiency of Tick | , = threads waking |
Problem 25: Red and Blue Thread Alternation
Section titled “Problem 25: Red and Blue Thread Alternation”Consider the following synchronization problem: There are two types of threads, Red and Blue, which try to enter a critical section (CS) by taking turns as follows:
(1) A Red thread arrives and sees nobody inside the CS, it enters the CS.
(2) A Red thread arrives and sees that at most 2 more Red threads have been allowed inside the CS, it enters the CS. Notice that more than 1 Red thread is allowed inside the CS.
(3) A Red thread arrives and sees that 3 Red threads have already been allowed inside the CS before itself, it blocks.
(4) After all 3 Red threads leave the CS, it is the Blue threads’ turn: If there are any Blue threads waiting to enter the CS, at most 3 Blue threads are let inside the CS. But if there are no Blue threads waiting to enter the CS, then 3 more Red threads are allowed to enter the CS.
(5) Above rules apply to Blue threads (simply exchange Red with Blue and Blue with Red in above rules).
The problem can also be stated as follows: You are to let in at most 3 Red (or Blue) threads inside the CS before it is the other sides’ turn to enter the CS. Thus you must alternate between 3 Red threads and 3 Blue threads. Notice also that this is NOT strict alternation between the Red and Blue threads. In other words, if there are no Blue threads waiting to enter the CS, but there are lots of Red threads, then you must allow another set of Red threads to enter the CS after the current set of Red threads leave the CS. The same is true with Blue threads.
You must implement 2 functions, 1 for Red threads and 1 for Blue threads. You are allowed to use only POSIX locks and POSIX condition variables. No semaphores are allowed for this exercise. Be neat in your solution. If I do not understand what you are doing, you will not get any credit.
Instructor Solution
pthread_mutex_t mutex;pthread_cond_t redCond;int numRedWaiting = 0;int numRedInside = 0;int numRedInThisBatch = 0;
// Red thread entrypthread_mutex_lock(&mutex);numRedWaiting++;// 1. There are Blue threads inside.// 2. 3 Red threads are already inside.// 3. 3 Red threads have already entered this "batch" AND there are Blue threads waiting.while (numBlueInside > 0 || numRedInside == 3 || (numRedInThisBatch == 3 && numBlueWaiting > 0)) { pthread_cond_wait(&redCond, &mutex);}numRedWaiting--;numRedInside++;numRedInThisBatch++;pthread_mutex_unlock(&mutex);
// <CS>
// Red thread exitpthread_mutex_lock(&mutex);numRedInside--;if (numRedInside == 0) { numRedInThisBatch = 0; if (numBlueWaiting > 0) { pthread_cond_broadcast(&blueCond); } else { pthread_cond_broadcast(&redCond); }}pthread_mutex_unlock(&mutex);
pthread_cond_t blueCond;int numBlueWaiting = 0;int numBlueInside = 0;int numBlueInThisBatch = 0;
// Blue thread entrypthread_mutex_lock(&mutex);numBlueWaiting++;// 1. There are Red threads inside.// 2. 3 Blue threads have already entered this "batch" AND there are Red threads waiting.// 3. 3 Blue threads are already inside.while (numRedInside > 0 || numBlueInside == 3 || (numBlueInThisBatch == 3 && numRedWaiting > 0)) { pthread_cond_wait(&blueCond, &mutex);}numBlueWaiting--;numBlueInside++;numBlueInThisBatch++;pthread_mutex_unlock(&mutex);
// <CS>
// Blue thread exitpthread_mutex_lock(&mutex);numBlueInside--;if (numBlueInside == 0) { numBlueInThisBatch = 0; if (numRedWaiting > 0) { pthread_cond_broadcast(&redCond); } else { pthread_cond_broadcast(&blueCond); }}pthread_mutex_unlock(&mutex);Elaboration (by LLM)
Problem Decomposition
This problem is a generalization of the classic readers-writers problem, but with two symmetric “sides” (Red and Blue) that alternate in batches of up to 3. The key rules to enforce are:
- Mutual exclusion between colors: No Red and Blue threads may be inside simultaneously.
- Batch size limit: At most 3 threads of the same color may be inside at once.
- Batch count limit with fairness: Once 3 threads of one color have entered this batch (even if some haven’t left yet), no more of that color may enter if the other color is waiting — this prevents starvation.
- Batch handoff: The last thread of a color to leave the CS decides who goes next.
Shared State Variables
| Variable | Purpose |
|---|---|
numRedWaiting / numBlueWaiting | Count of threads blocked trying to enter |
numRedInside / numBlueInside | Count of threads currently executing in the CS |
numRedInThisBatch / numBlueInThisBatch | Count of threads admitted in the current batch (resets to 0 when the last thread exits) |
redCond / blueCond | Condition variables — Red threads sleep on redCond, Blue on blueCond |
mutex | Single mutex protecting all shared state |
The Entry Condition (while loop)
The while loop for Red thread entry blocks if any of these three conditions are true:
while (numBlueInside > 0 // (1) Blue threads currently in CS — must wait || numRedInside == 3 // (2) CS is full (3 Reds already inside) || (numRedInThisBatch == 3 // (3) This batch is exhausted AND... && numBlueWaiting > 0)) // ...Blue threads are waiting (fairness!){ pthread_cond_wait(&redCond, &mutex);}Condition (3) is the subtle fairness rule: if 3 Reds have already been admitted this batch but all 3 are still inside, a 4th Red would normally be blocked by condition (2). But even after some of them exit (so numRedInside < 3), if numRedInThisBatch == 3 and Blues are waiting, new Reds must still wait — the batch is considered “spent” and it’s time to switch sides.
The Exit Logic (Batch Handoff)
The last Red thread to exit the CS is responsible for:
- Resetting
numRedInThisBatch = 0(clearing the batch counter for the next Red turn) - Deciding who goes next: Blue threads if any are waiting, otherwise more Red threads
pthread_mutex_lock(&mutex);numRedInside--;if (numRedInside == 0) { // Am I the last Red to leave? numRedInThisBatch = 0; // Reset batch counter if (numBlueWaiting > 0) pthread_cond_broadcast(&blueCond); // Wake all Blues — their turn else pthread_cond_broadcast(&redCond); // No Blues waiting — allow next Red batch}pthread_mutex_unlock(&mutex);Why broadcast and Not signal?
Up to 3 threads of the same color may be allowed into the CS simultaneously. A single signal would only wake one waiting thread. broadcast wakes all waiting threads of that color, and each of them re-evaluates the while condition — up to 3 will successfully enter, and any excess (e.g., a 4th Red) will re-block because condition (2) numRedInside == 3 becomes true.
Scenario Walkthrough
Initial state: 5 Red threads (R1–R5) and 2 Blue threads (B1–B2) all waiting.
Step 1: No one is inside. Red threads win (assume Red goes first). R1, R2, R3 enter CS. numRedInside=3, numRedInThisBatch=3. R4, R5 try to enter: blocked (condition 2: numRedInside==3).
Step 2: R1 exits. numRedInside=2. R4 tries to enter: blocked (condition 3: batch==3 AND blueWaiting>0). R5 tries to enter: blocked (same reason).
Step 3: R2 exits. numRedInside=1. Still blocked (R4, R5): same reason.
Step 4: R3 exits. numRedInside=0 → LAST RED OUT. numRedInThisBatch = 0. numBlueWaiting > 0 → broadcast(blueCond). B1, B2 wake up, enter CS. numBlueInside=2, numBlueInThisBatch=2. R4, R5 still blocked (condition 1: numBlueInside > 0).
Step 5: B1 and B2 exit. numBlueInside=0 → LAST BLUE OUT. numBlueInThisBatch = 0. numRedWaiting > 0 → broadcast(redCond). R4, R5 enter CS. numRedInside=2, numRedInThisBatch=2.State Variable Summary Table
| After event | numRedInside | numRedInThisBatch | numBlueInside | numBlueWaiting |
|---|---|---|---|---|
| R1, R2, R3 enter | 3 | 3 | 0 | 2 |
| R1 exits | 2 | 3 | 0 | 2 |
| R3 exits (last) | 0 | 0 (reset) | 0→2 | 2→0 |
| B1, B2 enter | 0 | 0 | 2 | 0 |
| B2 exits (last) | 0 | 0 | 0 | 0 |
Problem 26: Thread Scheduling with Multiple Semaphores
Section titled “Problem 26: Thread Scheduling with Multiple Semaphores”Consider the following 3 threads T1, T2 and T3:
sem_t S1 = 1;sem_t S2 = 0;sem_t S3 = 0;sem_t S4 = 0;T1-----------------------------wait(S1);DoWork(); // 5 units of timesignal(S1);signal(S3);DoWork(); // 3 units of timewait(S4);DoWork(); // 2 units of timeT2-----------------------------DoWork(); // 1 unit of timewait(S2);DoWork(); // 3 units of timesignal(S4);T3-----------------------------DoWork(); // 2 unit of timewait(S3);DoWork(); // 2 units of timesignal(S2);Assume that all threads arrive at time 0. Further assume that T3 has the highest priority, T2 has the next highest priority and T1 has the lowest priority (T3 > T2 > T1).
(a) Show the Gantt diagram with non-preemptive priority scheduling.
Instructor Solution (part a)

Gantt Chart(s) visualization
┌──T3──┬T2┬────────────T1────────────┬──T3──┬──T2──┬──T1──┐0 2 3 11 13 16 18Elaboration (by LLM)
Semaphore Dependency Map
Before tracing, identify what each semaphore controls:
| Semaphore | Initial | Producer | Consumer | Meaning |
|---|---|---|---|---|
| S1 | 1 | T1 (after DoWork) | T1 (at start) | Mutex-like: T1 must acquire before its first work burst |
| S2 | 0 | T3 (after its 2nd DoWork) | T2 (after its 1st DoWork) | T2’s second burst depends on T3 finishing |
| S3 | 0 | T1 (after signal S1) | T3 (after its 1st DoWork) | T3’s second burst depends on T1 releasing S3 |
| S4 | 0 | T2 (after its 2nd DoWork) | T1 (before its 3rd DoWork) | T1’s last burst depends on T2 finishing |
Non-Preemptive Priority: Rules
Under non-preemptive scheduling, once a thread starts running, it runs to completion or until it voluntarily blocks (e.g., hits a wait() on a semaphore with value 0). The highest-priority ready thread is then selected.
Step-by-Step Trace
All threads arrive at T=0. Ready queue (ordered by priority): [T3, T2, T1].
| Interval | Running | Event at end | Ready after | S1 | S2 | S3 | S4 |
|---|---|---|---|---|---|---|---|
| 0–2 | T3 | Finishes DoWork(2), hits wait(S3) → S3=0, blocks | [T2, T1] | 1 | 0 | 0 | 0 |
| 2–3 | T2 | Finishes DoWork(1), hits wait(S2) → S2=0, blocks | [T1] | 1 | 0 | 0 | 0 |
| 3–3 | T1 | Hits wait(S1) → S1=1→0, proceeds (non-blocking) | [T1] | 0 | 0 | 0 | 0 |
| 3–8 | T1 | Finishes DoWork(5), executes signal(S1) (S1→1), signal(S3) (S3→1). T3 unblocked → joins ready queue. | [T3, T1] | 1 | 0 | 1→0 | 0 |
| 8–8 | — | T1 is non-preemptive and still running — continues with DoWork(3) | [T3, T1] | 1 | 0 | 0 | 0 |
| 8–11 | T1 | Finishes DoWork(3), hits wait(S4) → S4=0, blocks | [T3] | 1 | 0 | 0 | 0 |
| 11–13 | T3 | Finishes DoWork(2), executes signal(S2) (S2→1). T2 unblocked. | [T2] | 1 | 1→0 | 0 | 0 |
| 13–13 | T2 | wait(S2) resolves, proceeds with DoWork(3) | [T2] | 1 | 0 | 0 | 0 |
| 13–16 | T2 | Finishes DoWork(3), executes signal(S4) (S4→1). T1 unblocked. | [T1] | 1 | 0 | 0 | 1→0 |
| 16–18 | T1 | Finishes DoWork(2). T1 done. | [] | 1 | 0 | 0 | 0 |
Gantt Chart
┌──T3──┬─T2─┬────────────T1────────────┬──T3──┬──T2──┬──T1──┐0 2 3 11 13 16 18Key Insight: S1 is a Mutex, Not a Synchronization Signal
S1 starts at 1 and is acquired then released by T1 itself. In this particular trace, T1 is the only thread that uses S1, so it effectively acts as a private gate. In a scenario with multiple T1-type threads sharing S1, it would serve as a proper mutex limiting access to one at a time.
(b) Show the Gantt diagram with preemptive priority scheduling.
Instructor Solution (part b)
| T3 | T2 | T1 | T3 | T2 | T1 | ||
|---|---|---|---|---|---|---|---|
| 0 | 2 | 3 | 8 | 1 | 0 | 13 | 18 |
Elaboration (by LLM)
Preemptive Priority: Rules
Under preemptive priority scheduling, the highest-priority ready thread runs at all times. If a higher-priority thread becomes ready (unblocked) while a lower-priority thread is running, the lower-priority thread is immediately preempted.
Step-by-Step Trace
| Interval | Running | Event | Preemption? | S1 | S2 | S3 | S4 |
|---|---|---|---|---|---|---|---|
| 0–2 | T3 | Finishes DoWork(2), hits wait(S3)=0 → blocks | — | 1 | 0 | 0 | 0 |
| 2–3 | T2 | Finishes DoWork(1), hits wait(S2)=0 → blocks | — | 1 | 0 | 0 | 0 |
| 3–3 | T1 | wait(S1)=1 → proceeds | — | 0 | 0 | 0 | 0 |
| 3–8 | T1 | Finishes DoWork(5), signal(S1) (S1→1), signal(S3) (S3→1) → T3 unblocked | T3 preempts T1 | 1 | 0 | 1 | 0 |
| 8–10 | T3 | Finishes DoWork(2), signal(S2) (S2→1) → T2 unblocked | T2 preempts T1 (T3 done; T2 > T1) | 1 | 1 | 0 | 0 |
| 10–13 | T2 | Finishes DoWork(3), signal(S4) (S4→1) → T1 unblocked | T2 done; T1 runs | 1 | 0 | 0 | 1 |
| 13–16 | T1 | Continues DoWork(3) (was preempted at T=8 after signaling) | — | 1 | 0 | 0 | 0 |
| 16–16 | T1 | wait(S4)=1→0 → proceeds | — | 1 | 0 | 0 | 0 |
| 16–18 | T1 | Finishes DoWork(2). All done. | — | 1 | 0 | 0 | 0 |
Gantt Chart
┌──T3──┬─T2─┬─────T1─────┬──T3──┬──T2──┬─────────T1─────────┐0 2 3 8 10 13 18Comparison: Non-Preemptive vs. Preemptive
| Interval | Non-Preemptive | Preemptive | Difference |
|---|---|---|---|
| T=8–11 | T3 runs | T3 runs | Same (T3 was unblocked at T=8 in both) |
| T=11–13 | T2 runs | T2 runs | Same |
| Completion | T=18 | T=18 | Same total time here |
In this particular problem, preemption at T=8 (T3 preempts T1) happens at the exact moment T1 signals S3 — so T1 had just finished its current burst anyway. The overall schedule ends at the same time, but the order of execution between T=8 and T=13 differs slightly depending on where exactly T1 was mid-burst when T3 became ready.
Problem 27: Scheduling Comparison with Locks and Semaphores
Section titled “Problem 27: Scheduling Comparison with Locks and Semaphores”Consider the following 3 threads T1, T2 and T3 that arrive at a system at time 0. Assume that T1 has the lowest priority and T3 has the highest priority (T3 > T2 > T1).
pthread_mutex_t mutex; // A POSIX lockpthread_sem_t sem1 = 0; // Initial value of the semaphore is 0pthread_sem_t sem2 = 0; // Initial value of the semaphore is 0pthread_sem_t sem3 = 0; // Initial value of the semaphore is 0T1-------Compute(2);lock(&mutex);Compute(3);unlock(&mutex);signal(&sem1);Compute(2);wait(&sem3);Compute(2);T2-------Compute(1);wait(&sem1);Compute(3);signal(&sem2);Compute(2);T3-------lock(&mutex);Compute(3);unlock(&mutex);wait(&sem2);Compute(3);signal(&sem3);Compute(2);Compute(n) means that the thread will do computation (use CPU) for “n” units of time. For each of the following scheduling algorithms, draw the Gantt chart, indicate the turnaround time for each process and compute the average turnaround time.
(1) FCFS scheduling
Instructor Solution (part 1)

Gantt Chart(s) visualization
┌──────────T1──────────┬──────────T2──────────┬──────────T3──────────┬T1┐0 7 13 21 23Elaboration (by LLM)
Dependency Map
| Semaphore / Lock | Producer | Consumer | Meaning |
|---|---|---|---|
mutex | T1 (unlock after Compute 3) | T3 (lock at start) | T3’s first compute depends on T1 releasing the mutex |
sem1 | T1 (signal after unlock) | T2 (wait after Compute 1) | T2’s second burst waits for T1 to finish its mutex section |
sem2 | T2 (signal after Compute 3) | T3 (wait after mutex section) | T3’s second burst waits for T2 |
sem3 | T3 (signal after Compute 3) | T1 (wait before last Compute 2) | T1’s final burst waits for T3 |
FCFS Rules
Threads run in arrival order. Since all arrive at T=0, the order is T1 → T2 → T3 (arrival order within ties). A thread runs until it blocks on a semaphore or lock, at which point the next thread in FCFS order runs.
Step-by-Step Trace
| Interval | Running | Event at end | Blocked threads |
|---|---|---|---|
| 0–2 | T1 | Finishes Compute(2), hits lock(mutex) → S=1, acquires it | — |
| 2–5 | T1 | Finishes Compute(3), unlock(mutex), signal(sem1) | — |
| 5–7 | T1 | Finishes Compute(2), hits wait(sem3)=0 → blocks | T1 |
| 7–7 | T2 | Next in FCFS. Finishes Compute(1), hits wait(sem1). sem1=1→0, proceeds | — |
| 7–10 | T2 | Finishes Compute(3), signal(sem2) (sem2→1) | — |
| 10–12 | T2 | Finishes Compute(2). T2 done. Turnaround = 12. | — |
| 12–12 | T3 | Next in FCFS. Hits lock(mutex) → mutex is free, acquires | — |
| 12–15 | T3 | Finishes Compute(3), unlock(mutex), hits wait(sem2). sem2=1→0, proceeds | — |
| 15–18 | T3 | Finishes Compute(3), signal(sem3) (sem3→1). T1 unblocked. | T1 unblocked |
| 18–20 | T3 | Finishes Compute(2). T3 done. Turnaround = 20. | — |
| 20–22 | T1 | Resumes, finishes Compute(2). T1 done. Turnaround = 22. | — |
Turnaround Times (from first-principles trace)
| Thread | Finish time | Turnaround |
|---|---|---|
| T2 | 12 | 12 |
| T3 | 20 | 20 |
| T1 | 22 | 22 |
| Average | (12 + 20 + 22) / 3 = 18 |
(2) Non-preemptive priority scheduling
Instructor Solution (part 2)

Gantt Chart(s) visualization
┌───T3───┬T2┬────────────T1────────────┬─────T2─────┬─────T3─────┬T1┐0 3 4 11 16 21 23Elaboration (by LLM)
Non-Preemptive Priority Rules
At T=0, all threads are ready. The scheduler picks the highest-priority ready thread. Once running, a thread continues until it voluntarily blocks (hits a wait or lock that cannot be immediately satisfied). The next highest-priority ready thread is then selected.
Step-by-Step Trace
| Interval | Running | Event at end | Why blocked / next choice |
|---|---|---|---|
| 0–0 | T3 (highest P) | Hits lock(mutex) → free, acquires | — |
| 0–3 | T3 | Finishes Compute(3), unlock(mutex), hits wait(sem2)=0 → blocks | T2 next (higher P than T1) |
| 3–4 | T2 | Finishes Compute(1), hits wait(sem1)=0 → blocks | T1 only remaining |
| 4–4 | T1 | Hits lock(mutex) → free (T3 released it), acquires | — |
| 4–7 | T1 | Finishes Compute(3), unlock(mutex), signal(sem1) (sem1→1) → T2 unblocked | T2 > T1, but non-preemptive: T1 continues |
| 7–9 | T1 | Finishes Compute(2), hits wait(sem3)=0 → blocks | T2 now runs |
| 9–12 | T2 | Finishes Compute(3), signal(sem2) (sem2→1) → T3 unblocked | T2 continues (non-preemptive) |
| 12–14 | T2 | Finishes Compute(2). T2 done. Turnaround = 14. | T3 next (P > T1) |
| 14–17 | T3 | Finishes Compute(3), signal(sem3) (sem3→1) → T1 unblocked | T3 continues |
| 17–19 | T3 | Finishes Compute(2). T3 done. Turnaround = 19. | T1 runs |
| 19–21 | T1 | Finishes Compute(2). T1 done. Turnaround = 21. | — |
Gantt Chart
┌───T3───┬─T2─┬────────────T1────────────┬─────T2─────┬─────T3─────┬──T1──┐0 3 4 9 14 19 21Turnaround Times
| Thread | Finish time | Turnaround |
|---|---|---|
| T2 | 14 | 14 |
| T3 | 19 | 19 |
| T1 | 21 | 21 |
| Average | (14 + 19 + 21) / 3 ≈ 18 |
(3) Preemptive priority scheduling
Instructor Solution (part 3)

Gantt Chart(s) visualization
┌───T3───┬T2┬─────────T1─────────┬───T2───┬─────T3─────┬─T2─┬────T1────┐0 3 4 9 12 17 19 23Elaboration (by LLM)
Preemptive Priority Rules
The highest-priority ready thread always runs. Any time a higher-priority thread becomes unblocked (e.g., a semaphore is signaled), it immediately preempts the currently running thread — even mid-burst.
Step-by-Step Trace
| Interval | Running | Event | Preempt? |
|---|---|---|---|
| 0–0 | T3 | lock(mutex) → free, acquired. Begins Compute(3). | — |
| 0–3 | T3 | Finishes Compute(3), unlock(mutex), hits wait(sem2)=0 → blocks | — |
| 3–4 | T2 | Finishes Compute(1), hits wait(sem1)=0 → blocks | — |
| 4–4 | T1 | lock(mutex) → free, acquired. Begins Compute(3). | — |
| 4–7 | T1 | Finishes Compute(3), unlock(mutex), signal(sem1) → T2 unblocked | T2 preempts T1 (T2 P > T1 P) |
| 7–10 | T2 | Finishes Compute(3), signal(sem2) → T3 unblocked | T3 preempts T2 (T3 P > T2 P) |
| 10–13 | T3 | Finishes Compute(3), signal(sem3) → T1 unblocked. | T3 continues (higher P than T2) |
| 13–15 | T3 | Finishes Compute(2). T3 done. Turnaround = 15. | — |
| 15–17 | T2 | Finishes remaining Compute(2). T2 done. Turnaround = 17. | — |
| 17–17 | T1 | Resumes Compute(2) (was preempted at T=7 mid-run, had done 3 of 5 total units). | — |
| 17–19 | T1 | Finishes Compute(2) (the second Compute 2). T1 done. Turnaround = 19. | — |
Gantt Chart
┌───T3───┬─T2─┬─────T1─────┬───T2───┬─────T3─────┬──T2──┬────T1────┐0 3 4 7 10 13 15 19Turnaround Times
| Thread | Finish time | Turnaround |
|---|---|---|
| T3 | 15 | 15 |
| T2 | 17 | 17 |
| T1 | 19 | 19 |
| Average | (15 + 17 + 19) / 3 ≈ 17 |
Priority Inversion in This Problem
Notice that T1 (lowest priority) holds mutex during T=4–7. T3 (highest priority) needed mutex at T=0 and got it first, but if T3 had arrived after T1 had already locked the mutex, T3 would have experienced priority inversion — blocked by T1. This is the exact scenario from Problems 13–16.
(4) Round Robin (RR) scheduling with quanta = 4
Instructor Solution (part 4)

Gantt Chart(s) visualization
┌────────T1────────┬T2┬────────T1────────┬───T3───┬────T2────┬────T3────┬─T2─┬T1┐0 4 5 8 11 15 19 21 23Elaboration (by LLM)
Round Robin Rules
Each thread gets at most 4 time units before being preempted and placed at the back of the ready queue. Blocking on a lock or semaphore removes the thread from the queue immediately (it does not use its remaining quantum while blocked). All threads arrive at T=0; initial queue order (arrival): [T1, T2, T3].
Step-by-Step Trace
| Interval | Running | Quantum used | Event at end | Queue after | Semaphore changes |
|---|---|---|---|---|---|
| 0–4 | T1 | 4/4 | Quantum expires. T1 is mid-Compute(2) then into lock(mutex) region. Has used 4 of its 7 units total before first block. | [T2, T3, T1] | — |
| 4–5 | T2 | 1/4 | Compute(1) done, hits wait(sem1)=0 → blocks | [T3, T1] | — |
| 5–8 | T1 | 3/4 remaining from prior quantum resumed… actually fresh quantum. T1 continues: finishes Compute(2), acquires lock(mutex), starts Compute(3). Uses 3 units, quantum expires. | [T3, T1] | — | |
| 8–11 | T3 | 3/4 | lock(mutex) → held by T1, blocks immediately | [T1] | — |
| 11–11 | T1 | resumes | Finishes remaining Compute(3) (1 unit), unlock(mutex). T3 unblocked → joins queue. signal(sem1). T2 unblocked → joins queue. | [T3, T2, T1] | sem1: 0→1→0; mutex free |
| 11–15 | T3 (highest P… but RR ignores priority) | 4/4 | Compute(3) runs 3 units… wait: under pure RR there is no priority. T3 is at front of queue. Compute(3) = 3 units, then wait(sem2)=0 → blocks at T=14. | [T2, T1] | — |
| 14–18 | T2 | 4/4 | Compute(3) runs, signal(sem2) at T=17. T3 unblocked. Quantum expires at T=18. | [T1, T3, T2] | sem2: 0→1→0 |
| 18–22 | T1 | 4/4 | Compute(2) runs (2 units, done T=20), hits wait(sem3)=0 → blocks at T=20. | [T3, T2] | — |
| 20–23 | T3 | 3/4 | Compute(3) runs (3 units), signal(sem3) at T=23. T1 unblocked. | [T2, T1, T3] | sem3: 0→1→0 |
| 23–25 | T2 | 2/4 | Finishes Compute(2). T2 done. Turnaround = 25. | [T1, T3] | — |
| 25–27 | T1 | 2/4 | Finishes Compute(2). T1 done. Turnaround = 27. | [T3] | — |
| 27–29 | T3 | 2/4 | Finishes Compute(2). T3 done. Turnaround = 29. | [] | — |
Turnaround Comparison Across All Algorithms
| Algorithm | T1 finish | T2 finish | T3 finish | Avg turnaround |
|---|---|---|---|---|
| FCFS | 22 | 12 | 20 | 18.0 |
| Non-preemptive priority | 21 | 14 | 19 | 18.0 |
| Preemptive priority | 19 | 17 | 15 | 17.0 |
| Round Robin (q=4) | ~27 | ~25 | ~29 | ~27.0 |
Round Robin has the worst average turnaround time here because it interleaves all threads indiscriminately — threads that could complete quickly are repeatedly interrupted. Preemptive priority performs best because it immediately promotes high-priority threads when they become unblocked, minimizing waiting.
Problem 28: Implementing Counting Semaphores with Binary Semaphores
Section titled “Problem 28: Implementing Counting Semaphores with Binary Semaphores”Given binary semaphores, describe how you would implement counting semaphores using binary semaphores. Assume you are given P(BinarySemaphore), V(BinarySemaphore) operations, and you are asked to implement P(CountingSemaphore) and V(CountingSemaphore).
Instructor Solution
sem_t S1 = 1; // A binary semaphore to protect countsem_t S2 = 0; // A binary semaphore to sleep on in case we are not able to proceedint count = N; // Initial value of the counting semaphore
P(CountingSemaphore): P(S1); count--; if (count < 0) { V(S1); // Release the mutex binary semaphore P(S2); // Sleep on S2 } else { V(S1); // Release the mutex binary semaphore }
V(CountingSemaphore): P(S1); count++; if (count <= 0) V(S2); // Wake up one sleeping process V(S1);Elaboration (by LLM)
Why This Is Non-Trivial
A counting semaphore allows its internal value to range over any non-negative integer, while a binary semaphore is restricted to 0 or 1. The challenge is simulating an arbitrary integer counter using only 0/1 signals, without a race condition on the counter itself.
The solution uses two binary semaphores with distinct roles:
| Variable | Type | Initial | Role |
|---|---|---|---|
S1 | Binary semaphore | 1 | Mutex — protects count from concurrent modification |
S2 | Binary semaphore | 0 | Sleeping point — threads that cannot proceed block here |
count | Integer | N | Tracks the counting semaphore’s logical value (may go negative) |
The Meaning of a Negative count
Unlike a standard counting semaphore (which bottoms out at 0), count here is allowed to go negative. The magnitude of a negative count encodes the number of threads currently sleeping on S2:
count = 3 → 3 resources available, no one waitingcount = 0 → no resources available, no one waitingcount = -1 → no resources available, 1 thread sleeping on S2count = -2 → no resources available, 2 threads sleeping on S2This is why V checks if (count <= 0) before posting S2: if count was negative before the increment, there is still at least one sleeper to wake.
Annotated P (wait/down)
P(CountingSemaphore): P(S1); // Acquire mutex — enter critical section count--; // Decrement: claim one resource (or record that we're waiting) if (count < 0) { V(S1); // Release mutex BEFORE sleeping (avoid deadlock) P(S2); // Sleep here until a V() wakes us } else { V(S1); // Resource was available — release mutex and proceed }The critical ordering: release S1 before sleeping on S2. If S1 were held while sleeping, no other thread could enter V() (which also needs S1) to post S2 — an immediate deadlock.
Annotated V (signal/up)
V(CountingSemaphore): P(S1); // Acquire mutex count++; // Return one resource (or record that one sleeper can wake) if (count <= 0) V(S2); // count was ≤ -1 before increment → someone is sleeping → wake them V(S1); // Release mutexExecution Trace: N=2, Three Threads
Initial: count=2, S1=1, S2=0
Thread A calls P(): count→1 (≥0, no sleep). Proceeds.Thread B calls P(): count→0 (≥0, no sleep). Proceeds.Thread C calls P(): count→-1 (<0, sleeps on S2). Waiting.
Thread A calls V(): count→0 (was -1 ≤ 0, post S2). Thread C wakes.Thread C resumes from P(S2). Proceeds.
Thread B calls V(): count→1 (was 0, NOT ≤ 0, no post). No one to wake.Thread A calls V(): count→2 (no post). Back to initial state.Why count <= 0 in V (not count < 0)
After count++, if the result is <= 0, the count was <= -1 before the increment — meaning at least one thread is sleeping. Posting S2 wakes exactly one of them. If the result is > 0, the count was >= 0 before — no one is sleeping, so no post needed.
Problem 29: Code Output Analysis 1
Section titled “Problem 29: Code Output Analysis 1”What’s the output of the following code fragment?
sem_t s1 = 0;sem_t s2 = 1;sem_t s3 = 0;int g = 10;
T1() { wait(s1); printf("T1 is here.\n"); wait(s2); g = g + 10; signal(s2); signal(s3);}
T2() { g = 0; signal(s1); wait(s3); wait(s2); g = g * 2; signal(s2); printf("T2 is here.\n");}
main() { int tid1 = CreateThread(T1); int tid2 = CreateThread(T2); JoinThread(tid1); JoinThread(tid2); printf("g: %d\n", g);}Instructor Solution
T1 is here.T2 is here.g: 20Elaboration (by LLM)
Semaphore Roles
| Semaphore | Initial | Role |
|---|---|---|
s1 | 0 | T2 signals T1 to start (T1 must wait for T2 to set g=0) |
s2 | 1 | Mutex protecting g (binary semaphore, initial=1 = unlocked) |
s3 | 0 | T1 signals T2 that g+10 is done (T2 must wait for T1’s write) |
Enforced Execution Order
The semaphores create a strict ordering regardless of how the OS schedules T1 and T2:
T2: g=0 → signal(s1) → [T1 unblocked]T1: g=g+10=10 → signal(s3) → [T2 unblocked]T2: g=g*2=20Step-by-Step Trace
Both threads are created and may start in any order. The semaphores enforce the correct sequencing:
T1 starts, hits wait(s1): s1=0 → BLOCKS immediately.
T2 starts: g = 0 → g is now 0 signal(s1) → s1: 0→1, T1 unblocked wait(s3) → s3=0, T2 BLOCKS
T1 resumes: printf("T1 is here.\n") ← first output wait(s2) → s2=1→0, acquired (non-blocking) g = g + 10 → g = 0 + 10 = 10 signal(s2) → s2: 0→1 signal(s3) → s3: 0→1, T2 unblocked
T2 resumes: wait(s2) → s2=1→0, acquired g = g * 2 → g = 10 * 2 = 20 signal(s2) → s2: 0→1 printf("T2 is here.\n") ← second output
main (after both JoinThread calls): printf("g: %d\n", g) → g: 20Why g Is Deterministically 20
The key is that s3 forces T2’s multiply to happen after T1’s addition. Without s3, T2 might multiply before T1 adds, giving g = 0 * 2 = 0 then g = 0 + 10 = 10 — wrong. The semaphore chain s1 → s3 creates a total order:
T2 sets g=0 → T1 adds 10 (g=10) → T2 multiplies by 2 (g=20)Could the Output Order Ever Differ?
No — s1 guarantees T1’s print happens after T2’s g=0 and signal(s1), and s3 guarantees T2’s print happens after T1’s signal(s3). The print order is deterministic: T1 always prints before T2.
Problem 30: Code Output Analysis 2
Section titled “Problem 30: Code Output Analysis 2”What’s the output of the following code fragment?
sem_t s1 = 1;sem_t s2 = 0;int g = 10;int count = 0;
T1() { wait(s1); g = g + 10; count++; printf("T1 is here. count: %d\n", count); signal(s1); if (count == 2) signal(s2);}
T2() { wait(s2); g = g * 2; printf("T2 is here.\n");}
main() { int tid1 = CreateThread(T2); int tid2 = CreateThread(T1); int tid3 = CreateThread(T1); JoinThread(tid1); JoinThread(tid2); JoinThread(tid3); printf("g: %d\n", g);}Instructor Solution
T1 is here. count: 1T1 is here. count: 2T2 is here.g: 60Elaboration (by LLM)
Semaphore Roles
| Semaphore | Initial | Role |
|---|---|---|
s1 | 1 | Mutex protecting g and count — only one T1 instance runs its critical section at a time |
s2 | 0 | Gate — T2 waits here until both T1 instances have finished |
Key Insight: count Tracks T1 Completions
Two T1 threads are created (tid2 and tid3). Each increments count inside the s1-protected critical section. The second T1 to finish will see count == 2 and signals s2, releasing T2.
Step-by-Step Trace
T2 is created first (tid1) but immediately blocks on wait(s2)=0. The two T1 threads compete for s1:
T2: wait(s2) → s2=0, BLOCKS immediately.
[First T1 instance wins s1]: wait(s1): s1=1→0 g = 10 + 10 = 20 count = 0 + 1 = 1 printf("T1 is here. count: 1\n") ← first output signal(s1): s1=0→1 count == 2? No → no signal
[Second T1 instance acquires s1]: wait(s1): s1=1→0 g = 20 + 10 = 30 count = 1 + 1 = 2 printf("T1 is here. count: 2\n") ← second output signal(s1): s1=0→1 count == 2? YES → signal(s2): s2=0→1
T2 resumes: g = 30 * 2 = 60 printf("T2 is here.\n") ← third output
main (after all JoinThreads): printf("g: %d\n", g) → g: 60Is the Output Fully Deterministic?
Almost — but there is one subtlety. s1 guarantees mutual exclusion between the two T1 instances, so their critical sections don’t interleave, and count is correctly 1 then 2. s2 guarantees T2 runs after both T1s. However, the order in which the two T1 instances acquire s1 is not guaranteed — either could go first. This means:
- The line
T1 is here. count: 1always appears beforeT1 is here. count: 2✅ - But which physical T1 thread (tid2 or tid3) prints which line is non-deterministic — it doesn’t matter, since both run identical code
The final value of g is always (10 + 10 + 10) * 2 = 60 regardless of T1 order, because the multiply always happens last.
count == 2 Check Is Outside the Lock — Is That Safe?
signal(s1); // release lockif (count == 2) // read count WITHOUT holding s1 signal(s2);This read of count happens after signal(s1), so it is technically outside the mutex. However, it is safe here because:
- Only T1 threads write
count, and each T1 only writes it once (inside the lock) - Once the second T1 exits the lock with
count=2, no other thread will ever writecountagain - The check
count == 2is done by the same thread that just wrote it — so it sees its own write reliably
A stricter design would read count before releasing s1 and store it in a local variable. But the solution works correctly as written.
Problem 31: Thread-Safe Queue Monitor
Section titled “Problem 31: Thread-Safe Queue Monitor”Fill in the details of the following Monitor that implements a thread-safe Queue using a monitor with the following constraints: When you want to “add” an item and the queue is full, you must wait until an empty slot becomes available. When you want to “remove” item and the queue is empty, you must wait until a slot becomes full.
Instructor Solution
Monitor Queue { int front = 0; // Initializations int rear = 0; int Q[10]; // At most 10 items int numItems = 0; // # of items in the queue condition not_full; condition not_empty;
// Insert an element to the rear of the Queue void add(int item) { while (numItems == N) wait(not_full); // numItems < N numItems++; Q[rear] = item; rear = (rear + 1) % N; signal(not_empty); // Wake up any sleeping consumer } // end-add
// Remove an element from the front of the Queue int remove() { while (numItems == 0) wait(not_empty); // Q is empty. Wait until an item is enqueued // numItems > 0 numItems--; int item = Q[front]; front = (front + 1) % N; signal(not_full); // Signal a sleeping producer return item; } // end-remove}; // end-MonitorElaboration (by LLM)
What the Monitor Gives You for Free
A monitor automatically ensures that only one thread executes inside it at any time — the mutex is implicit. You do not need to call lock/unlock manually. The two condition variables handle the cases where a thread needs to wait inside the monitor without holding up everyone else:
not_full— producers sleep here when the queue is at capacitynot_empty— consumers sleep here when the queue is empty
The Circular Buffer
The queue is implemented as a circular (ring) buffer of size N=10, using modular arithmetic to wrap front and rear around:
Initial: front=0, rear=0, numItems=0
After add(A): Q=[A, _, _, ...], front=0, rear=1, numItems=1After add(B): Q=[A, B, _, ...], front=0, rear=2, numItems=2After remove(): returns A, front=1, rear=2, numItems=1After add(C): Q=[A, B, C, ...], front=1, rear=3, numItems=2 ↑ slot 0 is now "free" and will be reused when rear wraps aroundThe modular update rear = (rear + 1) % N ensures that after slot N-1, rear wraps back to 0, reusing freed slots without shifting elements.
Annotated add
void add(int item) { while (numItems == N) // Queue is full — must wait wait(not_full); // Sleep; releases monitor lock atomically // Guaranteed: numItems < N here numItems++; Q[rear] = item; // Place item at the rear rear = (rear + 1) % N; // Advance rear (wraps around) signal(not_empty); // Wake one sleeping consumer (if any)}Annotated remove
int remove() { while (numItems == 0) // Queue is empty — must wait wait(not_empty); // Sleep; releases monitor lock atomically // Guaranteed: numItems > 0 here numItems--; int item = Q[front]; // Read item from front front = (front + 1) % N; // Advance front (wraps around) signal(not_full); // Wake one sleeping producer (if any) return item;}Why while and Not if
Both methods use while loops to recheck the condition after waking:
- Multiple threads may be waiting on the same condition variable
- After a
signal, only one waiter is woken — but by the time it reacquires the monitor lock, another thread may have already consumed the item or filled the slot - The
whilere-validates the condition before proceeding, ensuring correctness in all cases
signal vs. broadcast Choice
The solution uses signal (wake one) rather than broadcast (wake all). This is correct and more efficient here:
- Each
addproduces exactly one new item → at most one consumer can benefit →signal(not_empty)is sufficient - Each
removefrees exactly one slot → at most one producer can proceed →signal(not_full)is sufficient
Using broadcast would be safe but wasteful: all sleeping threads would wake, re-check the while condition, and all but one would go back to sleep.
State Diagram
add() called │ ┌──────────▼──────────┐ │ numItems == N? │ │ YES → wait(not_full)│◄─── woken by remove()'s signal(not_full) │ NO → insert item │ │ signal(not_empty) │ └─────────────────────┘
remove() called │ ┌──────────▼──────────┐ │ numItems == 0? │ │ YES → wait(not_empty)│◄── woken by add()'s signal(not_empty) │ NO → extract item │ │ signal(not_full) │ └─────────────────────┘Problem 32: Adders and Subtractors Monitor
Section titled “Problem 32: Adders and Subtractors Monitor”Consider a global variable “g” with initial value 0, that is manipulated by multiple threads. There are two types of threads: Adders and Subtractors. The threads obey the following rules:
(1) An Adder arrives and sees the value of “g” to be less than 5, it simply increments the value of “g” by one and leaves.
(2) An Adder arrives and sees the value of “g” to be equal to 5, it waits until the value of “g” drops below 5.
(3) A Subtractor arrives and sees the value of “g” to be greater than 0, it simply decrements the value of “g” by one and leaves.
(4) A Subtractor arrives and sees the value of “g” to be equal to 0, it waits until the value of “g” goes above 0.
You are asked to implement this synchronization problem using a monitor. Your monitor must have two methods, Add and Subtract, called by Adders and Subtractors respectively.
(a) Implement the above monitor in Java.
Instructor Solution (part a)
class Monitor { private int g = 0;
public synchronized void Add() { while (g == 5) wait(); g++; notifyAll(); }
public synchronized void Subtract() { while (g == 0) wait(); g--; notifyAll(); }}Elaboration (by LLM)
Java Monitor Mechanics
Java’s synchronized keyword turns a method into a monitor procedure — only one thread may execute any synchronized method on the same object at a time. The object’s intrinsic lock (monitor lock) is acquired on entry and released on exit.
wait() and notifyAll() are methods on Object (inherited by every class) and must be called while holding the object’s lock (i.e., inside a synchronized method):
| Java call | Equivalent concept |
|---|---|
synchronized void M() | Monitor procedure (implicit lock/unlock) |
wait() | Release monitor lock, sleep on the object’s condition queue |
notify() | Wake one thread sleeping on this object’s condition queue |
notifyAll() | Wake all threads sleeping on this object’s condition queue |
Annotated Java Solution
class Monitor { private int g = 0; // Shared variable; only accessible through Add/Subtract
public synchronized void Add() { while (g == 5) // g is at maximum — must wait wait(); // releases lock, sleeps; re-acquires lock on wake g++; // safe to increment: g < 5 guaranteed notifyAll(); // a Subtractor may now be able to proceed (g > 0) }
public synchronized void Subtract() { while (g == 0) // g is at minimum — must wait wait(); // releases lock, sleeps; re-acquires lock on wake g--; // safe to decrement: g > 0 guaranteed notifyAll(); // an Adder may now be able to proceed (g < 5) }}Why notifyAll() Instead of notify()
Java’s wait()/notify() use a single condition queue per object. Both Adders and Subtractors sleep on the same queue. If notify() (wake one) is used:
- After
Add()incrementsg, we want to wake a Subtractor — butnotify()might wake another Adder instead, which re-checksg == 5, findsg < 5, and proceeds. No harm, but the Subtractor remains sleeping unnecessarily. - More critically: if all waiting threads are of the wrong type,
notify()wastes a wakeup and the correct waiter remains blocked indefinitely — livelock or starvation.
notifyAll() wakes everyone; each thread re-checks its own while condition and either proceeds or goes back to sleep. This is safe and correct, at the cost of some extra wakeups.
Contrast with Part (b)
The C++ solution (part b) uses two separate condition variables (addCond, subCond), allowing it to use signal (wake one) precisely — an Add only wakes a Subtractor, and vice versa. Java’s single-queue model forces notifyAll() to avoid the wrong-wakeup problem.
(b) Implement the above monitor in C++ using POSIX mutexes and condition variables.
Instructor Solution (part b)
class Monitor { int g = 0; pthread_mutex_t mutex; pthread_cond_t addCond; // This is where Adders sleep pthread_cond_t subCond; // This is where Subtractors sleep
public: void Add() { pthread_mutex_lock(&mutex); while (g == 5) pthread_cond_wait(&addCond, &mutex); g++; pthread_cond_signal(&subCond); // Wakeup a Subtractor pthread_mutex_unlock(&mutex); }
void Subtract() { pthread_mutex_lock(&mutex); while (g == 0) pthread_cond_wait(&subCond, &mutex); g--; pthread_cond_signal(&addCond); // Wakeup an Adder pthread_mutex_unlock(&mutex); }};Elaboration (by LLM)
Two Condition Variables: Precise Wakeup
The key improvement over the Java solution is the use of two separate condition variables — one for each type of waiter:
| Condition variable | Who sleeps here | Who signals it |
|---|---|---|
addCond | Adders waiting for g < 5 | Subtract() — after decrementing, g may now be < 5 |
subCond | Subtractors waiting for g > 0 | Add() — after incrementing, g is now > 0 |
This separation allows pthread_cond_signal (wake exactly one) to be used safely: an Add call can only wake a Subtractor, never another Adder by mistake.
Annotated C++ Solution
class Monitor { int g = 0; pthread_mutex_t mutex; pthread_cond_t addCond; // Adders sleep here when g == 5 pthread_cond_t subCond; // Subtractors sleep here when g == 0
public: void Add() { pthread_mutex_lock(&mutex); while (g == 5) // g at max — wait pthread_cond_wait(&addCond, &mutex); // sleep on addCond, release mutex g++; // g < 5 guaranteed here pthread_cond_signal(&subCond); // g is now > 0 — wake one Subtractor pthread_mutex_unlock(&mutex); }
void Subtract() { pthread_mutex_lock(&mutex); while (g == 0) // g at min — wait pthread_cond_wait(&subCond, &mutex); // sleep on subCond, release mutex g--; // g > 0 guaranteed here pthread_cond_signal(&addCond); // g is now < 5 — wake one Adder pthread_mutex_unlock(&mutex); }};Interaction Diagram
Adder arrives, g=5: lock → while(g==5) → wait(addCond) → releases lock, sleeps
Subtractor arrives, g=5: lock → while(g==0)? NO → g-- (g=4) → signal(addCond) → unlock ↓ Sleeping Adder wakes, reacquires lock while(g==5)? NO (g=4) → g++ (g=5) signal(subCond) → unlockJava vs. C++ Comparison
| Feature | Java (synchronized) | C++ (POSIX) |
|---|---|---|
| Mutual exclusion | Implicit (synchronized) | Explicit (pthread_mutex_lock/unlock) |
| Condition variables | Single queue (wait/notifyAll) | Two queues (addCond, subCond) |
| Wakeup strategy | notifyAll (all waiters) | signal (one targeted waiter) |
| Wrong-type wakeups | Possible (handled by while recheck) | Impossible (separate CVs) |
| Code verbosity | Less | More |
| Wakeup efficiency | Lower (more spurious wakeups) | Higher (only the right type wakes) |
Problem 33: Bounded Critical Section Access
Section titled “Problem 33: Bounded Critical Section Access”Consider the following synchronization problem: Multiple threads want to enter a critical section (CS), but at most 5 of them can be inside of a CS at the same time. If a 6th thread arrives and wants to enter the CS, you must block the newly arriving thread until somebody leaves the CS. You are asked to solve this problem using one of the schemes below:
(a) Using ONLY mutex locks and POSIX binary semaphores
Instructor Solution (part a)
int semVal = 5;pthread_mutex_t mutex; // For mutually exclusive access to semValsem_t sem = 0; // To have waiting threads sleep on
pthread_mutex_lock(&mutex);semVal--;if (semVal < 0) { pthread_mutex_unlock(&mutex); sem_wait(&sem);} else { pthread_mutex_unlock(&mutex);}
// <Critical Section>
pthread_mutex_lock(&mutex);semVal++;if (semVal <= 0) { sem_post(&sem); // Let a waiting thread in}pthread_mutex_unlock(&mutex);Elaboration (by LLM)
What This Is
This is a direct re-implementation of a counting semaphore using a binary semaphore — the same pattern from Problem 28, applied to a concrete limit of 5. The counting semaphore’s value is tracked manually in semVal, protected by a mutex, while the binary semaphore sem serves as the sleeping point for threads that cannot enter.
Variable Roles
| Variable | Role |
|---|---|
semVal | Logical counting semaphore value. Starts at 5 (capacity). Goes negative to record waiting thread count. |
mutex | Protects semVal from concurrent modification. |
sem | Binary semaphore. Threads that cannot enter sleep here; exiting threads wake them. |
Annotated Entry
pthread_mutex_lock(&mutex);semVal--; // Claim one slot (or record that we're waiting)if (semVal < 0) { pthread_mutex_unlock(&mutex); // Release mutex BEFORE sleeping sem_wait(&sem); // Sleep until an exiting thread wakes us} else { pthread_mutex_unlock(&mutex); // Slot was available — proceed directly}// <Critical Section>Annotated Exit
pthread_mutex_lock(&mutex);semVal++; // Return the slot (or record one fewer waiter)if (semVal <= 0) sem_post(&sem); // semVal was ≤ -1 before → someone is sleeping → wake thempthread_mutex_unlock(&mutex);semVal State Interpretation
semVal | Meaning |
|---|---|
| 5 | All slots free, no one inside |
| 3 | 2 threads inside, 3 slots remaining |
| 0 | 5 threads inside, no slots remaining, no one waiting |
| -2 | 5 threads inside, 2 threads sleeping on sem |
The entry condition semVal < 0 (after decrement) means: “I decremented past zero — all slots were taken before I arrived, so I must sleep.” The exit condition semVal <= 0 (before increment, equivalently after semVal++ the result is ≤ 0) means: “a waiter exists — wake one.”
(b) Using ONLY POSIX counting semaphores
Instructor Solution (part b)
sem_t sem = 5;
sem_wait(&sem);
// <Critical Section>
sem_post(&sem);Elaboration (by LLM)
Why This Works
A POSIX counting semaphore initialized to 5 directly encodes the available capacity. sem_wait decrements the count atomically; if the result would go below 0, the calling thread is blocked. sem_post increments the count and wakes one blocked thread if any exist.
Thread 1: sem_wait → sem=4, enters CSThread 2: sem_wait → sem=3, enters CSThread 3: sem_wait → sem=2, enters CSThread 4: sem_wait → sem=1, enters CSThread 5: sem_wait → sem=0, enters CSThread 6: sem_wait → sem would be -1 → BLOCKSThread 1: sem_post → sem=1, Thread 6 unblocked → enters CSComparison to Parts (a) and (c)
| Approach | Lines of synchronization code | Primitives needed |
|---|---|---|
| (a) Mutex + binary semaphore | ~10 | 2 primitives + integer |
| (b) Counting semaphore | 3 | 1 primitive |
| (c) Mutex + condition variable | ~10 | 2 primitives + integer |
Part (b) is the most concise because a counting semaphore is precisely the right abstraction for this problem — limiting concurrent access to a bounded resource. Parts (a) and (c) are instructive as they show how to build that abstraction from lower-level primitives.
(c) Using ONLY POSIX locks and condition variables
Instructor Solution (part c)
class Monitor { int numThreads = 0; pthread_mutex_t mutex; pthread_cond_t cond;
public: void CS() { pthread_mutex_lock(&mutex); while (numThreads == 5) pthread_cond_wait(&cond, &mutex); numThreads++; pthread_mutex_unlock(&mutex);
// <Critical Section>
pthread_mutex_lock(&mutex); numThreads--; pthread_cond_signal(&cond); pthread_mutex_unlock(&mutex); }};Elaboration (by LLM)
Design
The monitor tracks numThreads — the number of threads currently inside the CS. Entry is gated by a while loop: if already at capacity (5), the thread sleeps on cond. On exit, the count is decremented and one sleeping thread is woken.
Annotated Code
void CS() { // --- Entry --- pthread_mutex_lock(&mutex); while (numThreads == 5) // At capacity — must wait pthread_cond_wait(&cond, &mutex); // Sleep, release mutex atomically numThreads++; // Slot claimed pthread_mutex_unlock(&mutex); // Release before entering CS
// <Critical Section>
// --- Exit --- pthread_mutex_lock(&mutex); numThreads--; // Return slot pthread_cond_signal(&cond); // Wake one waiting thread (if any) pthread_mutex_unlock(&mutex);}Why signal (not broadcast) Is Correct Here
Each exit frees exactly one slot, so at most one waiting thread can proceed. pthread_cond_signal wakes exactly one waiter — the right match. Using broadcast would wake all waiters, each of which re-checks while (numThreads == 5). All but one would find the condition still true (numThreads back at 5) and go back to sleep — correct but wasteful.
Why the Mutex Is Released Before the CS
After incrementing numThreads and before entering the CS, the mutex is released. This is essential: if the mutex were held across the CS, only one thread could be inside the CS at any time — defeating the purpose of allowing up to 5. The mutex is only needed to protect numThreads itself, not the CS work.
Problem 34: LeetCode 1114 - Print in Order
Section titled “Problem 34: LeetCode 1114 - Print in Order”LeetCode 1114 - Print in Order
Instructor Solution (using two binary semaphores)
class Foo { sem_t sem2; sem_t sem3;public: Foo() { sem_init(&sem2, 0, 0); sem_init(&sem3, 0, 0); }
void first(function<void()> printFirst) { printFirst(); sem_post(&sem2); }
void second(function<void()> printSecond) { sem_wait(&sem2); printSecond(); sem_post(&sem3); }
void third(function<void()> printThird) { sem_wait(&sem3); printThird(); }};Elaboration (by LLM)
Problem Summary
Three threads call first(), second(), and third() in an arbitrary order. The output must always be firstsecondthird — i.e., the methods must execute in order regardless of thread scheduling.
The Semaphore Chain
Two binary semaphores act as “gates” between consecutive methods:
first() ──► sem_post(sem2) ──► second() ──► sem_post(sem3) ──► third() (opens gate 2) (opens gate 3)Each semaphore starts at 0 (closed). A method can only pass through its gate after the previous method has posted it open:
sem2 = 0: second() blocks at sem_wait(sem2) until first() posts itsem3 = 0: third() blocks at sem_wait(sem3) until second() posts itWhy No Semaphore for first()
first() has no predecessor — it can always execute immediately. There is nothing to wait for before printing the first item.
Execution Trace (worst-case arrival order: third, second, first)
third() arrives: sem_wait(sem3) → sem3=0, BLOCKSsecond() arrives: sem_wait(sem2) → sem2=0, BLOCKSfirst() arrives: printFirst() → sem_post(sem2) → sem2: 0→1
second() unblocked: printSecond() → sem_post(sem3) → sem3: 0→1third() unblocked: printThird()Output is always firstsecondthird ✅ regardless of arrival order.
Instructor Solution (using a mutex & two condition variables)
class Foo { pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; pthread_cond_t cond2 = PTHREAD_COND_INITIALIZER; pthread_cond_t cond3 = PTHREAD_COND_INITIALIZER; int turn = 1;public: Foo() {}
void first(function<void()> printFirst) { printFirst(); turn = 2; pthread_cond_signal(&cond2); }
void second(function<void()> printSecond) { pthread_mutex_lock(&mutex); while (turn != 2) pthread_cond_wait(&cond2, &mutex); printSecond(); turn = 3; pthread_cond_signal(&cond3); pthread_mutex_unlock(&mutex); }
void third(function<void()> printThird) { pthread_mutex_lock(&mutex); while (turn != 3) pthread_cond_wait(&cond3, &mutex); printThird(); turn = 4; pthread_mutex_unlock(&mutex); }};Elaboration (by LLM)
Design Difference from the Semaphore Solution
Instead of a chain of binary semaphores, this solution uses a shared turn integer as the predicate and two condition variables — one per waiting method. Each method sleeps on its own CV until turn reaches its expected value.
Variable Roles
| Variable | Role |
|---|---|
turn | Tracks which method should run next (1=first, 2=second, 3=third, 4=done) |
cond2 | second() sleeps here until turn == 2 |
cond3 | third() sleeps here until turn == 3 |
mutex | Protects turn |
Why first() Needs No Lock
first() writes turn = 2 and signals cond2. It does not read turn before writing, so there is no race on reading a stale value. second() and third() both hold the mutex before reading turn, so the write from first() is safely observed. In a strictly correct implementation, first() should also lock the mutex before setting turn to avoid a potential data race under the C++ memory model — but for this problem’s purposes, the sequencing is logically correct.
Comparison: Semaphore vs. Condition Variable Solutions
| Property | Binary semaphores | Mutex + CVs |
|---|---|---|
| State tracked | Implicitly (semaphore value) | Explicitly (turn integer) |
first() needs lock? | No | Technically yes (but omitted) |
| Spurious wakeup safe? | N/A | Yes (while loop) |
| Extensible to N steps? | Add N-1 semaphores | Add N-1 CVs + update turn logic |
Problem 35: LeetCode 1115 - Print FooBar Alternately
Section titled “Problem 35: LeetCode 1115 - Print FooBar Alternately”LeetCode 1115 - Print FooBar Alternately
Instructor Solution
class FooBar {private: int n; sem_t sem1; sem_t sem2;
public: FooBar(int n) { this->n = n; sem_init(&sem1, 0, 0); sem_init(&sem2, 0, 0); }
void foo(function<void()> printFoo) {
for (int i = 0; i < n; i++) { printFoo(); sem_post(&sem2); sem_wait(&sem1); } }
void bar(function<void()> printBar) { for (int i = 0; i < n; i++) { sem_wait(&sem2); printBar(); sem_post(&sem1); } }};Elaboration (by LLM)
Problem Summary
Two threads call foo() and bar() concurrently. foo prints “foo” and bar prints “bar”. The output for n=3 must be foobarfoobarfoobar — strictly alternating, starting with foo.
Semaphore Roles
| Semaphore | Initial | Meaning |
|---|---|---|
sem1 | 0 | foo waits here after printing — signals that bar has finished its turn |
sem2 | 0 | bar waits here — signals that foo has printed and it’s bar’s turn |
Alternation Protocol (per iteration)
foo: printFoo() → sem_post(sem2) → sem_wait(sem1) ↓bar: sem_wait(sem2) → printBar() → sem_post(sem1) ↓foo: (unblocked from sem_wait(sem1)) → next iterationEach iteration is a complete handshake: foo prints and hands control to bar, bar prints and hands control back to foo.
Execution Trace for n=2
[foo]: printFoo() → "foo"[foo]: sem_post(sem2) → sem2: 0→1[foo]: sem_wait(sem1) → sem1=0, BLOCKS
[bar]: sem_wait(sem2) → sem2: 1→0, unblocked[bar]: printBar() → "bar"[bar]: sem_post(sem1) → sem1: 0→1
[foo]: unblocked from sem_wait(sem1) → sem1: 1→0[foo]: printFoo() → "foo"[foo]: sem_post(sem2) → sem2: 0→1[foo]: sem_wait(sem1) → BLOCKS
[bar]: sem_wait(sem2) → unblocked[bar]: printBar() → "bar"[bar]: sem_post(sem1) → sem1: 0→1
[foo]: unblocked → loop ends (i=2)Output: foobarfoobar ✅Why foo Starts Without Waiting
foo begins with printFoo() directly — no initial sem_wait. This is correct because foo is designated to go first. bar starts with sem_wait(sem2), ensuring it cannot print until foo has posted. The asymmetry (foo starts, bar waits) is intentional and encodes the “foo first” invariant.
Problem 36: LeetCode 1116 - Print Zero Even Odd
Section titled “Problem 36: LeetCode 1116 - Print Zero Even Odd”LeetCode 1116 - Print Zero Even Odd
Instructor Solution
class ZeroEvenOdd {private: int n; int num = 0; sem_t sem_zero, sem_odd, sem_even;public: ZeroEvenOdd(int n) { this->n = n; sem_init(&sem_zero, 0, 1); sem_init(&sem_odd, 0, 0); sem_init(&sem_even, 0, 0); }
// printNumber(x) outputs "x", where x is an integer. void zero(function<void(int)> printNumber) { for (int i=1; i<=n; i++){ sem_wait(&sem_zero); printNumber(0); if (i % 2 == 0) sem_post(&sem_even); else sem_post(&sem_odd); } }
void even(function<void(int)> printNumber) { for (int i=2; i<=n; i+=2){ sem_wait(&sem_even); printNumber(i); sem_post(&sem_zero); } }
void odd(function<void(int)> printNumber) { for (int i=1; i<=n; i+=2){ sem_wait(&sem_odd); printNumber(i); sem_post(&sem_zero); } }};Elaboration (by LLM)
Problem Summary
Three threads print interleaved output. For n=5, the required output is 0 1 0 2 0 3 0 4 0 5. The pattern is: zero always prints a 0 before each number, then either odd or even prints the number, then zero prints the next 0, and so on.
Semaphore Roles
| Semaphore | Initial | Controls |
|---|---|---|
sem_zero | 1 | zero thread’s turn to print a 0 (starts open so zero goes first) |
sem_odd | 0 | odd thread’s turn to print an odd number |
sem_even | 0 | even thread’s turn to print an even number |
Token-Passing Protocol
The output sequence is orchestrated by passing a “token” between the zero thread and either the odd or even thread:
zero: wait(sem_zero) → print(0) → post(sem_odd or sem_even)odd: wait(sem_odd) → print(i) → post(sem_zero)even: wait(sem_even) → print(i) → post(sem_zero)After printing a 0, zero decides which thread to hand off to based on i % 2. After printing their number, odd/even always return the token to zero.
Execution Trace for n=4
i=1 (zero): wait(sem_zero=1→0), print(0), i%2!=0 → post(sem_odd)i=1 (odd): wait(sem_odd=1→0), print(1), post(sem_zero)i=2 (zero): wait(sem_zero=1→0), print(0), i%2==0 → post(sem_even)i=2 (even): wait(sem_even=1→0), print(2), post(sem_zero)i=3 (zero): wait(sem_zero=1→0), print(0), i%2!=0 → post(sem_odd)i=3 (odd): wait(sem_odd=1→0), print(3), post(sem_zero)i=4 (zero): wait(sem_zero=1→0), print(0), i%2==0 → post(sem_even)i=4 (even): wait(sem_even=1→0), print(4), post(sem_zero)
Output: 0 1 0 2 0 3 0 4 ✅Loop Bounds in odd and even
The odd thread iterates i = 1, 3, 5, ... and the even thread iterates i = 2, 4, 6, .... Their loop counters exactly match the values they will print. This works because the zero thread is the gatekeeper — it controls exactly when odd or even may proceed, and does so in the correct sequence via i % 2.
Problem 37: LeetCode 1117 - Building H2O
Section titled “Problem 37: LeetCode 1117 - Building H2O”Instructor Solution (using Semaphore Counting)
class H2O { int numH = 0; pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; sem_t sem_O; sem_t sem_H;public: H2O() { sem_init(&sem_O, 0, 1); sem_init(&sem_H, 0, 0); }
void hydrogen(function<void()> releaseHydrogen) { sem_wait(&sem_H); releaseHydrogen();
pthread_mutex_lock(&mutex); // Every second hydrogen thread releases one oxygen thread if (++numH % 2 == 0) sem_post(&sem_O); pthread_mutex_unlock(&mutex); }
void oxygen(function<void()> releaseOxygen) { sem_wait(&sem_O); releaseOxygen(); sem_post(&sem_H); sem_post(&sem_H); }};Elaboration (by LLM)
Problem Summary
Hydrogen and oxygen threads must be paired to form water molecules. Each molecule requires exactly 2 hydrogen and 1 oxygen. Threads call hydrogen() or oxygen() and must synchronize so that atoms are released in valid H₂O groups.
Semaphore Roles
| Semaphore | Initial | Meaning |
|---|---|---|
sem_O | 1 | One oxygen molecule allowed to proceed initially (the first O starts the chain) |
sem_H | 0 | Hydrogen threads blocked until oxygen opens the gate |
Protocol
oxygen(): wait(sem_O) → releaseOxygen() → post(sem_H) → post(sem_H) ↓ ↓hydrogen(): wait(sem_H) → releaseHydrogen() → [if 2nd H: post(sem_O)]One oxygen proceeds, then immediately opens the gate for two hydrogens. After both hydrogens have released, the 2nd hydrogen (detected by numH % 2 == 0) opens the gate for the next oxygen.
Execution Trace (2 molecules: OHH OHH)
O1: wait(sem_O=1→0), releaseOxygen(), post(sem_H)×2 → sem_H=2
H1: wait(sem_H=2→1), releaseHydrogen(), numH=1, 1%2≠0 → no postH2: wait(sem_H=1→0), releaseHydrogen(), numH=2, 2%2=0 → post(sem_O)
O2: wait(sem_O=1→0), releaseOxygen(), post(sem_H)×2 → sem_H=2
H3: wait(sem_H=2→1), releaseHydrogen(), numH=3, 3%2≠0 → no postH4: wait(sem_H=1→0), releaseHydrogen(), numH=4, 4%2=0 → post(sem_O)Each oxygen enables exactly 2 hydrogens; every 2nd hydrogen enables the next oxygen. The chain is self-sustaining.
Instructor Solution (using Barriers)
class H2O { pthread_mutex_t mutex; int barrierCount; // Single counter reused for both barriers sem_t semH, semO; sem_t barrier1, barrier2;
void wait_at_barrier(sem_t &barrier) { pthread_mutex_lock(&mutex); if (++barrierCount == 3) { // Last thread releases the others barrierCount = 0; sem_post(&barrier); sem_post(&barrier); sem_post(&barrier); } pthread_mutex_unlock(&mutex); sem_wait(&barrier); }
public: H2O() { pthread_mutex_init(&mutex, NULL); barrierCount = 0; sem_init(&semH, 0, 2); sem_init(&semO, 0, 1); sem_init(&barrier1, 0, 0); sem_init(&barrier2, 0, 0); }
void hydrogen(function<void()> releaseHydrogen) { sem_wait(&semH); wait_at_barrier(barrier1); releaseHydrogen(); wait_at_barrier(barrier2); sem_post(&semH); }
void oxygen(function<void()> releaseOxygen) { sem_wait(&semO); wait_at_barrier(barrier1); releaseOxygen(); wait_at_barrier(barrier2); sem_post(&semO); }};Elaboration (by LLM)
What Is a Barrier?
A barrier is a synchronization point where all participating threads must arrive before any of them can proceed past it. Here, a “molecule barrier” of size 3 (2H + 1O) ensures that all three atoms of a molecule are present before any of them is released.
Two-Barrier Structure
Two barriers bookend the release calls:
barrier1: all 3 atoms must arrive before any can call releaseX()barrier2: all 3 atoms must finish releaseX() before any can return their slotThis guarantees that all three atoms of one molecule are released together as a coherent group, with no mixing of atoms from different molecules.
wait_at_barrier Mechanics
void wait_at_barrier(sem_t &barrier) { pthread_mutex_lock(&mutex); if (++barrierCount == 3) { // Am I the 3rd (last) to arrive? barrierCount = 0; // Reset for the next use of this barrier sem_post(&barrier); // Release all 3 (including myself) sem_post(&barrier); sem_post(&barrier); } pthread_mutex_unlock(&mutex); sem_wait(&barrier); // Wait until the last thread posts}The last thread to arrive posts the semaphore 3 times (once per participant, including itself), then all three threads unblock from sem_wait.
semH and semO as Molecule Slot Reservations
semH (initial=2) and semO (initial=1) limit how many atoms can be “in-flight” at once to exactly one molecule’s worth. Without these, a second oxygen might enter wait_at_barrier before the first molecule is complete, corrupting the barrier count.
semH=2: at most 2 hydrogen threads in-flight at a timesemO=1: at most 1 oxygen thread in-flight at a time→ at most one molecule assembling at a timeAfter passing barrier2, each thread returns its slot (sem_post(semH/O)), allowing the next set of atoms to begin assembling.
Instructor Solution (using Mutex and Condition Variables)
class H2O { pthread_mutex_t mutex; pthread_cond_t cond; int numH = 0; int numO = 0; int numAtoms = 0;
void makeMolecule(){ if (++numAtoms == 3){ numAtoms = 0; numH = 0; numO = 0; pthread_cond_broadcast(&cond); } }
public: H2O() { pthread_mutex_init(&mutex, nullptr); pthread_cond_init(&cond, nullptr); }
void hydrogen(function<void()> releaseHydrogen) { pthread_mutex_lock(&mutex); while (numH >= 2) pthread_cond_wait(&cond, &mutex); releaseHydrogen(); numH++; makeMolecule(); pthread_mutex_unlock(&mutex); }
void oxygen(function<void()> releaseOxygen) { pthread_mutex_lock(&mutex); while (numO >= 1) pthread_cond_wait(&cond, &mutex); releaseOxygen(); numO++; makeMolecule(); pthread_mutex_unlock(&mutex); }};Elaboration (by LLM)
Design: Monitor with Molecule Counter
This solution uses a single condition variable and explicit counters to track how many of each atom type have been admitted to the current molecule. When all 3 atoms have called makeMolecule(), the counters are reset and all waiting threads are broadcast to re-compete.
Variable Roles
| Variable | Role |
|---|---|
numH | Hydrogen atoms admitted to the current molecule (0–2) |
numO | Oxygen atoms admitted to the current molecule (0–1) |
numAtoms | Total atoms admitted (0–3); triggers reset when it hits 3 |
Entry Conditions
// Hydrogen: at most 2 per moleculewhile (numH >= 2) pthread_cond_wait(&cond, &mutex);
// Oxygen: at most 1 per moleculewhile (numO >= 1) pthread_cond_wait(&cond, &mutex);After each atom releases, makeMolecule() is called. When numAtoms reaches 3, the molecule is complete: all counters reset and broadcast wakes all sleeping threads for the next round.
Why broadcast Here
After a molecule completes, both hydrogen and oxygen threads may be waiting. Since all counters reset to 0, potentially up to 2 new H threads and 1 new O thread can proceed — broadcast wakes all of them and lets the while conditions sort out who enters.
Comparison of Three H₂O Approaches
| Property | Semaphore Counting | Barriers | Mutex + CV |
|---|---|---|---|
| Mechanism | Chain-based token passing | Rendezvous point | Shared molecule counter |
| Molecule boundary enforcement | Implicit (chain) | Explicit (2 barriers) | Explicit (numAtoms == 3) |
| Multiple molecules interleaved? | No | No | No |
| Conceptual complexity | Low | Medium | Low |
| Code complexity | Medium | High | Low |
Problem 38: LeetCode 1195 - Fizz Buzz Multithreaded
Section titled “Problem 38: LeetCode 1195 - Fizz Buzz Multithreaded”LeetCode 1195 - Fizz Buzz Multithreaded
Instructor Solution (using semaphores)
class FizzBuzz {private: int n; int num = 1; sem_t sem_fizz; sem_t sem_buzz; sem_t sem_fizzbuzz; sem_t sem_number;public: FizzBuzz(int n) { this->n = n; sem_init(&sem_fizz, 0, 0); sem_init(&sem_buzz, 0, 0); sem_init(&sem_fizzbuzz, 0, 0); sem_init(&sem_number, 0, 0); }
// printFizz() outputs "fizz". void fizz(function<void()> printFizz) { while (true){ sem_wait(&sem_fizz); if (num > n) break; printFizz(); sem_post(&sem_number); } }
// printBuzz() outputs "buzz". void buzz(function<void()> printBuzz) { while (true){ sem_wait(&sem_buzz); if (num > n) break; printBuzz(); sem_post(&sem_number); } }
// printFizzBuzz() outputs "fizzbuzz". void fizzbuzz(function<void()> printFizzBuzz) { while (true){ sem_wait(&sem_fizzbuzz); if (num > n) break; printFizzBuzz(); sem_post(&sem_number); } }
// printNumber(x) outputs "x", where x is an integer. void number(function<void(int)> printNumber) { for (num=1; num<=n; num++){ bool isDivBy3 = num % 3 == 0; bool isDivBy5 = num % 5 == 0;
if (!isDivBy3 && !isDivBy5){ printNumber(num); continue; }
if (isDivBy3 && isDivBy5) sem_post(&sem_fizzbuzz); else if (isDivBy3) sem_post(&sem_fizz); else sem_post(&sem_buzz);
sem_wait(&sem_number); }
// Wake-up and terminate all other threads sem_post(&sem_fizz); sem_post(&sem_buzz); sem_post(&sem_fizzbuzz); }};Elaboration (by LLM)
Problem Summary
Four threads run concurrently: number, fizz, buzz, and fizzbuzz. They must collectively print the FizzBuzz sequence from 1 to n in order. Only one thread prints per number, and the correct thread must be selected based on divisibility.
Design: number as the Conductor
The number thread is the sole driver of the sequence. It loops through every value of num from 1 to n and decides which thread should print:
num % 3 == 0 && num % 5 == 0 → post(sem_fizzbuzz)num % 3 == 0 → post(sem_fizz)num % 5 == 0 → post(sem_buzz)neither → printNumber(num) directly (no delegation)For divisible numbers, number posts the appropriate semaphore, then waits on sem_number for the worker thread to confirm it has printed. Only then does it advance num and continue.
Semaphore Roles
| Semaphore | Initial | Role |
|---|---|---|
sem_fizz | 0 | Gate for fizz thread |
sem_buzz | 0 | Gate for buzz thread |
sem_fizzbuzz | 0 | Gate for fizzbuzz thread |
sem_number | 0 | Acknowledgement back to number after a worker prints |
Worker Thread Pattern
All three worker threads share the same structure:
while (true) { sem_wait(&sem_X); // Block until number thread signals this type if (num > n) break; // Termination sentinel: number thread overshot printX(); // Print the correct label sem_post(&sem_number); // Acknowledge back to number thread}Termination
After number’s loop finishes (all n values processed), it posts all three worker semaphores once each. Each worker wakes, checks num > n (which is now true since num was incremented past n by the loop), and breaks out of its loop. This is a poison pill termination pattern.
Execution Trace (n=6)
num=1: neither → printNumber(1), continuenum=2: neither → printNumber(2), continuenum=3: div3 → post(sem_fizz); fizz: wait→print("fizz")→post(sem_number); number: wait→continuesnum=4: neither → printNumber(4), continuenum=5: div5 → post(sem_buzz); buzz: wait→print("buzz")→post(sem_number); number: wait→continuesnum=6: div3 → post(sem_fizz); fizz: wait→print("fizz")→post(sem_number); number: wait→loop endsTermination: post(sem_fizz), post(sem_buzz), post(sem_fizzbuzz) → all workers see num>6, breakInstructor Solution (using Mutex and Condition Variables)
class FizzBuzz {private: int n; int num = 1; enum Turn {FIZZ, BUZZ, FIZZBUZZ, NUMBER}; pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; pthread_cond_t cond_fizz = PTHREAD_COND_INITIALIZER; pthread_cond_t cond_buzz = PTHREAD_COND_INITIALIZER; pthread_cond_t cond_fizzbuzz = PTHREAD_COND_INITIALIZER; pthread_cond_t cond_number = PTHREAD_COND_INITIALIZER; Turn turn = NUMBER;public: FizzBuzz(int n) { this->n = n; }
// printFizz() outputs "fizz". void fizz(function<void()> printFizz) { pthread_mutex_lock(&mutex); while (true){ while (num <= n && turn != FIZZ) pthread_cond_wait(&cond_fizz, &mutex); if (num > n) break; printFizz(); turn = NUMBER; pthread_cond_signal(&cond_number); } pthread_mutex_unlock(&mutex); }
// printBuzz() outputs "buzz". void buzz(function<void()> printBuzz) { pthread_mutex_lock(&mutex); while (true){ while (num <= n && turn != BUZZ) pthread_cond_wait(&cond_buzz, &mutex); if (num > n) break; printBuzz(); turn = NUMBER; pthread_cond_signal(&cond_number); } pthread_mutex_unlock(&mutex); }
// printFizzBuzz() outputs "fizzbuzz". void fizzbuzz(function<void()> printFizzBuzz) { pthread_mutex_lock(&mutex); while (true){ while (num <= n && turn != FIZZBUZZ) pthread_cond_wait(&cond_fizzbuzz, &mutex); if (num > n) break; printFizzBuzz(); turn = NUMBER; pthread_cond_signal(&cond_number); } pthread_mutex_unlock(&mutex); }
// printNumber(x) outputs "x", where x is an integer. void number(function<void(int)> printNumber) { pthread_mutex_lock(&mutex); for (num=1; num<=n; num++){ bool isDivBy3 = num % 3 == 0; bool isDivBy5 = num % 5 == 0;
if (!isDivBy3 && !isDivBy5){ printNumber(num); continue; }
if (isDivBy3 && isDivBy5){ turn = FIZZBUZZ; pthread_cond_signal(&cond_fizzbuzz); } else if (isDivBy3){ turn = FIZZ; pthread_cond_signal(&cond_fizz); } else { turn = BUZZ; pthread_cond_signal(&cond_buzz); } while (turn != NUMBER) pthread_cond_wait(&cond_number, &mutex); } pthread_mutex_unlock(&mutex);
// Wake-up and terminate all other threads pthread_cond_signal(&cond_fizz); pthread_cond_signal(&cond_buzz); pthread_cond_signal(&cond_fizzbuzz); }};Elaboration (by LLM)
Design: turn as an Explicit Token
Instead of semaphores acting as one-shot signals, this solution uses a shared turn enum and four condition variables — one per thread type. The number thread holds the mutex for its entire loop, setting turn and signaling the appropriate CV. Worker threads hold the mutex while sleeping and printing, then hand turn back to NUMBER and signal cond_number.
Four Condition Variables
| CV | Who sleeps on it | Who signals it |
|---|---|---|
cond_fizz | fizz thread | number when turn=FIZZ |
cond_buzz | buzz thread | number when turn=BUZZ |
cond_fizzbuzz | fizzbuzz thread | number when turn=FIZZBUZZ |
cond_number | number thread (while waiting for worker ack) | Worker after printing, sets turn=NUMBER |
Worker Inner Loop
// Inside mutex, worker loop:while (num <= n && turn != FIZZ) // Wait while not our turn AND not finished pthread_cond_wait(&cond_fizz, &mutex);if (num > n) break; // Finished — exitprintFizz();turn = NUMBER; // Hand turn back to numberpthread_cond_signal(&cond_number);The double condition in the while (num <= n && turn != FIZZ) handles both the “not my turn” sleep and the termination check in one guard.
Termination
After number’s loop, num > n. The three signal calls at the end wake each worker. Each worker re-evaluates its while guard: num <= n is now false, so the inner while exits. The if (num > n) break then fires, and the worker releases the mutex and exits.
Semaphore vs. Condition Variable Comparison
| Property | Semaphore solution | CV solution |
|---|---|---|
number thread holds mutex during loop | No | Yes (entire loop) |
Worker threads share mutex with number | No | Yes |
| Termination mechanism | Poison pill posts | num > n check after wakeup |
| Spurious wakeup protection | Not needed (semaphores) | Yes (while double-guard) |
Parallelism between number and workers | Yes (brief) | No (serialized by mutex) |