Cache Performance
Cache is local memory, often with one or more levels “on chip” access to data at “clock speed”. Effective cache management is important to improve performance of computer systems.
The cache is organized in the same way as the main memory: a given number of bytes in a word, and a given number of words in a block. When data is accessed, the system checks if the data is already in the cache; if it is not in the cache, the entire block containing the requested address is copied to the cache. As always, data is referred to by its byte address, which is then broken down into the memory block in which it is stored, and its location within the block.
A machine cycle consists of the steps that a computer’s processor executes whenever it receives a machine language instruction. Modern CPUs are able to perform millions of machine cycles per second.
Clock rate: number of cycles your CPU executes per second, measured in GHz (gigahertz) - billions of cycles per second. The clock rate is useful for comparing the speed of chips made by the same company, but is not a reliable way to compare different types of computers because many other factors can determine the speed of a computer.
Single cycle CPU
Section titled “Single cycle CPU”An implementation in which every instruction operates in 1 clock cycle of a fixed length. An implementation where every instruction executes in 1 clock cycle using a variable length clock, which for each instruction is only as long as it needs to be.
Multi cycle CPU
Section titled “Multi cycle CPU”Multicycle CPU where each stage of an instruction requires 1 clock cycle. Let us assume a classic RISC pipeline, with the following five stages:
- Instruction fetch cycle (IF).
- Instruction decode/Register fetch cycle (ID).
- Execution/Effective address cycle (EX).
- Memory access (MEM).
- Write-back cycle (WB).
Without pipeline: 5 clock-cycle / instruction With pipelining: A new instruction is fetched every clock cycle by exploiting instruction-level parallelism, therefore, since one could theoretically have five instructions in the five pipeline stages at once (one instruction per stage), a different instruction would complete stage 5 in every clock cycle and on average the number of clock cycles it takes to execute an instruction is 1 (CPI = 1).
However, with a multiple-execution-unit processor, one may achieve even better CPI values (CPI < 1).
CPU searches the cache and if there is a hit, it retrieves data from the cache. Sometimes data is not there (miss) and the data will need to be brought from lower memory, main memory (miss penalty).
Miss Penalty refers to the extra time required to bring the data into cache from the Main
memory whenever there is a “miss” in the cache.
The miss rate (1 - hit rate) is the fraction of memory accesses not found in the upper memory
level.
Memory stall cycles per memory access: The number of stall cycles added to CPU execution
cycles for one memory access.
For an ideal memory: AMAT = 1 cycle, this results in zero memory stall cycles. Accessing
cache level 1 = 1 clock cycle
Note: sometimes Base CPI (ideal cache) = 2
Memory stall cycles
Section titled “Memory stall cycles”Memory stall cycles = Memory accesses / Program × Miss Rate × Miss Penalty = Instructions/Program × Misses/Instruction × Miss PenaltyAverage Memory Access Time (AMAT)
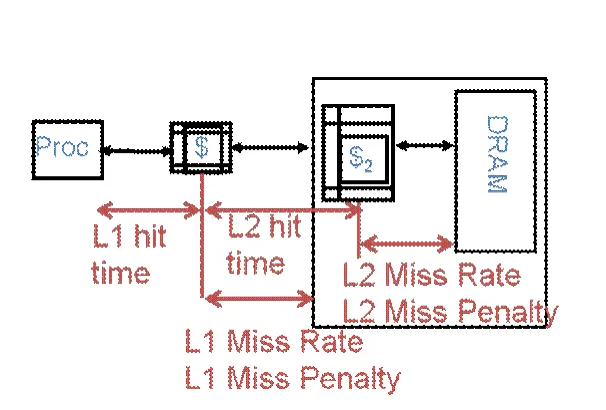
Section titled “Average Memory Access Time (AMAT)”The Average Memory Access Time (AMAT) is a fundamental metric for evaluating the performance of a memory hierarchy. It quantifies the average time required to access a memory location, accounting for both cache hits and misses.
AMAT = L1 hit time + (L1 miss rate × L1 miss penalty)Where:
- L1 hit time is the time to access data from the L1 cache.
- L1 miss rate is the fraction of memory accesses that are not found in the L1 cache.
- L1 miss penalty is the additional time required to retrieve data from the next level of the memory hierarchy (e.g., L2 cache or main memory) after a miss.
If there is only a single level of cache, the L1 miss penalty is simply the time to access main memory:
L1 miss penalty = main memory access timeIf a second-level cache (L2) is present, the L1 miss penalty becomes the average time to access L2, which itself accounts for possible L2 misses:
L1 miss penalty = L2 hit time + (L2 miss rate × main memory access time)Substituting this into the original AMAT equation yields:
AMAT = L1 hit time + L1 miss rate × (L2 hit time + L2 miss rate × main memory access time)Slide 38 - Chapter 5
Section titled “Slide 38 - Chapter 5”Hit time: 1 cycle (takes 1 cycle to get the data from cache 1)
Miss penalty: 20 cycles (it takes 20 cycles to get data from main memory)
Instruction cache (I-Cache) miss rate: 5% (5 instructions out of 100 are not found in the cache)
1 clock cycle = 1ns → hit time = 1ns
AMAT:
AMAT = hit time + miss rate × miss penalty = 1ns + 0.05 × 20ns = 1ns + 1ns = 2nsProblem Statements
Section titled “Problem Statements”Assume that main memory accesses take 70ns and that memory accesses are 36% of all instructions. The following table shows data for the L1 cache attached to processor P1:
| Processor | L1 Miss Rate | L1 Hit Time |
|---|---|---|
| P1 | 8.0% | 0.66 ns |
(a) Assume that the L1 hit time determines the cycle time for the processor. What is the clock rate?
Show Answer
Given:
Clock Period:
Clock Rate:
(b) What is the Average Memory Access Time for the processor (in ns)?
Show Answer
Formula:
Substituting values:
(c) Use the AMAT from above to find the average number of cycles for a memory access. (CPI)
Show Answer
Formula:
Substituting values (using from part b and from part a):
(d) Assuming a base CPI of 1.0 without any memory stalls (for the rest of the instruction types in the program), what is the total average CPI?
Show Answer
Formula:
Substituting values (using from part c):
(e) We will consider the addition of an L2 cache to try to reduce the average CPI; on a miss, P1 will now first check L2 cache, and only if that is a miss, will then need a main memory access. The L2 miss rate is 50%, and L2 hit time is 5.62ns.
Show Answer
Formula:
Substituting values:
The first-level (L1) cache is small enough to provide a one- or two-cycle access time.
The second-level (L2) cache is also built from SRAM but is larger, and therefore slower, than the L1 cache.
The processor first looks for the data in the L1 cache. If the L1 cache misses, the processor looks in the L2 cache. If the L2 cache misses, the processor fetches the data from main memory.
Many modern systems add even more levels of cache to the memory hierarchy, because accessing main memory is so slow.