Homework 1 - Modeling and Gradient Descent
This homework reviews general ideas about modeling, introduces the concept of gradient descent, and explores its practical application. The problems are color-coded by difficulty: green indicates easy problems, yellow indicates intermediate problems, and red indicates difficult problems.
Problem 1: Fundamentals of Modeling
Section titled “Problem 1: Fundamentals of Modeling”(a) What is a model?
Solution
A model is a simplified representation of a real life object or process. We use these to mimic the behavior of more complex objects or processes. In essence, these are just approximations to reality.
(b) Give an example of a model (preferably one that was not discussed in class) and explain why this is a model.
Solution
An example of a model is the globe representing the Earth. The globe is a simplified representation of the Earth, as it shows the general shape and topological features of the Earth, but it does not capture all the details and complexities of the actual planet. It is a model because it allows us to understand and visualize the Earth’s geography without needing to see the entire planet in person.
(c) George Box stated that “All models are wrong …”. If all models are wrong, then why do we study models?
Solution
The reason we study models is because they can still be useful for understanding and predicting phenomena, even if they are not perfectly accurate. They can help us understand patterns and relationships in data so that we can make informed predictions and decisions based on those predictions.
(d) What is a mathematical model?
Solution
A mathematical model is a model where the inputs and the outputs are numerical. Essentially, it uses mathematical relationships to describe phenomena. For example, the equation is a mathematical model that describes a linear relationship between and .
(e) What are the two goals of modeling?
Solution
Prediction: Can the model tell us what will happen for a specific phenomenon?
Explanation: What causes the phenomenon and what drives the result?
In essence, we want to be able to predict what will happen and understand why it happens.
(f) Suppose there is some phenomenon that we wish to model. Do we usually know all of the inputs or drivers of this phenomenon?
Solution
No, we typically do not know all the inputs or drivers of a phenomenon - this is why we need to use models in the first place.
(g) In class, we stated that finding a function or a model can be difficult and that recent advancements in artificial intelligence, particularly machine learning, can help us. What is artificial intelligence?
Solution
Artificial Intelligence is when computers/programs emulate human thought:
- Having a program describe a picture
- Solving equations
- Recognizing objects/sounds/language
(h) In class, we stated that finding a function or a model can be difficult and that recent advancements in artificial intelligence, particularly machine learning, can help us. What is machine learning? (Use the most recent definition we discussed in class).
Solution
Machine Learning is the process of training a piece of software, called a model, to make useful predictions or to generate content from data.
(i) Read the section called History on this page: https://en.wikipedia.org/wiki/Machine_learning. What was one of the first machine learning models?
Solution
One of the first machine learning models was Arthur Samuel’s checkers-playing program, which learned to evaluate board positions and improve its performance over time.
(j) Read the section called History on this page: https://en.wikipedia.org/wiki/Machine_learning. How did Tom Mitchell define machine learning?
Solution
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.
(k) Read the section called History on this page: https://en.wikipedia.org/wiki/Machine_learning. True or False? The inspiration for neural networks comes from algorithms that mirrors the human brain/thought process.
Solution
True.
(l) True or False? All of artificial intelligence falls under machine learning.
Solution
False. Artificial intelligence is a broader field, inside of which machine learning is a part of.
(m) True or False? All of machine learning falls under artificial intelligence.
Solution
True.
Problem 2: The Need for Gradient Descent
Section titled “Problem 2: The Need for Gradient Descent”(a) Suppose we have a bunch of data points and we wish to use a linear model to predict the value of . What parameters (or values) are we looking to find?
Solution
We are looking to find the coefficients of the linear model, which typically include the slope and the intercept. In a simple linear regression model, we would be looking to find the values of (the slope) and (the intercept) in the equation .
(b) In order to find these parameters, we have to define a cost function. How many dimensions would be required to graph the cost function?
Solution
The cost function for a linear model with 2 parameters (slope and intercept) would require 3 dimensions to graph. This is because the cost function is , which depends on two variables: (the slope) and (the intercept). To visualize this relationship, we need one axis for , one axis for , and a third axis for the cost value itself.
(c) Once we have our cost function, what exactly are we looking to do with this function? What is our primary objective?
Solution
The goal is to minimize the cost function, which means finding the parameter values that result in the lowest cost.
(d) Explain how a machine can use the cost function to learn better values for our parameters. A full answer would outline the algorithm being used for the computer/machine to learn.
Solution
A machine can use the cost function to learn better values for our parameters through an optimization algorithm called gradient descent. The algorithm works as follows:
- Initialize parameters: Start with and (or some random values).
- Calculate the cost for this and using the cost function.
- Compute the partial derivatives of the cost function with respect to and to find the gradients.
- Define as the learning rate. It will be a small positive number (e.g., 0.01).
- Update the parameters as follows:
- Repeat steps 2-5 until the cost function converges to a minimum or until a specified number of iterations is reached.
(e) Using your answer above, explain what it means when we say the machine is learning?
Solution
When we say the machine is learning, we mean that it is iteratively adjusting its parameters (in this case, and ) based on the cost function and the gradients. The machine is considered to be learning because it is improving its performance on the task (predicting from ) by minimizing the cost function, which tells us that it is getting better at making predictions.
(f) Now suppose we have a bunch of data points and we wish to use a quadratic model to predict the value of . That is, we wish to find real numbers , , and such that How many dimensions would be required to plot the cost function? Can we actually graph this function? If not, then is there a particular technique we can use to find the minimum of the cost function?
Solution
The cost function for a quadratic model with 3 parameters (, , and ) would require 4 dimensions to graph. Since we cannot visualize 4-dimensional graphs, we can’t “cheat” our way out of this by graphing the cost function. Instead, we can use gradient descent to find the minimum of the cost function, just like we did for the linear model. The algorithm would be similar, but we would need to compute the gradients with respect to 3 parameters instead of 2.
Problem 3: Gradient Descent with Large Learning Rate
Section titled “Problem 3: Gradient Descent with Large Learning Rate”In class, we performed the gradient descent algorithm on by starting at and using the learning rate, .
(a) This time, perform the first three iterations of gradient descent on by starting at and using the learning rate, . Describe what happens.
Solution
Step 1: Compute the derivative of :
Starting at :
- At ,
- Update :
- At ,
- Update :
- At ,
- Update :
After the first 3 iterations, we see that has diverged by a large amount from the minimum (which is at ). This happened because the learning rate is too large, causing the updates to overshoot the minimum and diverge instead of converging towards it.
Problem 4: One Dimensional Gradient Descent Practice
Section titled “Problem 4: One Dimensional Gradient Descent Practice”For all of the parts below, let .
(a) Sketch a graph of .
Solution
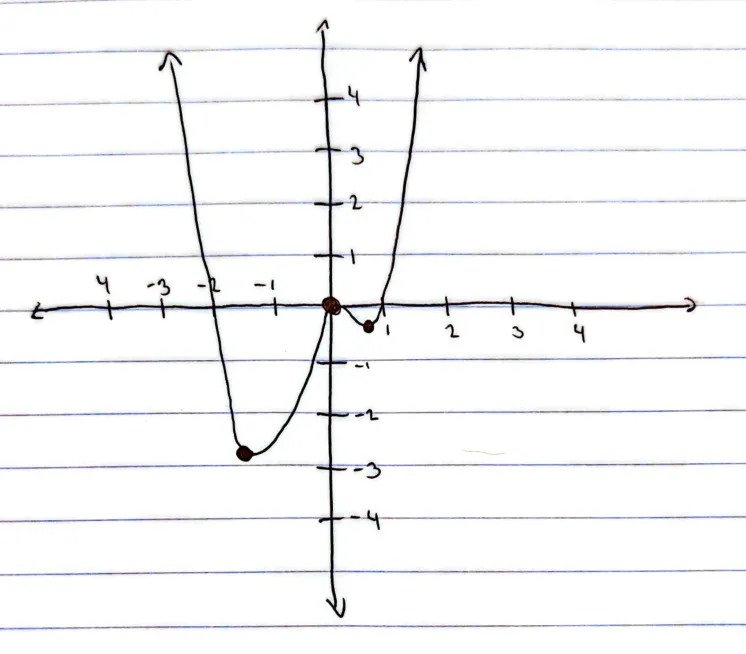
(b) Graphically, where is the global minimum of the function? If needed, round your answer to two decimal places.
Solution
Graphically, the global minimum of the function occurs at in the third quadrant of the graph.
To find the exact value, we compute the derivative and set it equal to to find the critical points (, , or ), and then evaluate the function at those points.
(c) Now suppose we wish to find the global minimum by using gradient descent. Starting at , compute what happens over the next three iterations. You may take the learning rate to be .
Solution
Using:
Starting at :
Update :
At :
Update :
At :
Update :
After 3 iterations, we have .
(d) If you had to guess, what value do you think our algorithm in Problem 4 Part (c) will converge to?
Solution
Based on the results of the first 3 iterations, it seems that the algorithm is converging towards a local minimum rather than the global minimum.
(e) Compute what happens after 500 iterations. You may use a calculator, Excel, or a programming language. Please explain what you did to get your answer.
Solution
def f(x: float) -> float: return x**4 + x**3 - 2 * x**2
def f_prime(x: float) -> float: return 4 * x**3 + 3 * x**2 - 4 * x
def gradient_descent( x_initial: float, alpha: float, iterations: int,) -> float: x = x_initial for _ in range(iterations): x = x - alpha * f_prime(x)
return x
x_initial = 1.0alpha = 0.1iterations = 500
x_final = gradient_descent(x_initial, alpha, iterations)
print(f"Result after {iterations} iterations, starting at x = {x_initial}:")print(f"x_final = {x_final:.12f}")print(f"f(x_final) = {f(x_final):.12f}")Output:
Result after 500 iterations, starting at x = 1.0:x_final = 0.693000468165f(x_final) = -0.397046341000I implemented the gradient descent algorithm in Python and ran it for 500 iterations with and learning rate . The code defines 3 functions: , (the derivative), and the gradient descent function that iteratively updates using the update rule. After 500 iterations, the algorithm converged to approximately , at which point the function value is approximately . This result lines up with our earlier approximations: starting from , the algorithm converges to a local minimum (not the global minimum, which occurs around ). The algorithm was able to minimize the cost function from its initial position successfully, even though it converged to a local minimum instead of the global minimum.
(f) Now suppose we change our starting point to . Compute what happens over the next three iterations. You may take the learning rate to be .
Solution
Using:
Starting at :
Update :
At ,
Update :
At ,
Update :
After 3 iterations (starting from ), we have .
(g) If you had to guess, what value do you think our algorithm in Problem 4 Part (f) will converge to?
Solution
It seems that the algorithm is converging towards the global minimum, which is approximately at .
(h) Do you think that in using gradient descent the starting point matters?
Solution
Yes, the starting point seems to act as a sort of initial guess for the algorithm and influences the path that the algorithm takes towards a minimum.