Homework 3 - Calculus, Perceptrons, and Neural Networks
This homework reviews calculus concepts, perceptron and sigmoid neuron fundamentals, and explores neural networks for digit recognition.
Problem 1: Crash Course Calculus Review
Section titled “Problem 1: Crash Course Calculus Review”In this exercise, we will review some of the crash course calculus concepts that we discussed in lecture.
(a) Explain how the usual slope formula, , can be used to develop the formula for the derivative.
Solution
If we have a function where we want to find the rate of change at a single point, then we want the slope of the tangent line at the point . We can find a nearby point on the function, which we can call . Using these two points, we can approximate the slope of the tangent line with the slope formula:
By combining like terms and in the denominator, we get:
As we let get closer to as much as possible, or in other words, let approach 0, we obtain:
which is the formula for the derivative.
(b) Let . Sketch the graph of . You may use a 3D graphing calculator such as https://www.desmos.com/3d.
Solution
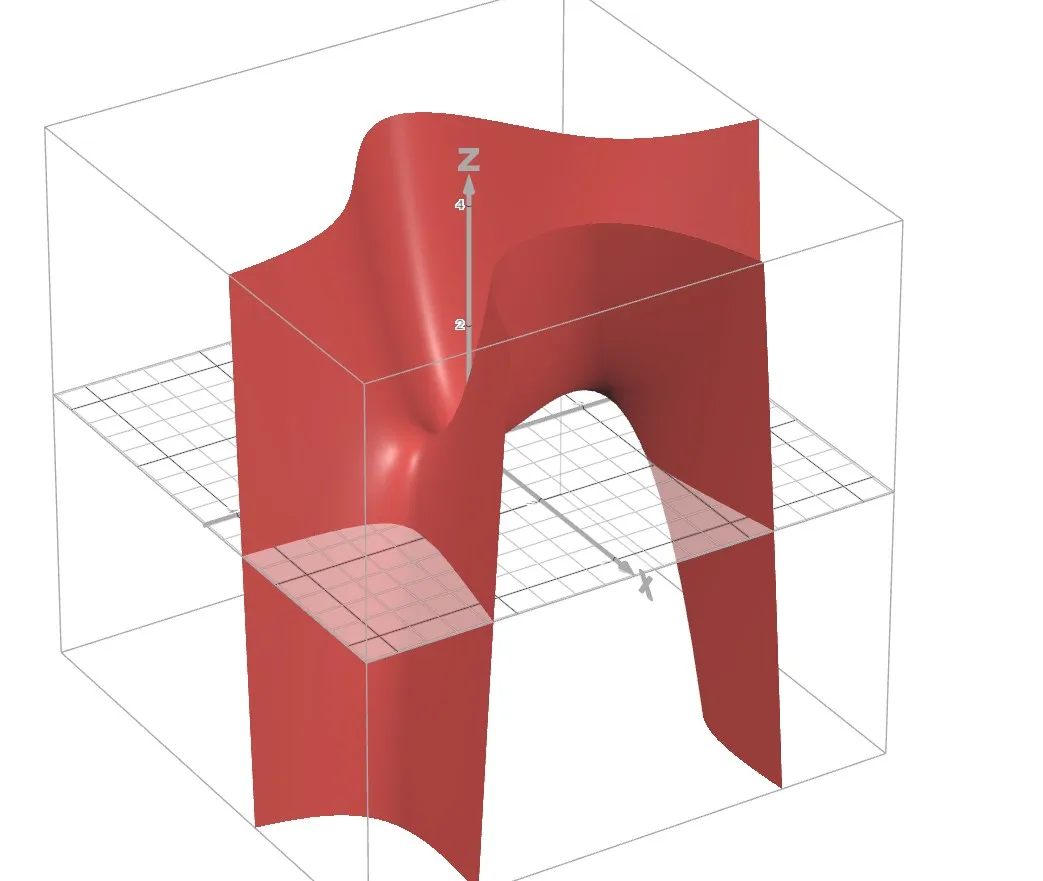
(c) Let . Find .
Solution
We compute the partial derivative with respect to :
Evaluating at the point :
(d) Geometrically, what does represent?
Solution
It represents the slope of the tangent line in the direction to the surface at the point . Since , the surface is rising in the direction at the point with a slope of 10.
(e) Let . Find .
Solution
We compute the partial derivative with respect to :
Evaluating at the point :
(f) Geometrically, what does represent?
Solution
It represents the slope of the tangent line in the direction to the surface at the point . Since , the surface remains flat in the direction at the point due to the slope being 0.
Problem 2: Two-Dimensional Gradient Descent
Section titled “Problem 2: Two-Dimensional Gradient Descent”In this exercise, we will explore gradient descent a bit more. Consider the two-dimensional cost function below:
(a) Compute .
Solution
(b) Compute .
Solution
(c) Perform the next two iterations of gradient descent starting at with a learning rate of .
Solution
Iteration 1:
Evaluate the cost function and partial derivatives at :
Update using :
Iteration 2:
Evaluate the cost function and partial derivatives at :
Update using :
(d) Draw an analogy between minimizing a cost function in machine learning and tuning a guitar.
Solution
When guitar players tune their instruments and notice a string is out of tune, they gradually adjust the tuning peg by turning it tighter or looser until the pitch sounds correct. Minimizing a cost function in machine learning is analogous in the sense that the cost function measures how incorrect the model’s predictions are, and we use gradient descent to adjust parameters in the direction that reduces this error. In both cases, we iteratively make small adjustments based on the feedback we get, whether it’s the sound of the pitch or the value of the cost function, until we reach a desired state.
Problem 3: The Perceptron
Section titled “Problem 3: The Perceptron”In this question we will review the perceptron.
(a) Explain what is meant by the perceptron? A good answer would discuss what the inputs and outputs are.
Solution
The perceptron is a piecewise function that takes in several binary inputs and returns a binary output. The inputs and the output are all equal to 0 or 1. Attached to the inputs are weights that measure how much each respective input should affect the output. There is also a bias term that measures how easy it is for the perceptron to output a 1.
(b) In the perceptron, what function do we use to compute the output?
Solution
(c) Consider the single layer perceptron below.

Suppose . Also suppose that . Compute the perceptron’s output. Hint: remember that a perceptron’s output is either 0 or 1.
Solution
We apply the perceptron function from part (b) and evaluate the weighted sum:
Since the result , the perceptron outputs .
(d) In class, we stated that for the perceptron, small changes in the input can produce large changes in the output. Suppose we have the same perceptron as outlined above where and this time, . What is the perceptron’s output now?
Solution
We apply the same function to get:
Since the weighted sum equals 0, the perceptron outputs 0.
(e) In class, we stated that there were two fundamental restrictions with the perceptron. What are these restrictions/problems?
Solution
The first restriction is that the perceptron output is entirely binary (either 0 or 1) and very sensitive to small input changes. This means that a tiny adjustment to an input can result in a completely different output. The second restriction is that the perceptron, while a reasonable attempt to model how humans make decisions, is too limited to capture the full complexity of human decision-making. We can address this limitation by introducing hidden layers to make the model more sophisticated.
(f) Read the article found here: https://news.cornell.edu/stories/2019/09/professors-perceptron-paved-way-ai-60-years-too-soon. According to the article, what was one of the problems with Roseblatt’s perceptron?
Solution
One issue with Rosenblatt’s perceptron was that it had only a single layer, which made it insufficient for more complex tasks like computer vision and language processing.
Problem 4: The Sigmoid Neuron
Section titled “Problem 4: The Sigmoid Neuron”In the previous question we identified the shortcomings of the perceptron. We now aim to review its upgrade — the sigmoid neuron.
(a) How is the sigmoid neuron different from the perceptron? Phrased differently, why is the sigmoid neuron more flexible than the perceptron?
Solution
The sigmoid neuron differs from the perceptron because it allows the inputs to be any real number and allows the output to be any real number between 0 and 1. This makes it more flexible than the perceptron since it removes the constraint that inputs and outputs must be strictly binary. Rather than using a piecewise step function like the perceptron, the sigmoid neuron has a smooth activation function:
where .
(b) Allow us to reconsider the neural network above:
Suppose the activation function is now the sigmoid function. Compute the output of the sigmoid neuron when . (This is the same input as before in Problem 3 part (c)).
Solution
First, we calculate the weighted sum:
Next, we apply the sigmoid function:
(c) Allow us to now show that a small change in the weights/bias produces small changes in the output. Suppose we have the same sigmoid neuron as outlined above where and this time, . What is the sigmoid neuron’s output now?
Solution
We compute the weighted sum with the new bias:
Then we apply the sigmoid function:
(d) What conclusion can you draw regarding small changes in the weights/bias with the perceptron versus the sigmoid neuron?
Solution
The perceptron is very sensitive to small adjustments in weights or bias, causing abrupt changes in the output. For example, when the perceptron produced an output of 1, yet when the output was 0. However, the sigmoid neuron handles small parameter changes gracefully. With the same input values, changing the bias from to results in only a minimal difference in output, approximately 0.0025.
(e) Compute in the neural network below. Assume that , and use the sigmoid function for the activation function.
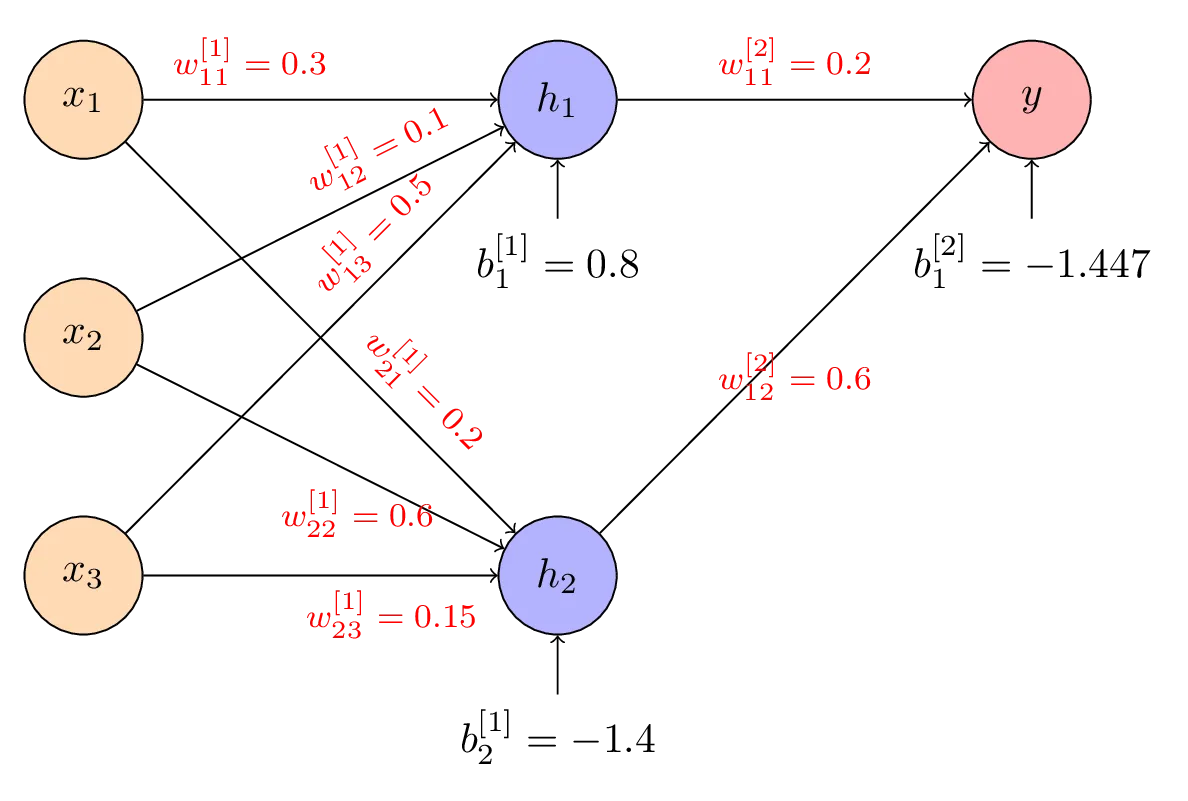
Solution
We calculate the weighted sum for the first hidden neuron:
Then we apply the sigmoid activation function:
(f) Compute . Assume that , and use the sigmoid function for the activation function.
Solution
We calculate the weighted sum for the second hidden neuron:
Then we apply the sigmoid activation function:
(g) Compute the output of the above network, . Assume that , and use the sigmoid function for the activation function.
Solution
We calculate the weighted sum for the output layer using the hidden layer activations:
Then we apply the sigmoid function to get the final output:
Problem 5: Grayscaling
Section titled “Problem 5: Grayscaling”In this question we will review grayscaling.
(a) What is a pixel?
Solution
A pixel is the smallest unit in a digital screen or display. Each pixel can only show one color at any given time.
(b) True or False? The RGB color model states that red, green and blue can be combined in different ways to produce a wide range of colors.
Solution
True. In the RGB model, any color can be represented as a linear combination of red, green, and blue.
(c) What is your favorite color?
Solution
My favorite color is turquoise.
(d) Using this site, http://www.cknuckles.com/rgbsliders.html, find out the RGB values for the color you picked above. Note: You’re welcome to use any other website that has a RGB slider such as this one: https://tuneform.com/tools/color/rgb-color-creator.
Solution
For turquoise, the RGB values are .
(e) What formula did we use to convert a color to grayscale? Hint: https://en.wikipedia.org/wiki/Luma_(video)#Rec._601_luma_versus_Rec._709_luma_coefficients.
Solution
The Luminosity Method formula is used to convert a color to grayscale: .
(f) Using the formula above, convert the RGB value of your favorite color in part (c) to grayscale. Write down what value of red, green and blue you get.
Solution
Applying the Luminosity Method:
So the grayscale RGB values are .
(g) For the color you get above, what is the grayscale intensity? (Hint: just divide by 255).
Solution
The grayscale intensity is .
Problem 6: Neural Network Overview
Section titled “Problem 6: Neural Network Overview”In this question we will review the final product — our neural network.
(a) Write down the four steps in creating a neural network.
Solution
The four steps are:
- Define the input and output layers based on your problem
- Choose the number of hidden layers and the number of neurons in each
- Select cost and activation functions
- Use training data with a training algorithm (such as mini-batch gradient descent) to determine the optimal weights and biases
(b) For the neural network example we considered in class, what was our task?
Solution
The task was to recognize and classify handwritten digits (0 through 9) from images.
(c) We stated that the inputs were pictures but to be more precise, we needed these inputs to be numerical. How did we get the images to be numerical?
Solution
We converted images to numerical form by assigning grayscale values to each of the pixels in each image.
(d) How many layers did our neural network have?
Solution
Our neural network had 3 layers: the input layer, the hidden layer, and the output layer.
(e) Within each layer, how many neurons did we have?
Solution
The input layer had neurons (one for each pixel). The hidden layer had 30 neurons, and the output layer had 10 neurons (one for each digit 0 through 9).
(f) What do we hope the hidden layer is doing?
Solution
We hope the hidden layer learns to function as a feature detector, enabling its neurons to recognize specific patterns in handwritten digits, such as horizontal strokes found in digits like 7.
(g) What activation function did we use?
Solution
We used the sigmoid function as the activation function.
(h) How did we find the weights and biases?
Solution
We determined the weights and biases using mini-batch gradient descent.
Problem 7: Running a Neural Network on MNIST
Section titled “Problem 7: Running a Neural Network on MNIST”In this question we will run an image through the neural network we saw in class. Please note that you do not have to enter any code; instead, you’re just running code that I will provide.
(a) Download the image on Brightspace called “homework_image”.
Solution
(Solution involves downloading an image file.)
(b) Click this link: https://colab.research.google.com/drive/1s0SaR8cYUf52jumFDt26Xe0nj6ORVOUd?usp=sharing. You wouldn’t be able to edit this code since this is located in my Google Drive. You’ll need to save a copy of this in your own Drive. To do so, click “File” followed by “Save a Copy in Drive”.
Solution
(Solution involves accessing and copying a Google Colab notebook.)
(c) Execute the first three cells. It should take about 8 minutes. Upon executing the third cell, you will be prompted to upload an image. Upload the image you downloaded from Brightspace called “homework_image”.
Solution
(Solution involves executing code cells and uploading an image.)
(d) Execute the remaining cell blocks and make a note of the probabilities you obtain in the last code block. What does the neural network predict the digit is?
Solution
The neural network predicted the digit 3.
(e) Redo parts (c) and (d) again. Did you get a different result or different probabilities?
Solution
Upon redoing parts (c) and (d), the network still predicted digit 3, but the probabilities changed. In the second run, I got higher probabilities for digits 1 and 2 than originally, whereas in the first run the digit 5 had a nonzero probability. Digit 3 still maintained the highest probability across both runs, though its value was not constant.
(f) Above, you should get slightly different results each time. Can you perhaps explain why?
Solution
The variation in results is due to two reasons. First, when initializing the neural network, random weights and biases are generated each time. Second, the training process uses mini-batch gradient descent rather than batch gradient descent, which means the training data is randomly shuffled at the beginning of each epoch. Since the network trains on randomly selected mini-batches of images, the final weight values differ between runs. These differing weights lead to the slight variations in the output probabilities for different digits that we observe.
Problem 8: Deep Learning at Apple
Section titled “Problem 8: Deep Learning at Apple”For this question, please read the section called Introduction here: https://machinelearning.apple.com/research/face-detection.
(a) What kind of neural network does Apple use for features such as face recognition?
Solution
Apple uses Deep Neural Networks for features such as face recognition.
(b) What are the drawbacks of using models in deep learning? Hint: see the second paragraph under the section Introduction.
Solution
Deep learning models consume significant system resources compared to traditional computer vision. These models demand substantially more memory, disk storage, and computational power.
(c) How did Apple (and the rest of the industry) manage to overcome the drawbacks outlined above?
Solution
Apple and other companies addressed these limitations by using cloud-based services and APIs to execute their deep learning models. This approach enables them to send images to remote servers for analysis using deep learning inference. Since cloud services typically provide powerful GPUs with substantial memory capacity, they can run large deep learning models server-side rather than locally, making the technology accessible despite mobile devices being less powerful.