Math 245 Spring 2025 Exam 1
Problem 1
Section titled “Problem 1”These questions are conceptual (short answer) questions.
(a) [5 pt / 5 pts] Explain what is meant by a mathematical model.
Solution
A model that has numerical inputs and outputs.
(b) [5 pt / 10 pts] Consider Tom Mitchell’s definition of machine learning. If the task is to create a recommendation system for YouTube videos, then what can the training data be?
Solution
where
and where 0 indicates the user did not click a recommended video and 1 indicates the user clicked a recommended video.
(c) [10 pt / 20 pts] Explain why the cost function can be considered a measure of error.
Solution
For us, the cost function usually has a term, and this is exactly the error. We square the error and take the mean, so every cost function measures error because it has this error term.
(d) [10 pt / 30 pts] Explain why continuous activation functions (such as the sigmoid function) are preferred over discrete activation functions (such as the perceptron activation function).
Solution
Continuous activations are preferred over discrete because the main problem with the perceptron is that small changes in the weights or biases produce large changes in the output. Continuous activation functions allow small changes in the weights and biases to produce small changes in the output. Additionally, continuous functions like the sigmoid are differentiable everywhere, which allows for gradient-based learning. In order to optimize, we have to take derivatives, and we get that with continuous activation functions but not with the perceptron.
Problem 2
Section titled “Problem 2”Suppose we are given the following data: , , , .
(a) [5 pt / 35 pts] Further suppose we wish to model the above data via a linear function of the form . Find for .
Solution
(b) [5 pt / 40 pts] In class, our cost function was typically the mean squared error. Instead, let’s use a new cost function called the Mean Absolute Error or MAE. By definition,
For the data in Problem 2(a) above, compute the Mean Absolute Error.
Solution
| 1 | 5.15 | 3 | 2.15 |
| 5 | 16.54 | 11 | 5.54 |
| 6 | 20.04 | 13 | 7.04 |
| 7 | 22.86 | 15 | 7.86 |
Note: Both MSE and MAE have the term. The difference is that MSE uses the square while MAE uses absolute value. MSE is easier to work with in practice because the squared term is always differentiable everywhere, whereas the absolute value function is not differentiable at certain points. Therefore, in practice you typically use MSE over MAE.
Problem 3
Section titled “Problem 3”Consider the two-dimensional cost function below:
Note that the partial derivatives are:
(a) [15 pt / 55 pts] Perform the next two iterations of gradient descent starting at with a learning rate of .
Solution
Iteration 1
Starting with , :
Compute the partial derivatives:
Update with :
Thus
Iteration 2
Starting with , :
Compute the partial derivatives:
Update with :
Thus
(b) [5 pt / 60 pts] Do you think this setup (meaning the initialization and learning rate specified above) will converge to a local minimum or global minimum?
Solution
This setup seems to have converged to a global minimum. Since is globally minimized when and is globally minimized when , the function converges to the global minimum.
Problem 4
Section titled “Problem 4”Consider the following neural network.

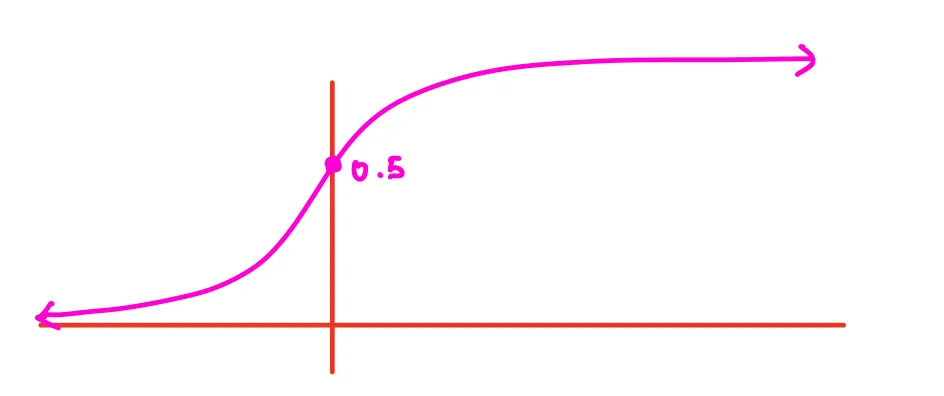
(a) [10 pt / 70 pts] Assuming that , , and that the activation function is the sigmoid function, find . You may round to two decimal places.
Solution

Problem 5
Section titled “Problem 5”In class, we discussed (regular) gradient descent versus mini-batch gradient descent.
(a) [5 pt / 75 pts] When is it suitable to use mini-batch gradient descent instead of (regular) gradient descent?
Solution
When our dataset is extremely large.
(b) [5 pt / 80 pts] Which method is inherently more random? Explain why.
Solution
Mini-batch GD is more random because there is variability in how the data is being shuffled in. This doesn’t happen in (batch) GD since in (batch) GD, we update over the ENTIRE dataset.
Problem 6
Section titled “Problem 6”In class, we discussed how convergence in gradient descent depends on initialization and the learning rate. Depending on these factors, gradient descent can converge to different points. Assume that the cost function, , is known and consider the following situation:
(a) [10 pt / 90 pts] Both Alice and Bob see the same data set and use the same cost function. Alice implements the gradient descent algorithm with an initialization at and a learning rate of . By the end of the gradient descent process, she converges to and . Meanwhile, Bob initializes at with a learning rate of and converges to and . How can we determine which point is more likely to yield the global minimum?
Solution
Compute vs. . Whichever has the lower cost is more likely to be the global minimum.
Problem 7
Section titled “Problem 7”This question will ask you to summarize our discussion from class.
(a) [10 pt / 100 pts] Explain how a feedforward neural network can classify MNIST digits. Points will be awarded based on the clarity and completeness of your answer. Your answer should include the terms: task, training data, grayscale, input layer, output layer, hidden layer, mini-batch gradient descent, epoch, cost function, feature detection, and neural network.
Solution
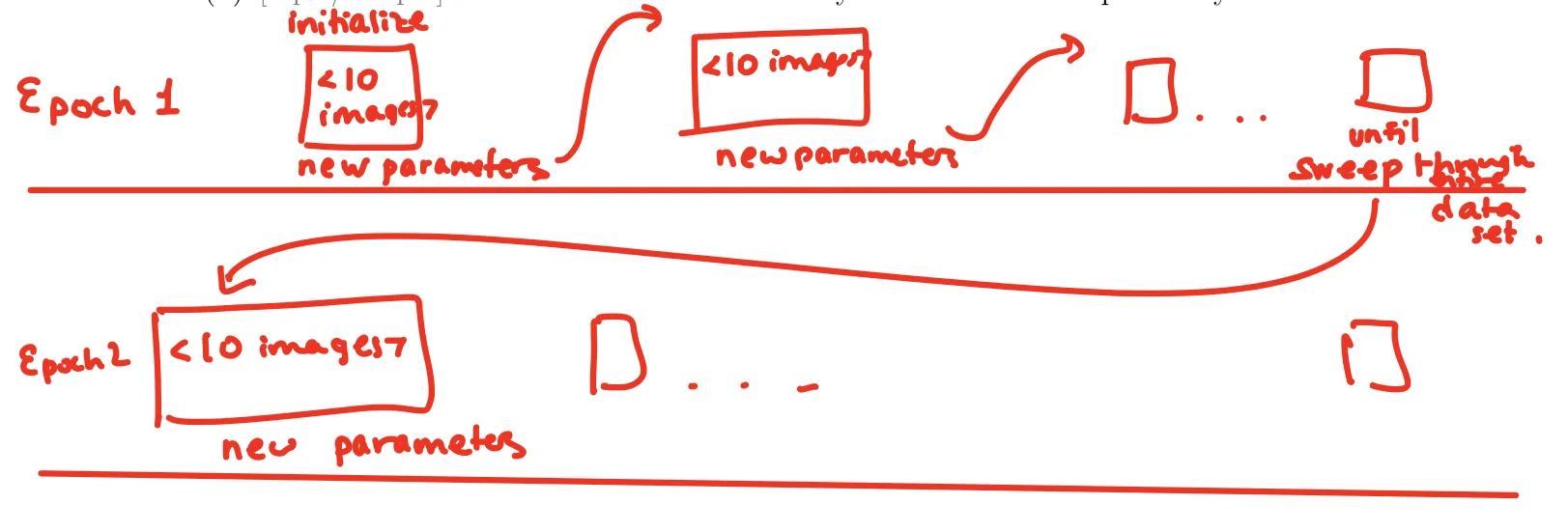
Our task is to classify a handwritten digit. Our model is a neural network. Our neural network consists of an input layer, output layer, and hidden layer. The input layer takes the grayscale intensity of each pixel, the hidden layer detects features, and the output layer represents the activations for every digit.
Our training data consists of 50,000 images from the MNIST dataset where each picture is a 28×28 grayscaled photo of a digit. Since there is a large amount of data, we’ll aim to use mini-batch gradient descent, where we feed in (let’s say) 10 images at a time and run gradient descent with our cost function on just these 10 images. Doing this 5,000 times sweeps through the entire dataset, which is a single epoch. We’ll then repeat this over multiple epochs until the cost function converges.