07 - Memory Management | CSCI 340
Problem 1: Variable Partitioning
Section titled “Problem 1: Variable Partitioning”What’s variable partitioning in memory management? Briefly explain.
Instructor Solution
Variable partitioning is a memory management scheme where the operating system allocates memory segments of varying sizes based on the specific requirements of each process. Variable partitions are created on the fly as processes enter the system, ensuring that a process receives exactly the amount of memory it needs. While this approach effectively eliminates internal fragmentation (wasted space within a partition), it often leads to external fragmentation, where free memory becomes scattered into small, non-contiguous holes that may be too small to accommodate new incoming processes.
Private Concise answer (by LLM)
Variable partitioning sizes each partition to exactly what the process needs, eliminating internal fragmentation, but produces external fragmentation over time as freed regions scatter into non-contiguous holes that may be too small for new processes.
Concise answer (by LLM):
Variable partitioning allocates memory segments sized exactly to each process’s needs, eliminating internal fragmentation but causing external fragmentation as freed segments leave behind scattered holes too small for new processes.
Elaboration (by LLM)
Variable partitioning is best understood in contrast to its predecessor, fixed partitioning, where memory was divided into a set of predetermined-sized slots at boot time. The problem with fixed partitions is that a 3KB process placed in a 10KB slot wastes 7KB — that’s internal fragmentation.
Variable partitioning fixes this by sizing each partition to exactly what the process needs:
Fixed Partitioning: Variable Partitioning:┌─────────────────┐ ← 10KB slot ┌─────────────────┐│ Process (3KB) │ │ Process (3KB) │ ← exactly 3KB│ [7KB wasted] │ ├─────────────────┤└─────────────────┘ │ Process (7KB) │ ← exactly 7KB┌─────────────────┐ ← 10KB slot ├─────────────────┤│ Process (7KB) │ │ Hole (5KB) │ ← free space│ [3KB wasted] │ └─────────────────┘└─────────────────┘The life cycle of variable partitioning:
As processes arrive, the OS allocates exactly the right partition size. As processes finish and leave, they leave behind “holes” — free regions of memory scattered throughout RAM. Over time, you can end up in a situation like this:
RAM:┌──────────┐│ P1(8KB) │├──────────┤│ Hole(3KB)│ ← free, but too small for a 10KB process├──────────┤│ P2(6KB) │├──────────┤│ Hole(4KB)│ ← free, but too small for a 10KB process├──────────┤│ P3(5KB) │└──────────┘Total free: 7KB ← but no single contiguous block of 7KB exists!This is external fragmentation: plenty of free memory exists in total, but it’s too scattered to be useful for a large process. Techniques like compaction (shuffling processes around to merge holes) can help, but they are expensive operations.
Key trade-off to remember:
| Property | Fixed Partitioning | Variable Partitioning |
|---|---|---|
| Internal fragmentation | Yes | No |
| External fragmentation | No | Yes |
| Complexity | Low | Higher |
Problem 2: Physical vs Logical Addresses
Section titled “Problem 2: Physical vs Logical Addresses”In early architectures CPUs used to generate physical addresses to access RAM. What kind of problems did physical addresses create and how did memory management mechanisms solve these problems?
Instructor Solution
The use of physical addresses in early CPUs created two primary issues: a complete lack of memory protection and extreme difficulty with relocation. Since every process had direct access to the hardware’s address lines, a single error or malicious instruction could overwrite the Operating System’s kernel or another program’s data, leading to frequent system crashes. Furthermore, programs had to be compiled for specific, hard-coded memory locations, making it impossible to run multiple instances of a program or move a process to a different part of RAM to optimize space. Memory management solved these problems by introducing Logical Address Spaces and the Memory Management Unit (MMU), which act as an abstraction layer. This allows the CPU to work with “virtual” addresses that the hardware maps to physical RAM at runtime, ensuring processes are isolated from one another and can be loaded into any available memory fragment.
Private Concise answer (by LLM)
Using physical addresses meant any process could directly corrupt any other’s memory or the OS kernel, and programs had to be compiled for specific fixed RAM locations. Logical addresses and the MMU solve both by giving each process an isolated virtual address space that is transparently remapped to arbitrary physical locations at runtime.
Concise answer (by LLM):
Physical addresses gave every process direct access to RAM, breaking memory protection (any buggy process could corrupt the OS or other processes) and making relocation nearly impossible (programs were compiled for fixed addresses). The MMU and logical address spaces solve both by giving each process a private virtual address space that the hardware transparently maps to arbitrary physical locations at runtime.
Elaboration (by LLM)
To understand why physical addresses are dangerous, imagine a classroom where every student (process) can directly walk up to any desk (memory location) in the room, including the teacher’s desk (OS kernel). There’s nothing stopping a student from accidentally (or intentionally) disturbing someone else’s work.
Problem 1: No Memory Protection
With physical addressing, every program can read or write any byte of RAM:
Physical RAM:┌──────────────────┐ 0x0000│ OS Kernel │ ← Process A can overwrite this!├──────────────────┤ 0x1000│ Process A │├──────────────────┤ 0x3000│ Process B │ ← Process A can overwrite this too!└──────────────────┘ 0x8000
A bug in Process A: MOV [0x0500], 0xFF ← accidentally corrupts OS kernel data → system crashA single buggy pointer dereference in any program could wipe out the OS or another user’s program.
Problem 2: Relocation Difficulty
Programs compiled for physical addresses are “nailed down” to a specific location. If the compiler decided your program lives at address 0x3000, every internal reference (function calls, global variables, jump targets) is hard-coded to use 0x3000-relative addresses:
Compiled program (expecting to live at 0x3000): JMP 0x3010 ← jump to main() MOV AX, [0x3050] ← load global variable
If loaded at 0x5000 instead: JMP 0x3010 ← still jumps to 0x3010 — WRONG address! MOV AX, [0x3050] ← reads from 0x3050 — WRONG address!This makes it nearly impossible to run two copies of the same program simultaneously (they’d both try to occupy the same address range) or to move a running process to a different region of RAM.
The Solution: Logical Addresses + MMU
The MMU introduces an indirection layer. Each process generates logical (virtual) addresses starting from 0, and the MMU transparently translates them to physical addresses at runtime:
Process A thinks its address space looks like: 0x0000 → 0x7FFF (its own private world)
Process B thinks its address space looks like: 0x0000 → 0x7FFF (its own private world)
MMU maps them to different physical locations: Process A's 0x0000 → Physical 0x3000 Process B's 0x0000 → Physical 0x8000This simultaneously solves both problems: processes are isolated (no process can generate a physical address belonging to another process) and programs can be relocated freely since the logical-to-physical mapping can be adjusted without touching the program’s code.
Problem 3: MMU with Base and Limit Registers
Section titled “Problem 3: MMU with Base and Limit Registers”Briefly explain how memory management with variable partitioning and a simple MMU with base and limit registers works. Does this memory management scheme use physical or logical addresses?
Instructor Solution
In this memory management scheme, each process is allocated a single, contiguous block of memory of the exact size it requires (variable partitioning). To manage this, the Memory Management Unit (MMU) uses two hardware registers: the base register, which stores the smallest physical address of the allocated partition, and the limit register, which stores the total size (range) of that partition. When a process runs, the CPU generates a logical address (also called a virtual address). The MMU first checks if this logical address is less than the value in the limit register to ensure the process isn’t accessing memory outside its bounds. If the check passes, the MMU adds the logical address to the base register to calculate the actual physical address in RAM. Therefore, this scheme uses logical addresses from the perspective of the CPU and the running program, while the MMU translates them into physical addresses for the hardware.
Private Concise answer (by LLM)
The base register holds the physical start of a process’s memory block and the limit register holds its size; for each access the MMU rejects any logical address ≥ limit (triggering a bounds violation), then adds the base to the accepted address to produce the physical address.
Concise answer (by LLM):
In variable partitioning with a base/limit MMU, each process gets one contiguous block of physical memory; the CPU uses logical addresses starting from zero, the MMU checks the address is within the limit register, then adds the base register to produce the physical address.
Elaboration (by LLM)
This is the simplest possible form of hardware-assisted memory protection and relocation. Think of the base and limit registers as defining a “window” into physical RAM that each process is allowed to see.
The Two Registers
When the OS schedules a process to run, it loads two values into the MMU’s hardware registers:
- Base register: the physical start address of this process’s memory partition
- Limit register: the size (length) of the partition
Physical RAM:┌──────────────────┐ 0x0000│ OS Kernel │├──────────────────┤ 0x2000 ← base = 0x2000│ ││ Process A │ limit = 0x3000 (size)│ │├──────────────────┤ 0x5000 ← base + limit│ free / other │└──────────────────┘Address Translation Step by Step
When Process A executes an instruction that accesses logical address L:
Step 1: Bounds check Is L < limit? Yes → safe, continue No → segmentation fault / protection error (OS kills process)
Step 2: Translation physical address = base + L
Example: base = 0x2000 limit = 0x3000 L = 0x0500
Bounds check: 0x0500 < 0x3000 ✅ Physical addr: 0x2000 + 0x0500 = 0x2500Full Hardware Flow Diagram
CPU generates logical address L │ ▼ ┌─────────────┐ │ L < limit? │──── No ──→ Trap to OS (segfault) └─────────────┘ │ Yes ▼ physical = base + L │ ▼ RAM accessContext Switching
When the OS switches from Process A to Process B, it saves Process A’s base/limit and loads Process B’s base/limit into the registers. From that moment on, all logical addresses are translated relative to Process B’s partition — neither process can ever “see” the other’s memory, because the bounds check prevents it.
Problem 4: Virtual vs Physical Addresses
Section titled “Problem 4: Virtual vs Physical Addresses”What’s a virtual address? How does it differ from a physical address? Briefly explain.
Instructor Solution
A virtual address (also called a logical address) is an address generated by the CPU from the perspective of a running process. It exists within a process’s private, abstracted address space, allowing the program to act as if it has its own dedicated range of memory starting from zero. In contrast, a physical address refers to an actual, specific location in the hardware’s RAM chips. The key difference lies in abstraction and isolation: while multiple processes might use the same virtual address (e.g., 0x400500), the Memory Management Unit (MMU) translates those identical virtual addresses into distinct physical addresses. This decoupling allows the operating system to move data around in RAM, swap it to disk, or protect one process’s memory from another without the program needing to know its true physical location.
Private Concise answer (by LLM)
A virtual address exists only in a process’s private address space (each starts at 0), while a physical address refers to an actual hardware RAM location; the MMU translates between the two, allowing multiple processes to use identical virtual addresses that map to distinct physical locations.
Concise answer (by LLM):
A virtual address is what the CPU generates — each process has its own private address space starting from 0, so multiple processes can share the same virtual address without conflict. The MMU translates virtual addresses to unique physical addresses at runtime, decoupling the program from actual RAM locations.
Elaboration (by LLM)
A useful analogy: a virtual address is like a seat number on your airplane ticket (Row 14, Seat C), while a physical address is the actual physical seat bolted to the airplane floor. Different flights (processes) can all have a “Row 14, Seat C” on their tickets, but each ticket maps to a specific seat on a specific aircraft.
Side-by-Side Comparison
Virtual Address
- Generated by the CPU/program
- Starts at 0 for every process
- Private to each process
- Does not correspond to a real hardware wire
- What the programmer/compiler sees
Physical Address
- The actual address sent to RAM chips
- Unique across the whole system
- Managed by the OS + MMU
- Corresponds to real hardware pins
- Hidden from the program
Why the Same Virtual Address Can Exist in Multiple Processes
Process A (virtual space): Process B (virtual space): 0x0000: [code] 0x0000: [code] 0x4000: [data] 0x4000: [data] 0x8000: [stack] 0x8000: [stack]
↓ MMU translation ↓
Physical RAM: 0x1000: Process A's code 0x5000: Process A's data 0x9000: Process A's stack 0x2000: Process B's code 0x6000: Process B's data 0xA000: Process B's stackBoth processes use virtual address 0x4000 for their data, but the MMU translates them to completely different physical locations (0x5000 and 0x6000). Neither process has any idea the other exists.
Practical Benefits of this Decoupling
- Security: A process cannot access another process’s physical memory because it can only generate addresses within its own virtual space.
- Simplicity: Compilers always generate code as if the program starts at address 0. No relocation needed.
- Flexibility: The OS can move data to disk (swap), rearrange physical memory, or share read-only pages (like shared libraries) between processes — all without the program knowing.
Problem 5: Same Address in Multiple Processes
Section titled “Problem 5: Same Address in Multiple Processes”Assume you have a simple program that declares a global variable and prints its address on the screen. When you run two copies of this program simultaneously, you see that both programs print the same address on the screen. How is this possible? Briefly explain.
Instructor Solution
This is possible because the address printed by the program is a logical address (or virtual address) rather than a physical location in the RAM chips. In modern operating systems, each process is provided with its own isolated Virtual Address Space, which is a contiguous range of addresses starting from zero that the process “believes” it owns entirely. When you run two copies of the same program, the Operating System and the Memory Management Unit (MMU) map the same logical address in each process to two entirely different locations in physical memory. This abstraction ensures that even though both programs report an address like 0x400500, the hardware-level translation redirects Process A’s data to one physical frame and Process B’s data to another, preventing them from interfering with each other.
Private Concise answer (by LLM)
The printed address is a virtual address, not a physical one; both processes have their own isolated address spaces, so both can hold the same virtual address for their global variable while the MMU maps each to a different physical frame.
Concise answer (by LLM):
Both copies print the same address because they’re printing a virtual address — each process has its own independent virtual address space, and the MMU maps that same virtual address to different physical locations for each process.
Elaboration (by LLM)
This is a classic “aha” moment for students new to virtual memory. Let’s trace exactly what happens when you run the following program twice:
#include <stdio.h>int global_var = 42;
int main() { printf("Address of global_var: %p\n", (void*)&global_var); // keep running so both instances overlap in time while(1) {}}Both instances print something like:
# Terminal 1 (PID 1001):Address of global_var: 0x601040
# Terminal 2 (PID 1002):Address of global_var: 0x601040 ← same address!Why? Because both instances are compiled identically. The compiler decided the global variable lives at virtual address 0x601040 in both cases — and that decision is baked into the binary. When each process is loaded, the OS gives each process its own independent virtual address space, both starting from 0.
What's Actually Happening in Physical RAM
Virtual address 0x601040 in each process maps to different physical locations:
Process 1001's page table: virtual 0x601040 → physical 0x3F2040
Process 1002's page table: virtual 0x601040 → physical 0x7A1040
Physical RAM: 0x3F2040: [ 42 ] ← Process 1001's copy of global_var 0x7A1040: [ 42 ] ← Process 1002's copy of global_varIf Process 1001 sets global_var = 99, Process 1002 still reads 42 from its own independent copy. They are completely isolated despite sharing the same virtual address.
Problem 6: Segmentation
Section titled “Problem 6: Segmentation”Briefly explain the motivation behind segmentation for memory management and how it works?
Instructor Solution
The primary motivation behind segmentation is to align memory management with the programmer’s view of a process. Instead of treating memory as a linear array of bytes, segmentation divides it into logical units called segments, such as the code, data, stack, and shared libraries. This allows each segment to grow or shrink independently and enables specific protection attributes (e.g., “read-only” for code segments or “read-write” for data segments) to be applied naturally to these logical blocks. Segmentation works by using a segment table, where each entry contains a base (the starting physical address) and a limit (the length of the segment). When the CPU generates a logical address, it consists of a segment number and an offset. The hardware uses the segment number as an index into the table to find the base address, checks that the offset is within the limit, and then adds the offset to the base to produce the final physical address.
Private Concise answer (by LLM)
Segmentation maps logical program regions (code, data, stack) as separate variable-size segments, each with its own base, limit, and access permissions; a virtual address encodes both a segment number and an offset, enabling independent per-region growth and protection that a single base/limit register pair cannot provide.
Concise answer (by LLM):
Segmentation divides a process’s memory into logical units (code, data, stack, etc.) each with its own base, limit, and permission bits; virtual addresses carry a segment number and offset, and the MMU looks up the segment table to translate them, enabling independent per-segment growth and access control.
Elaboration (by LLM)
The base-and-limit register scheme (Problem 3) gives each process one contiguous block of memory. But a real process has parts with very different characteristics — code that should never be written to, a stack that grows downward, a heap that grows upward, shared libraries used by many processes. Segmentation acknowledges these logical divisions explicitly.
The Programmer's View of a Process
Process memory (logical view):┌──────────────┐│ Code/Text │ read-only, fixed size├──────────────┤│ Data │ read-write, initialized globals├──────────────┤│ Heap │ grows ↓ (dynamic allocations)│ ↓ ││ ... ││ ↑ ││ Stack │ grows ↑ (function calls)└──────────────┘Each of these is a segment, and segmentation maps them independently into physical memory.
The Segment Table
Each process has a segment table. Each row holds the base and limit for one segment:
| Segment # | Name | Base (Physical) | Limit (Size) | Permissions |
|---|---|---|---|---|
| 0 | Code | 0x4000 | 0x1000 | read, exec |
| 1 | Data | 0x9000 | 0x0800 | read, write |
| 2 | Stack | 0x2000 | 0x0500 | read, write |
Address Translation
A logical address in a segmented system is a pair: (segment number, offset)
Logical address: (segment=1, offset=0x0200)
Step 1: Look up segment 1 in table → base=0x9000, limit=0x0800Step 2: Bounds check: 0x0200 < 0x0800 ✅Step 3: Physical address = 0x9000 + 0x0200 = 0x9200If a process tries to access (segment=0, offset=0x0400) with a write, the hardware checks permissions, sees “read, exec only” for segment 0, and raises a protection fault — exactly what you want to prevent code modification.
Segmentation vs Base/Limit
| Feature | Base/Limit (1 register pair) | Segmentation (segment table) |
|---|---|---|
| Number of regions | 1 per process | Many per process |
| Per-region permissions | No | Yes |
| Independent growth | No | Yes |
| External fragmentation | Yes | Yes (still present) |
Problem 7: Process Swapping
Section titled “Problem 7: Process Swapping”Briefly explain what process swapping is and what it was used for? In modern paging systems, is process swapping employed? Why or why not?
Instructor Solution
Process swapping is a memory management technique where an entire process is moved from main memory (RAM) to a secondary storage “backing store” (like a hard disk) and then brought back into memory later to continue execution. Its primary motivation was to increase multiprogramming levels in systems with limited RAM; by swapping out idle or blocked processes, the OS could free up space to load and run other processes that were ready to execute. In modern systems, traditional “entire-process” swapping is rarely employed. Instead, it has been replaced by demand paging, which swaps individual pages rather than the whole process. Modern OSs only swap out specific parts of a process that aren’t currently being used, which is far more efficient because it reduces the amount of I/O required and allows the system to run programs that are actually larger than the total physical RAM available.
Private Concise answer (by LLM)
Process swapping transfers an entire process to disk to free RAM for other processes — expensive due to the large I/O cost; modern OSes replaced it with demand paging, which moves only individual pages on a fault-driven basis, dramatically reducing I/O and enabling programs larger than physical RAM.
Concise answer (by LLM):
Process swapping moves an entire process between RAM and disk to free memory for others; modern systems replaced it with demand paging, which swaps individual pages rather than whole processes, reducing I/O and enabling programs larger than physical RAM.
Elaboration (by LLM)
Why Swapping Was Needed
Early systems had very limited RAM (often measured in kilobytes). If you wanted to run 5 programs but only had room for 3 in RAM at once, the OS needed a way to “park” the others. The solution: copy the entire process to disk when it’s idle, freeing its RAM for another process.
RAM (limited): Disk (backing store):┌────────────┐ ┌────────────────────┐│ Process A │ ←── running │ Process C (saved) │├────────────┤ │ Process D (saved) ││ Process B │ ←── waiting └────────────────────┘└────────────┘
OS decides to run Process C: 1. Swap out Process B → write all of B's RAM to disk 2. Swap in Process C ← read all of C's data from disk 3. Resume Process CThe Problem with Whole-Process Swapping
Swapping an entire process is extremely slow because disk I/O is orders of magnitude slower than RAM access. If a process uses 100MB, the OS must transfer 100MB to/from disk on every swap — even if the process only actively uses 1MB of that.
Speed comparison: RAM access: ~100 nanoseconds SSD access: ~100 microseconds (1,000× slower) HDD access: ~10 milliseconds (100,000× slower)Modern Solution: Demand Paging
Instead of swapping the whole process, demand paging only moves individual pages (typically 4KB chunks) between RAM and disk — and only pages that haven’t been used recently:
Process's virtual pages (256 total):┌──────────────────────────────────────────────────────┐│ Page 0 [in RAM] │ Page 1 [in RAM] │ Page 2 [on disk] │ ...└──────────────────────────────────────────────────────┘
Only actively-used pages stay in RAM.If page 2 is needed → page fault → OS loads just that one page.If RAM is full → evict one unused page to disk → load the needed page.This allows running programs larger than physical RAM and makes swapping I/O proportional to actual usage rather than total process size.
Problem 8: External Fragmentation
Section titled “Problem 8: External Fragmentation”What’s external fragmentation in memory management? Is external fragmentation a problem in paging systems? Briefly explain.
Instructor Solution
External fragmentation occurs when total free memory is sufficient to satisfy a process’s request, but the available space is broken into small, non-contiguous blocks (holes) scattered throughout the RAM. This prevents the operating system from allocating memory to a new process because no single “hole” is large enough to hold it. In paging systems, external fragmentation is not a problem. This is because paging allows a process’s logical address space to be non-contiguous; a process can be scattered across any available physical memory frames. Since any free frame can be used to hold any page of a process, the system never needs a single, large contiguous block of physical RAM to load a program. However, paging can still suffer from internal fragmentation, which occurs if a process’s size is not an exact multiple of the fixed page size, leaving wasted space in the final frame.
Private Concise answer (by LLM)
External fragmentation is when total free memory suffices but no single contiguous block is large enough; paging eliminates it because all frames are uniform in size and any free frame can hold any page — though it introduces bounded internal fragmentation in each process’s last frame.
Concise answer (by LLM):
External fragmentation is when enough total free memory exists but no single contiguous block is large enough; paging eliminates it by letting any free frame hold any page, though it introduces internal fragmentation in the last frame of each process.
Elaboration (by LLM)
External Fragmentation Visualized
The defining characteristic of external fragmentation is: free memory exists, but it’s not usable because it’s not contiguous.
RAM state after several processes have started and exited:
┌─────────────┐ 0KB│ Process A │ (8KB)├─────────────┤ 8KB│ Hole │ (3KB) ← free├─────────────┤ 11KB│ Process B │ (6KB)├─────────────┤ 17KB│ Hole │ (4KB) ← free├─────────────┤ 21KB│ Process C │ (5KB)└─────────────┘ 26KB
Total free = 7KB.New process needs 6KB.No single hole is ≥ 6KB → allocation fails!(This is external fragmentation.)Why Paging Eliminates External Fragmentation
Paging breaks both the process’s logical memory and physical RAM into fixed-size units (pages and frames). Every free frame is exactly the same size, so any free frame can hold any page:
Physical RAM (4KB frames):
┌───────┐ Frame 0: Process X, Page 0├───────┤ Frame 1: [FREE]├───────┤ Frame 2: Process Y, Page 0├───────┤ Frame 3: [FREE]├───────┤ Frame 4: [FREE]├───────┤ Frame 5: Process X, Page 1 ← pages don't need to be contiguous!└───────┘
New process needs 3 pages → uses frames 1, 3, 4.No need for contiguous blocks!Because the page table handles the mapping from logical (contiguous) to physical (scattered) addresses, the process never knows its pages are spread all over RAM.
The Trade-off: Internal Fragmentation
Paging trades external fragmentation for a smaller, bounded internal fragmentation problem:
Process size: 13KBPage size: 4KB
Pages needed: ⌈13KB / 4KB⌉ = 4 frames allocated (16KB total)Wasted space: 16KB - 13KB = 3KB ← internal fragmentation (in last frame only)Internal fragmentation is bounded by at most one page size per process, which is a much smaller and more predictable waste than external fragmentation.
Problem 9: Internal Fragmentation
Section titled “Problem 9: Internal Fragmentation”What’s internal fragmentation? In what memory management method does internal fragmentation occur? Briefly explain.
Instructor Solution
Internal fragmentation occurs when memory is allocated in fixed-sized blocks or partitions that are larger than the actual amount of memory requested by a process. The unused space remains “trapped” inside the allocated partition and cannot be used by other processes, leading to wasted RAM. This phenomenon primarily occurs in paging systems, where memory is allocated in fixed-size units called frames, and internal fragmentation typically occurs in the last page of a process if the process’s total size is not an exact multiple of the page size.
Private Concise answer (by LLM)
Internal fragmentation is unused space trapped inside an allocated fixed-size block that cannot be given to any other process; in paging, it appears only in the last frame of each process and is bounded by at most page_size − 1 bytes.
Concise answer (by LLM):
Internal fragmentation is wasted memory trapped inside allocated fixed-size blocks — in paging, it appears in the last frame of a process whenever the process size isn’t a multiple of the page size.
Elaboration (by LLM)
The word “internal” is the key: the wasted space is trapped inside an allocated unit. No other process can claim it, even though it’s technically free.
Concrete Example
Say the system uses a page size of 4KB (4096 bytes) and a process needs exactly 9000 bytes of memory:
Frame 0: [████████████████████████] (4096 bytes — fully used)Frame 1: [████████████████████████] (4096 bytes — fully used)Frame 2: [████████░░░░░░░░░░░░░░░░] (808 bytes used, 3288 bytes wasted) ↑ process data ends here ↑ this space is locked inside the frameThe 3288 bytes in Frame 2 cannot be given to another process — the entire frame is “owned” by this process.
Where Else Does Internal Fragmentation Appear?
While paging is the primary context in OS courses, internal fragmentation also appears in:
- Fixed-partition memory schemes: a 3KB process placed in a 10KB fixed partition wastes 7KB internally.
- Memory allocators (like
malloc): allocators often round up requests to alignment boundaries, wasting a few bytes per allocation.
Upper Bound on Waste
An important property of internal fragmentation in paging: the waste per process is at most one page minus one byte (it only occurs in the last page). If the page size is 4KB, no process wastes more than 4095 bytes this way — a bounded and predictable amount, unlike external fragmentation.
Problem 10: Memory Allocation Strategies
Section titled “Problem 10: Memory Allocation Strategies”Consider a system that uses variable partitioning for memory management. Assume that the system has 32KB total memory and the current snapshot of the memory is as follows:
Assume that the following 2 processes arrive in the given order: P4(4KB), P5(1KB). For each of the following memory management techniques, show the final state of the memory after the processes are allocated memory. (1) First fit, (2) Best Fit, (3) Worst fit.
Instructor Solution
(1) First fit
(2) Best fit
(3) Worst fit
Elaboration (by LLM)
Let’s walk through each algorithm step by step, starting from the same initial state:
Initial memory (32KB total):┌──────────┐│ P1 (3KB)│├──────────┤│ Hole (5KB)│ ← Hole A├──────────┤│ P2 (7KB)│├──────────┤│ Hole(10KB)│ ← Hole B├──────────┤│ P3 (3KB)│├──────────┤│ Hole (4KB)│ ← Hole C└──────────┘
Processes to allocate (in order): P4(4KB), then P5(1KB)Available holes: A=5KB, B=10KB, C=4KB(1) First Fit
Rule: scan from the beginning of memory and use the first hole that is large enough.
- P4 (4KB): Scan → Hole A (5KB) ≥ 4KB ✅ → place P4 in Hole A. Hole A shrinks to 1KB.
- P5 (1KB): Scan → remaining 1KB of (former) Hole A ≥ 1KB ✅ → place P5 there. Hole A is now completely filled.
After First Fit:┌──────────┐│ P1 (3KB)│├──────────┤│ P4 (4KB)│ ← placed in Hole A (used 4 of 5KB)├──────────┤│ P5 (1KB)│ ← placed in remaining 1KB of Hole A├──────────┤│ P2 (7KB)│├──────────┤│ Hole(10KB)│ ← Hole B unchanged├──────────┤│ P3 (3KB)│├──────────┤│ Hole (4KB)│ ← Hole C unchanged└──────────┘The 5KB hole was a perfect fit for P4+P5 together (4+1 = 5KB), leaving no waste from Hole A.
(2) Best Fit
Rule: search all holes and choose the smallest hole that is still large enough (minimizes leftover waste).
- P4 (4KB): All holes — A=5KB, B=10KB, C=4KB. Smallest that fits 4KB → Hole C (4KB, exact fit!) → place P4 in Hole C. Hole C is now gone (0KB remaining).
- P5 (1KB): Remaining holes — A=5KB, B=10KB. Smallest that fits 1KB → Hole A (5KB) → place P5 in Hole A. Hole A shrinks to 4KB.
After Best Fit:┌──────────┐│ P1 (3KB)│├──────────┤│ P5 (1KB)│ ← placed in Hole A (used 1 of 5KB)├──────────┤│ Hole (4KB)│ ← 4KB remaining in Hole A├──────────┤│ P2 (7KB)│├──────────┤│ Hole(10KB)│ ← Hole B unchanged├──────────┤│ P3 (3KB)│├──────────┤│ P4 (4KB)│ ← placed in Hole C (exact fit, no waste)└──────────┘(3) Worst Fit
Rule: search all holes and choose the largest hole (leaves the largest possible remainder, hoping it stays useful).
- P4 (4KB): All holes — A=5KB, B=10KB, C=4KB. Largest → Hole B (10KB) → place P4 in Hole B. Hole B shrinks to 6KB.
- P5 (1KB): Remaining holes — A=5KB, B(remaining)=6KB, C=4KB. Largest → Hole B (6KB) → place P5 in Hole B. Hole B shrinks to 5KB.
After Worst Fit:┌──────────┐│ P1 (3KB)│├──────────┤│ Hole (5KB)│ ← Hole A unchanged├──────────┤│ P2 (7KB)│├──────────┤│ P4 (4KB)│ ← placed in Hole B├──────────┤│ P5 (1KB)│ ← placed in remaining Hole B├──────────┤│ Hole (5KB)│ ← 5KB remaining in Hole B├──────────┤│ P3 (3KB)│├──────────┤│ Hole (4KB)│ ← Hole C unchanged└──────────┘Summary Comparison
| Algorithm | P4 placed in | P5 placed in | Holes remaining |
|---|---|---|---|
| First Fit | Hole A (5KB) | Hole A remainder (1KB) | B=10KB, C=4KB |
| Best Fit | Hole C (4KB) | Hole A (5KB) | A remainder=4KB, B=10KB |
| Worst Fit | Hole B (10KB) | Hole B remainder (6KB) | A=5KB, B remainder=5KB, C=4KB |
Problem 11: First-Fit, Best-Fit, Worst-Fit
Section titled “Problem 11: First-Fit, Best-Fit, Worst-Fit”Given free memory partitions of 100K, 500K, 200K, 300K and 600K (in order) how would each of the First-fit, Best-fit, and Worst-fit algorithms place processes of 212K, 417K, 112K and 426K (in order)? Which algorithm makes the most efficient use of memory?
Instructor Solution
(1) First Fit
212K is placed in the 500K partition (leaving 288K).
417K is placed in the 600K partition (leaving 183K).
112K is placed in the remaining 288K partition (leaving 176K).
426K cannot be placed as no remaining partition is large enough.
(2) Best Fit
212K is placed in the 300K partition (leaving 88K).
417K is placed in the 500K partition (leaving 83K).
112K is placed in the 200K partition (leaving 88K).
426K is placed in the 600K partition (leaving 174K).
All processes are successfully placed.
(3) Worst Fit
212K is placed in the 600K partition (leaving 388K).
417K is placed in the 500K partition (leaving 83K).
112K is placed in the remaining 388K partition (leaving 276K).
426K cannot be placed as no remaining partition is large enough.
In this scenario, Best-fit is the most efficient algorithm because it is the only one that successfully allocates all four processes. While First-fit and Worst-fit fail to accommodate the final 426K process, Best-fit preserves larger contiguous blocks of memory for future use by selecting the smallest available partition that satisfies each request.
Elaboration (by LLM)
Let’s trace through each algorithm explicitly, step by step. Initial partitions (in order):
Partition index: [0] [1] [2] [3] [4]Free holes: 100K 500K 200K 300K 600KProcesses to allocate in order: 212K → 417K → 112K → 426K
(1) First Fit — Step by Step
Scan left to right; use the first hole that fits.
Allocate 212K: Scan: 100K ❌, 500K ✅ → place here 500K → 500K − 212K = 288K remaining
[100K] [288K] [200K] [300K] [600K]Allocate 417K: Scan: 100K ❌, 288K ❌, 200K ❌, 300K ❌, 600K ✅ 600K → 600K − 417K = 183K remaining
[100K] [288K] [200K] [300K] [183K]Allocate 112K: Scan: 100K ❌, 288K ✅ → place here 288K → 288K − 112K = 176K remaining
[100K] [176K] [200K] [300K] [183K]Allocate 426K: Scan: 100K ❌, 176K ❌, 200K ❌, 300K ❌, 183K ❌ → FAILS: no hole is ≥ 426K
(2) Best Fit — Step by Step
Search all holes; use the smallest one that is still large enough.
Allocate 212K: Eligible: 500K, 200K ❌ (200<212), 300K, 600K Smallest eligible: 300K → place here 300K − 212K = 88K remaining
[100K] [500K] [200K] [88K] [600K]Allocate 417K: Eligible: 500K, 600K Smallest eligible: 500K → place here 500K − 417K = 83K remaining
[100K] [83K] [200K] [88K] [600K]Allocate 112K: Eligible: 200K, 600K Smallest eligible: 200K → place here 200K − 112K = 88K remaining
[100K] [83K] [88K] [88K] [600K]Allocate 426K: Eligible: 600K 600K − 426K = 174K remaining
[100K] [83K] [88K] [88K] [174K]→ All 4 processes successfully placed ✅
(3) Worst Fit — Step by Step
Search all holes; use the largest one available.
Allocate 212K: Largest hole: 600K → place here 600K − 212K = 388K remaining
[100K] [500K] [200K] [300K] [388K]Allocate 417K: Largest hole: 500K → place here 500K − 417K = 83K remaining
[100K] [83K] [200K] [300K] [388K]Allocate 112K: Largest hole: 388K → place here 388K − 112K = 276K remaining
[100K] [83K] [200K] [300K] [276K]Allocate 426K: Eligible holes ≥ 426K: none (max is 300K) → FAILS: no hole is ≥ 426K
Results at a Glance
| Algorithm | 212K | 417K | 112K | 426K | All placed? |
|---|---|---|---|---|---|
| First Fit | 500K hole | 600K hole | 288K rem. | ❌ | No |
| Best Fit | 300K hole | 500K hole | 200K hole | 600K hole | Yes |
| Worst Fit | 600K hole | 500K hole | 388K rem. | ❌ | No |
Best Fit wins here because it conserves larger holes by always consuming the smallest viable one, keeping the 600K hole intact for the large 426K request. First Fit and Worst Fit both consumed large holes early, leaving no hole big enough for the final process.
Problem 12: Paging
Section titled “Problem 12: Paging”All modern memory management schemes use paging. Briefly explain the main motivation behind paging and if paging requires hardware support.
Instructor Solution
The main motivation behind paging is to eliminate external fragmentation and the need for contiguous memory allocation. By dividing physical memory into fixed-sized blocks called frames and logical memory into same-sized blocks called pages, the operating system can scatter a process’s data across any available frames in RAM. This ensures that as long as there are enough free frames anywhere in the system, a process can be loaded, regardless of whether those frames are adjacent to one another. Paging absolutely requires hardware support in the form of a Memory Management Unit (MMU). Because every memory access must be translated from a logical page number to a physical frame number at runtime, doing this purely via software would be far too slow. The MMU uses a page table and often a high-speed cache called a Translation Lookaside Buffer (TLB) to perform these address translations near-instantaneously, ensuring that the abstraction of virtual memory does not significantly degrade system performance.
Private Concise answer (by LLM)
Paging eliminates external fragmentation by fixing both logical and physical memory into equal-size pages and frames so any free frame can hold any page; hardware support (an MMU with a TLB) is essential because every single memory access requires a virtual-to-physical translation that must happen at CPU speed.
Concise answer (by LLM):
Paging eliminates external fragmentation by dividing both logical and physical memory into fixed-size pages and frames so any free frame can hold any page; it requires hardware support (an MMU and typically a TLB) since every memory access must be translated at runtime.
Elaboration (by LLM)
The Core Idea: Fixed-Size Units Everywhere
Paging works by dividing both logical memory and physical memory into equal fixed-size units:
- Logical memory → divided into pages (e.g., 4KB each)
- Physical memory → divided into frames (same size as pages)
A page can be stored in any free frame. The OS maintains a page table per process that records which frame holds each page.
Process's logical address space: Physical RAM:┌───────────┐ ┌───────────┐ Frame 0│ Page 0 │──────────────────────→ │ Page 2 │├───────────┤ ├───────────┤ Frame 1│ Page 1 │──────────────────────→ │ Page 0 │ (P's page 0 here)├───────────┤ ├───────────┤ Frame 2│ Page 2 │──────────────────────→ │ [free] │└───────────┘ ├───────────┤ Frame 3 │ Page 1 │ └───────────┘
Page table for this process: Page 0 → Frame 1 Page 1 → Frame 3 Page 2 → Frame 0The process’s pages are scattered across non-contiguous frames, but the process itself sees a seamless logical address space — no gaps.
Address Translation Mechanics
A logical address is split into two parts:
Logical address: 0x1500 (page size = 4KB = 0x1000)
Page number = 0x1500 / 0x1000 = 1 Page offset = 0x1500 % 0x1000 = 0x500
Page table: page 1 → frame 3 Frame 3 starts at physical address: 3 × 0x1000 = 0x3000
Physical address = 0x3000 + 0x500 = 0x3500Why Hardware Support is Essential
Every single memory instruction (load, store, instruction fetch) requires a page table lookup. A typical process performs millions of memory accesses per second. If each lookup required OS intervention (a software trap), the overhead would make the system unusably slow.
The MMU performs translation in hardware (nanoseconds). The TLB (Translation Lookaside Buffer) caches recent page→frame mappings so the page table in RAM doesn’t even need to be consulted on most accesses:
CPU issues logical address │ ▼ ┌──────────┐ │ TLB │──── Hit (cached) ──→ physical address (very fast, ~1 cycle) └──────────┘ │ Miss ▼ Page Table (in RAM) ──→ physical address (slower, ~100+ cycles) + update TLBTLB hit rates are typically >99% due to locality of reference — programs tend to access the same pages repeatedly over short time periods.
Problem 13: Paging Advantages and Disadvantages
Section titled “Problem 13: Paging Advantages and Disadvantages”List 1 advantage and 1 disadvantage of paging.
Instructor Solution
An advantage of paging is the elimination of external fragmentation, as any available free frame in physical memory can be allocated to any logical page, regardless of its location. A primary disadvantage is the internal fragmentation that occurs when a process’s size is not an exact multiple of the page size, leaving the last allocated frame partially empty and its remaining space unusable.
Private Concise answer (by LLM)
Paging’s main advantage is eliminating external fragmentation (any free frame can hold any page); its main disadvantage is internal fragmentation in the last frame of each process, wasting up to page_size − 1 bytes per process.
Concise answer (by LLM):
Paging’s main advantage is eliminating external fragmentation (any free frame works for any page); its main disadvantage is internal fragmentation in the last allocated frame when the process size isn’t a multiple of the page size.
Elaboration (by LLM)
Advantage: No External Fragmentation
Recall that external fragmentation is the situation where free memory exists in total, but no single contiguous block is large enough to satisfy a request. Paging completely eliminates this because contiguity is never required:
Physical RAM — after many allocations and deallocations:
┌──────────┐ Frame 0: [free]├──────────┤ Frame 1: Process X├──────────┤ Frame 2: [free]├──────────┤ Frame 3: [free]├──────────┤ Frame 4: Process Y└──────────┘ Frame 5: [free]
New process needs 3 pages → uses frames 0, 2, 3.Works perfectly even though they're not adjacent.Every free frame is equally usable for any page of any process. There is no “wasted” free memory due to fragmentation.
Disadvantage: Internal Fragmentation
Because memory is allocated in fixed page-size chunks, the last page allocated to a process is almost never completely full:
Page size: 4KB (4096 bytes)Process size: 9000 bytes
Allocated: 3 pages = 12,288 bytesUsed: 9,000 bytesWasted: 3,288 bytes ← internal fragmentation (trapped in last frame)This wasted space cannot be reclaimed by any other process for the lifetime of the owning process. For a single process the waste is at most page_size − 1 bytes — but at system scale, with thousands of processes, this can add up.
Other Notable Trade-offs
Beyond the primary advantage/disadvantage, it’s worth knowing that paging also introduces page table overhead — every process needs a page table stored in memory. With a 64-bit address space and 4KB pages, a flat (single-level) page table would require enormous amounts of RAM, which is one motivation for the multi-level page tables discussed in Problem 14.
Problem 14: Multi-Level Page Tables
Section titled “Problem 14: Multi-Level Page Tables”What’s the motivation behind multi-level page tables? Briefly explain.
Instructor Solution
The primary motivation behind multi-level page tables is to reduce the amount of physical memory required to store the page table itself. In a modern 64-bit system with a single-level “flat” page table, the table would be huge---potentially gigabytes in size---and would need to be stored contiguously in RAM for every running process, even if the process only uses a small fraction of its available virtual address space. Multi-level paging works by breaking the page table into a hierarchy (like a tree). The top-level table points to smaller, secondary page tables, which only need to be created and kept in RAM if the corresponding range of virtual addresses is actually being used by the process. This allows the operating system to leave large “holes” in a process’s address space unmapped, significantly saving memory by avoiding the storage of page table entries for unused virtual memory.
Private Concise answer (by LLM)
Flat page tables are impractically large because they allocate entries for every virtual page even if most are never used; multi-level page tables solve this by only allocating sub-tables for virtual address regions the process actually uses, making the structure sparse and memory-efficient.
Concise answer (by LLM):
Multi-level page tables avoid huge flat page tables by making the structure sparse — lower-level tables are only allocated for virtual address ranges the process actually uses, dramatically reducing memory overhead when most of the address space is empty.
Elaboration (by LLM)
The Problem: Flat Page Tables Are Huge
Let’s calculate how large a single-level (“flat”) page table would be for a 32-bit address space with 4KB pages:
If each page table entry (PTE) takes 4 bytes:
With 100 running processes, that’s 400MB just for page tables — and most of that space represents unused virtual address ranges. For 64-bit systems the situation is far worse.
The Insight: Most Virtual Space Is Unused
A typical process only uses a few regions of its virtual address space:
Virtual address space (simplified):0x00000000 ┌──────────┐ │ Code │ ← used ├──────────┤ │ Data │ ← used ├──────────┤ │ │ │ (empty) │ ← HUGE gap, 99%+ of address space │ │ ├──────────┤ │ Stack │ ← used0xFFFFFFFF └──────────┘A flat page table allocates entries for every virtual page, including the vast empty middle. A multi-level page table only allocates entries for the parts that are actually in use.
How Two-Level Paging Works
The page number is split into two parts: an outer index and an inner index.
32-bit address example (10 | 10 | 12 bit split):
Virtual Address: [ p1 (10 bits) | p2 (10 bits) | offset (12 bits) ]
Translation: 1. Use p1 to index into the outer (top-level) page table → get pointer to an inner page table (or "null" if unused) 2. Use p2 to index into that inner page table → get the physical frame number 3. Combine frame number + offset → physical addressOuter Page Table (1024 entries, always in RAM): [0]: → Inner Table A (for code/data region) [1]: → null ← no inner table needed! saves memory ... [1023]: → Inner Table B (for stack region)
Inner Table A (1024 entries, only for used region): page 0 → frame 42 page 1 → frame 17 ...
Inner Table B (1024 entries, only for stack region): page 0 → frame 99 ...The key saving: inner page tables are only allocated when that region of virtual address space is actually used. The vast empty middle of the address space requires no inner tables at all.
Visualizing the Memory Savings
Flat (1-level): Two-Level:All entries allocated: Only used regions have inner tables:
[entry][entry][entry]...(1M) Outer: [ptr][null][null]...[ptr]= 4MB per process ↓ ↓ Inner A Inner B (4KB) (4KB) = ~8KB per process (if only 2 regions used)Problem 15: Page Table Entry (PTE)
Section titled “Problem 15: Page Table Entry (PTE)”List 3 things that are stored in a Page Table Entry (PTE) and briefly explain what each is used for?
Instructor Solution
A Page Table Entry (PTE) typically stores the following three critical components to manage virtual-to-physical mapping:
-
Frame Number: This is the physical address of the page frame in RAM. It is used by the MMU to translate the logical page number into a specific physical location.
-
Present/Absent Bit (Valid/Invalid Bit): This bit indicates whether the page is currently loaded in physical memory. If the CPU attempts to access a page where this bit is “0” (absent), it triggers a page fault.
-
Protection Bits: These bits define the access rights for the page (e.g., Read-Only, Read/Write, or Execute). They are used by the hardware to ensure a process does not perform unauthorized operations, such as writing to a code segment.
Private Concise answer (by LLM)
A PTE stores three fields:
- Physical frame number: used by the MMU to translate the virtual page to a physical address
- Present/valid bit: if 0, the access triggers a page fault so the OS can load the page from disk
- Protection bits: read/write/execute permissions enforced by the hardware on every access
Concise answer (by LLM):
A PTE stores three fields:
- Physical frame number: maps the virtual page to a specific location in physical memory
- Present/valid bit: indicates whether the page is in RAM; if 0, triggers a page fault
- Protection bits: read/write/execute permissions enforced by the hardware on every access
Elaboration (by LLM)
A page table is the data structure that the OS and MMU use together to translate every virtual address a process generates into a real physical address. Each row in this table is one Page Table Entry (PTE), and it bundles together everything the hardware needs to make — or refuse — that translation.
Putting the Three Fields in Context
Think of a PTE as a small record card for one page of a process’s virtual memory:
┌─────────────────────────────────────────────────┐│ PTE for Virtual Page N ││ ││ Frame Number │ P/A Bit │ Protection Bits ││ (where it is) │ (is it │ (what's allowed) ││ │ loaded?) │ │└─────────────────────────────────────────────────┘1. Frame Number
When a process accesses a virtual address, the MMU splits it into two parts: the page number (which page?) and the offset (where inside that page?). The MMU uses the page number to look up the PTE, reads the frame number out of it, and glues the frame number together with the offset to produce the final physical address:
Virtual Address: [ Page Number | Offset ] | PTE Lookup | vPhysical Address: [ Frame Number | Offset ]2. Present/Absent (Valid/Invalid) Bit
This single bit answers: “Is this page actually in RAM right now?”
- 1 (Present): The frame number is valid; the MMU completes the translation normally.
- 0 (Absent): The page has been swapped to disk, or was never loaded. The MMU raises a page fault, handing control to the OS. The OS then fetches the page from disk, updates the PTE (sets the frame number and flips the bit to 1), and restarts the faulting instruction.
This mechanism is what makes demand paging possible — a process can have a large virtual address space even if only a fraction of its pages are in physical memory at any given moment.
3. Protection Bits
Protection bits act as a per-page access control list enforced entirely in hardware:
| Typical Bits | Meaning |
|---|---|
| R (Read) | Process may read from this page |
| W (Write) | Process may write to this page |
| X (Execute) | CPU may fetch instructions from this page |
If a process tries an operation that the protection bits forbid (e.g., writing to a read-only code page), the MMU raises a protection fault (segmentation fault from the process’s perspective). This is how the OS isolates a process’s code segment from accidental or malicious modification, and it is also the hardware foundation for Copy-on-Write (see Problem 17).
A More Complete PTE
Real PTEs contain additional bits beyond these three (e.g., a Dirty bit that records whether the page has been written since it was loaded, and a Referenced/Accessed bit for page replacement algorithms), but the frame number, present/absent bit, and protection bits are the three core fields that make the fundamental virtual-to-physical mapping work.
Problem 16 [Paging]: Page Table Size Calculation
Section titled “Problem 16 [Paging]: Page Table Size Calculation”A machine has 48-bit virtual addresses and 32-bit physical addresses with a page size of 8KB. (1) How many entries are needed for the page table? (2) How many frames are there in the physical memory?
Instructor Solution
For a machine with a 48-bit virtual address space and an 8KB page size (8 x 1024 = bytes), the following calculations apply:
-
Page Table Entries: The number of entries is determined by the total number of pages in the virtual address space. With 48-bit addresses, there are bytes of virtual memory. Dividing this by the page size results in entries.
-
Physical Frames: The number of frames is determined by the physical address space. With 32-bit addresses, there are bytes of physical RAM. Dividing this by the frame size (which equals the page size, bytes) results in = frames.
Elaboration (by LLM)
The key insight behind both calculations is the same: divide the total address space by the unit size, and work entirely in powers of 2 so that division becomes subtraction of exponents.
The Core Formula
The page size determines the offset. Because 8 KB bytes, the offset field is 13 bits wide — 13 bits are needed to address any single byte within a page.
Part 1: Number of Page Table Entries
The page table needs one entry per virtual page. The number of virtual pages equals the number of distinct page numbers in the virtual address space:
So the page table requires billion entries. This enormous number is why single-level flat page tables are impractical for large address spaces, and why multi-level or inverted page tables are used instead.
Part 2: Number of Physical Frames
The number of frames is determined by the physical address space, not the virtual one. Here, physical addresses are 32 bits:
Summary Table
| Quantity | Calculation | Result |
|---|---|---|
| Page/frame size | bytes | 8 KB |
| Virtual pages (PTE count) | ||
| Physical frames |
Problem 17: Copy-on-Write (CoW)
Section titled “Problem 17: Copy-on-Write (CoW)”What is the effect of allowing two entries in a page table to point to the same page frame in memory? Explain how this effect can be used to decrease the amount of time and memory needed to copy a large amount of memory from one place to another. What would the effect of updating some byte in one page be on the other page? How would you make sure that updating a byte in one page does not change the same byte in the other page?
Instructor Solution
Allowing two page table entries to point to the same physical page frame results in shared memory, where different virtual addresses map to the exact same hardware location. This is used to decrease copy time and memory via a technique called Copy-on-Write (COW); instead of physically duplicating a large block of data, the OS simply creates a second pointer to the original frame, making the “copy” nearly instantaneous and requiring almost no additional RAM. If you update a byte in one page while they are sharing the same frame, the change would be immediately visible in the other page because both virtual addresses refer to the same physical bits. To prevent this and ensure that updating one does not change the other, the OS marks these shared pages as read-only. When a process attempts to write to the page, a page fault occurs; the OS then intercepts the request, physically copies the data to a new frame, updates the page table for the writing process to point to this new frame, and changes the permissions to read-write.
Private Concise answer (by LLM)
Two PTEs pointing to the same frame share memory; after fork(), Copy-on-Write marks shared frames read-only so a physical duplicate is only created when one process actually writes — a write triggers a protection fault, the OS copies the page to a new frame, and updates only the writing process’s PTE.
Concise answer (by LLM):
Two PTEs pointing to the same frame creates shared memory; Copy-on-Write exploits this after a fork() by marking shared frames read-only so that a physical copy is made only when either process actually writes to the page, avoiding expensive upfront duplication.
Elaboration (by LLM)
Copy-on-Write is a classic lazy evaluation optimization: defer expensive work until you know it’s actually necessary.
Step 1 — Sharing Instead of Copying
When a process calls fork(), the child needs its own copy of the parent’s address space. A naïve implementation would physically duplicate every page immediately — expensive for large processes. With CoW, the OS instead just creates a new page table for the child whose entries point to the same physical frames as the parent, and marks all those shared frames read-only in both page tables:
Parent Page Table Physical Memory Child Page Table┌──────────────┐ ┌──────────────┐│ VPN 0 → F42 │──────────────► Frame 42 ◄────────│ VPN 0 → F42 ││ (read-only) │ │ (read-only) ││ VPN 1 → F17 │──────────────► Frame 17 ◄────────│ VPN 1 → F17 ││ (read-only) │ │ (read-only) │└──────────────┘ └──────────────┘The “copy” takes microseconds regardless of how large the address space is, because no data is moved — only a new page table is built.
Step 2 — Write Triggers the Real Copy
As long as both processes only read the shared pages, nothing extra happens. The moment either process tries to write to a shared page, the hardware detects the read-only protection and raises a protection fault. The OS page-fault handler steps in:
-
- Allocates a new free frame.
- Copies the content of the original shared frame into the new frame.
- Updates the writing process’s PTE to point to the new frame.
- Sets the new frame’s protection back to read-write.
- Resumes the faulting instruction (the write now succeeds into the private copy).
After Child writes to VPN 0:
Parent Page Table Physical Memory Child Page Table┌──────────────┐ ┌──────────────┐│ VPN 0 → F42 │──────────────► Frame 42 │ VPN 0 → F99 │──► Frame 99│ (read-write)│ (parent's copy) │ (read-write)│ (child's copy)│ VPN 1 → F17 │──────────────► Frame 17 ◄────────│ VPN 1 → F17 ││ (read-only) │ │ (read-only) │└──────────────┘ └──────────────┘Pages that are never written by either process remain shared forever, saving both time and memory.
Why This Is Efficient
Many programs launched by fork() immediately call exec() to replace their image with a new program (the “fork-exec” pattern). In that case, the child never writes to any inherited page before discarding the whole address space. CoW means the OS never paid to copy a single byte of data in that common scenario.
Problem 18: Translation Lookaside Buffer (TLB)
Section titled “Problem 18: Translation Lookaside Buffer (TLB)”What’s Translation Look Aside Buffer (TLB)? What is it used for? Briefly explain.
Instructor Solution
A Translation Lookaside Buffer (TLB) is a small, high-speed hardware cache located within the CPU’s Memory Management Unit (MMU). It is specifically designed to store the most recently used mappings between virtual page numbers and physical frame numbers. Its primary purpose is to accelerate address translation. Without a TLB, every memory access by a program would require at least two physical memory lookups: one to read the page table entry from RAM and another to access the actual data. Because the TLB is made of faster associative memory (SRAM), the MMU can check it first; if the mapping is found (a TLB hit), the translation happens almost instantaneously, significantly reducing the performance overhead of paging.
Private Concise answer (by LLM)
The TLB is a small associative cache in the MMU that holds recently used virtual-to-physical mappings; on a TLB hit it resolves the translation in nanoseconds without touching the page table in RAM, reducing the overhead of address translation from multiple RAM accesses to near zero on the common case.
Concise answer (by LLM):
The TLB is a small, fast hardware cache in the MMU that stores recent virtual-to-physical address mappings, so the page table in RAM only needs to be consulted on a TLB miss rather than on every memory access.
Elaboration (by LLM)
The Problem the TLB Solves
Virtual memory is powerful, but it has a hidden cost: every memory access by a program requires the MMU to first look up the page table to find the physical address, and the page table itself lives in RAM. Without any optimization, this doubles (or more, with multi-level page tables) the number of RAM accesses per instruction:
Without TLB — accessing one byte of data:
1. RAM read → fetch PTE from page table (get frame number) 2. RAM read → fetch actual data from frame (the real access)
Result: 2× memory traffic for every single accessHow the TLB Fixes This
The TLB is a small associative cache (typically 64–1024 entries) built from fast SRAM inside the MMU. It stores recently used VPN→frame number mappings. On every memory access the MMU checks the TLB in parallel with or before going to RAM:
CPU generates virtual address │ ▼ TLB Lookup (nanoseconds) ┌─────────────┐ │ HIT? │──YES──► Use cached frame number directly │ │ → Only 1 RAM access needed (the data itself) │ NO (miss) │ └──────┬──────┘ │ ▼ Walk page table in RAM (1+ RAM accesses for PTE) │ ▼ Install VPN→frame in TLB │ ▼ Access data in RAMWhy It Works So Well: Locality
The TLB is effective because real programs exhibit temporal and spatial locality — they tend to access the same pages repeatedly over short time windows (loops, function calls, working on one data structure). A small TLB with 64–256 entries can achieve hit rates of 95–99%, which means the expensive page-table walk is the exception, not the rule.
Hit vs. Miss Cost (Rough Numbers)
| Scenario | Memory Accesses Required |
|---|---|
| TLB hit (single-level page table) | 1 (data only) |
| TLB miss, single-level page table | 2 (PTE + data) |
| TLB miss, 4-level page table (x86-64) | 5 (4 PTEs + data) |
This is why hardware designers invest in TLBs: the difference between a hit and a miss on a 4-level system is a 5× overhead in memory traffic.
Problem 19: TLB Flushing on Context Switch
Section titled “Problem 19: TLB Flushing on Context Switch”Why does an OS need to flush the TLB during a context switch? Can you propose a fix to this problem so that the TLB need not be flushed after a context switch?
Instructor Solution
An OS must flush the TLB during a context switch because TLB entries store virtual-to-physical mappings that are unique to a specific process. Since multiple processes use the same range of virtual addresses (e.g., both Process A and Process B might have data at address 0x4000), failing to flush the TLB would allow a new process to incorrectly use the cached physical mappings of the previous process, leading to data corruption or security breaches. To avoid flushing the TLB, hardware can implement Address Space Identifiers (ASIDs). With this fix, each TLB entry is tagged with a unique ID representing the process it belongs to. During a translation, the MMU only considers a TLB hit valid if the ASID in the entry matches the ASID of the currently running process. This allows mappings from multiple different processes to coexist in the TLB simultaneously, significantly improving performance by preserving cached translations across context switches.
Private Concise answer (by LLM)
TLB entries don’t inherently encode which process they belong to, so after a context switch the new process would use the previous process’s stale mappings — a security violation; ASIDs tag each entry with a process identifier so the MMU rejects hits from other processes without needing a full flush.
Concise answer (by LLM):
TLB entries must be flushed on a context switch because the cached virtual-to-physical mappings belong to the previous process; ASIDs fix this by tagging each TLB entry with the owning process’s ID, allowing entries from multiple processes to coexist without a flush.
Elaboration (by LLM)
Why the TLB Goes Stale After a Context Switch
Every process has its own page table, which means the same virtual address (e.g., 0x4000) maps to a different physical frame depending on which process is running. The TLB caches VPN → frame mappings, but it does not inherently know which process a cached entry belongs to.
Consider this scenario:
Process A runs: VPN 0x4 → Frame 200 (cached in TLB)
Context switch → Process B scheduled
Process B accesses virtual address 0x4000: TLB still holds: VPN 0x4 → Frame 200 ← WRONG! This is Process A's frame. Process B would read/write Process A's private memory.This is a correctness and security violation. The fix is to flush (invalidate) all TLB entries on every context switch, ensuring the new process always walks its own page table.
The Cost of Flushing
A TLB flush means the new process starts with a completely cold TLB. Every memory access it makes causes a TLB miss until its working set is rebuilt in the TLB. On systems with frequent context switches, this “TLB cold-start penalty” adds up to measurable performance loss.
The ASID Fix
Address Space Identifiers (ASIDs) tag each TLB entry with the process that owns it:
TLB Entry (with ASID):┌──────┬─────┬──────────────┬──────────────────┐│ ASID │ VPN │ Frame Number │ Protection Bits │└──────┴─────┴──────────────┴──────────────────┘When the MMU performs a lookup, a hit is only valid if both the VPN matches and the stored ASID matches the current process’s ASID. This lets TLB entries from multiple processes coexist safely:
TLB after running Process A, then Process B:
ASID=1, VPN=0x4 → Frame 200 (Process A's mapping, still valid) ASID=2, VPN=0x4 → Frame 075 (Process B's mapping)
When Process A is rescheduled, its ASID=1 entries are immediately usable again.On a context switch, the OS simply writes the new process’s ASID into a hardware register — no entries need to be invalidated. This is covered in more detail in Problem 20.
Problem 20: Address Space Identifiers (ASIDs)
Section titled “Problem 20: Address Space Identifiers (ASIDs)”We discussed in class that typically OSs keep a separate page table for each process. Since the logical address space of all processes are the same, the TLB must be flushed during a context switch. Suggest a fix that would NOT require the TLB to be flushed during a context switch. What are the implications of your suggestion?
Instructor Solution
The most effective fix is to implement Address Space Identifiers (ASIDs). This involves hardware support where each TLB entry is tagged with a unique ID corresponding to the process that owns that mapping. When a context switch occurs, the OS updates a hardware register with the ASID of the new process. During address translation, the TLB only registers a “hit” if the virtual page number matches and the tagged ASID matches the current process’s ID. This prevents one process from accidentally (or maliciously) using the cached translations of another. Implications of using ASIDs are:
-
Performance Gain: The system avoids the “TLB cold start” penalty after a context switch. Frequent processes can find their mappings already in the cache, significantly reducing memory access latency.
-
Hardware Complexity: The TLB must be slightly larger to store the ASID bits for every entry, and the MMU logic becomes more complex to perform the dual-matching (VPN + ASID).
-
Software Management: The Operating System must manage a pool of ASIDs. Since the number of ASID bits is limited (e.g., 8 or 12 bits), the OS must handle “ASID recycling” if the number of active processes exceeds the available hardware IDs.
Private Concise answer (by LLM)
ASIDs tag each TLB entry with the owning process’s ID so the MMU requires both VPN and ASID to match before accepting a hit, eliminating full TLB flushes on context switches. Implications:
- Performance gain: recently-resumed processes find their TLB entries intact, avoiding cold-start overhead
- Hardware complexity: TLB entries grow by ASID bits and the MMU must dual-match on VPN + ASID
- Software management: the OS manages a finite pool of ASID values and must handle recycling when active processes exceed the pool size
Concise answer (by LLM):
ASIDs tag each TLB entry with the owning process’s identifier so the MMU only accepts a hit when both VPN and ASID match, eliminating full TLB flushes on context switches. Implications:
- Performance: recently-resumed processes find their entries intact, avoiding TLB cold-start penalties
- Hardware complexity: TLB entries must store ASID bits; matching logic becomes dual (VPN + ASID)
- Software management: the OS manages a finite ASID pool and handles recycling when active processes exceed the available IDs
Elaboration (by LLM)
This problem is essentially a deeper dive into the ASID solution introduced in Problem 19. Here we focus on all three implications: the benefit, the hardware cost, and the OS management challenge.
How ASID Lookup Works Step by Step
On every memory access, the MMU performs:
1. Extract VPN from virtual address2. Compare VPN against all TLB entries simultaneously (associative lookup)3. For each VPN match, also check: stored ASID == current_ASID_register?4. Only declare a HIT if BOTH conditions are true5. On miss → walk page table, install new entry tagged with current ASIDThe current_ASID_register is updated by the OS during a context switch (a single register write — much cheaper than invalidating all TLB entries).
Implication 1: Performance Gain
Without ASIDs, every context switch flushes the TLB, meaning the next process pays a cold-start penalty for every memory access until its working set is re-warmed. With ASIDs, entries from recently-run processes survive across switches:
Without ASIDs: With ASIDs:Context switch Context switch → flush all TLB → write new ASID to register → Process B: 100% misses → Process B: hits its own old entries → warm-up time penalty → no penalty if B ran recentlyImplication 2: Hardware Complexity
Each TLB entry grows by the number of ASID bits (e.g., 8–12 bits). The associative comparator logic must now match on VPN and ASID simultaneously. This increases transistor count and potentially adds a small amount of latency to the TLB lookup path — though in practice this is negligible compared to the performance benefit.
Implication 3: ASID Recycling
With only 8 ASID bits, the hardware supports at most unique identifiers. If the system runs more than 256 concurrent processes, the OS must reuse (recycle) ASIDs:
-
- When a new process needs an ASID and the pool is exhausted, the OS picks a victim ASID to retire.
- All TLB entries tagged with the victim ASID must be flushed (a partial flush, not a full one).
- The ASID is then reassigned to the new process.
This recycling is managed entirely in software, and on systems with many processes it requires careful bookkeeping. Modern 64-bit architectures (e.g., ARM uses 16-bit ASIDs, giving 65,536 unique IDs) make exhaustion rare in practice.
Problem 21: Multi-Level Paging with 64-bit Addresses
Section titled “Problem 21: Multi-Level Paging with 64-bit Addresses”Why would it be a bad idea to use a 2-level page table (page directory and page table) for a processor that supports 64-bit memory addresses (using a 4KB page size)?
Instructor Solution
Using a 2-level page table for a 64-bit address space is a bad idea because the Page Directory itself would be too large to fit in memory. In a 64-bit system with 4KB () pages, you have 52 bits left for the page numbers. If you split this into only two levels (e.g., 26 bits for the directory and 26 bits for the page table):
-
Massive Top-Level Table: A directory with entries (assuming 8 bytes per entry) would require 512MB of contiguous physical memory just for the first level of the table.
-
Inefficiency: One of the primary goals of multi-level paging is to save memory by not allocating tables for unused address space. A 2-level structure in a 64-bit space forces a massive initial allocation, defeating the purpose of hierarchical paging.
To solve this, 64-bit processors (like x86-64) typically use 4-level or 5-level page tables, which break the address space into much smaller, manageable chunks at each level.
Private Concise answer (by LLM)
A 2-level page table for a 64-bit address space is impractical because the root directory alone would need 512 MB of contiguous RAM for a 26+26 bit split — defeating the purpose of hierarchical paging; 4-level structures like x86-64’s keep each table at exactly 4 KB (one frame) by using 9-bit indices.
Concise answer (by LLM):
A 2-level page table for a 64-bit address space is impractical because the top-level directory alone would require 512 MB of contiguous RAM, defeating the purpose of hierarchical paging; using 4 or more levels keeps each individual table small (fitting in a single 4 KB frame).
Elaboration (by LLM)
Why Multi-Level Page Tables Exist in the First Place
A flat (single-level) page table must have one entry for every virtual page, regardless of whether the process uses that page. For a 32-bit system with 4 KB pages, that’s entries × 4 bytes = 4 MB per process — large but tolerable.
Multi-level paging solves this by making the page table itself sparse: you only allocate second-level tables for regions of virtual address space that the process actually uses. Most of a process’s 64-bit address space is empty, so most second-level tables simply don’t exist.
The 2-Level Problem for 64-bit
With 4 KB () pages, a 64-bit address has 52 bits left for page numbers. Splitting evenly across two levels gives 26 bits each:
The top-level directory must have one entry for every possible Level-1 index — it cannot be sparse because it is the root and must always be fully present:
That’s 512 MB of contiguous RAM just for the page directory of a single process — before any actual data is stored. This defeats the entire purpose of hierarchical paging.
The Solution: More Levels with Smaller Tables
By adding more levels, each table at every level stays small (fitting comfortably in one or a few pages), and only the tables that cover actually-used address ranges are allocated:
x86-64 uses 4 levels (each index is 9 bits):
Virtual Address (48 bits used):┌────────┬────────┬────────┬────────┬──────────────┐│ PML4 │ PDPT │ PD │ PT │ Offset ││ 9 bits │ 9 bits │ 9 bits │ 9 bits │ 12 bits │└────────┴────────┴────────┴────────┴──────────────┘
Each table: 2^9 = 512 entries × 8 bytes = 4 KB ← fits in exactly one page frameNow the root table (PML4) is only 4 KB, and every level below it is allocated on demand. A process that uses only a small portion of its address space might need only a handful of page-table pages in total.
| Structure | Root Table Size | Practical? |
|---|---|---|
| 2-level, 64-bit (26+26 split) | 512 MB | No |
| 4-level, 64-bit (9+9+9+9 split) | 4 KB | Yes ✅ |
Problem 22 [Paging]: Two-Level Page Table Parameters
Section titled “Problem 22 [Paging]: Two-Level Page Table Parameters”Suppose your machine has 32 bit virtual addresses and uses a 2-level page table. Virtual addresses are split into a 9 bit top-level page table field, an 11 bit second level page table field, and an offset. How large are the pages? How many pages are there in the virtual address space? If the machine has 1GB physical memory, how many frames does the memory have?
Instructor Solution
Page Size: The offset uses the remaining bits not allocated to the page tables (32 - 9 - 11 = 12 bits). A 12-bit offset corresponds to a page size of bytes, which is 4KB.
Number of Pages: The total number of pages is determined by the bits used for the page table indices (9 + 11 = 20 bits). There are virtual pages.
Number of Frames: With 1GB ( bytes) of physical memory and a page (frame) size of 4KB ( bytes), the number of frames is / = frames.
Elaboration (by LLM)
Reading a Virtual Address Bit-by-Bit
The virtual address structure is given directly in the problem. Always start by drawing it out:
32-bit Virtual Address:┌───────────┬─────────────┬────────────────┐│ L1 Index │ L2 Index │ Offset ││ 9 bits │ 11 bits │ 12 bits │└───────────┴─────────────┴────────────────┘ bits 31-23 bits 22-12 bits 11-0
Total: 9 + 11 + 12 = 32 bits ✅Deriving Each Answer
Page Size
The offset field indexes within a single page. A 12-bit offset can address distinct byte positions, so:
Number of Virtual Pages
The page number portion of the address is everything above the offset: 9 + 11 = 20 bits. Each unique 20-bit page number is one virtual page:
This also equals total virtual address space ÷ page size: . ✅
Number of Physical Frames
Frames and pages are always the same size. With 1 GB = bytes of physical RAM:
Two-Level Table Walk
To see why two levels are used, consider the translation process for a virtual address:
-
- The MMU extracts the L1 index (bits 31–23) and indexes into the top-level Page Directory (which has entries).
- That entry points to a second-level Page Table. The MMU extracts the L2 index (bits 22–12) and indexes into it ( entries per second-level table).
- That entry contains the frame number, which is concatenated with the offset (bits 11–0) to form the physical address.
The top-level directory always has only 512 entries (= ), keeping it compact, while each second-level table covers pages. Second-level tables are only allocated for L1 entries that actually map real memory.
Problem 23 [EAT]: Effective Access Time with Page Faults
Section titled “Problem 23 [EAT]: Effective Access Time with Page Faults”Supposed we have an OS that uses paged virtual memory and further suppose that the OS stores the page table in CPU registers. (Thus, in this problem, you may assume that looking into the page table has negligible time cost.) Assume that it takes 8 milliseconds to service a page fault if an empty page frame is available or if the victim page is not dirty, and 20 milliseconds if the victim page is dirty. Suppose further that physical memory takes 1 microsecond to access. If the page replacement algorithm selects a dirty victim page 60 percent of the time, then what is the maximum acceptable page fault rate for an effective access time of no more than 2 microseconds? Express the page fault rate “p” as the probability that a memory reference results in a page fault.
Instructor Solution
To find the maximum acceptable page fault rate p, we use the formula for Effective Access Time (EAT), accounting for the two different page fault recovery times.
1. Identify the Variables
-
Memory Access Time (ma): 1 us
-
Service Time (Clean/Empty): 8 ms = 8,000 us
-
Service Time (Dirty): 20 ms = 20,000 us
-
Dirty Victim Probability: 60% (0.6)
-
Clean Victim Probability: 40% (0.4)
2. Calculate Average Page Fault Service Time (S)
S = (0.6 x 20,000 us) + (0.4 x 8,000 us)
S = 12,000 us + 3,200 us = 15,200 us
3. Solve for p using the EAT Formula
The EAT is defined as (1-p) x ma + p x S. We want EAT ≤ 2 us:
(1-p) x 1 + p x 15,200 ≤ 2
1 - p + 15,200p ≤ 2
15,199p ≤ 1
p ≤ 1/15,199
The maximum acceptable page fault rate p is 1 in 15,199 memory accesses.
Elaboration (by LLM)
Understanding the EAT Formula Intuitively
The Effective Access Time formula is a weighted average over two outcomes on every memory reference:
- With probability : no page fault — we just pay the normal memory access time .
- With probability : a page fault occurs — we pay the (large) average fault service time to bring the page in.
This makes intuitive sense: most accesses pay only , but a fraction of them instead pay the much larger fault service cost .
Why Dirty Pages Cost More
When the page replacement algorithm evicts a page frame, the dirty bit in the PTE tells the OS whether that frame’s contents differ from what’s on disk:
Clean victim (dirty bit = 0):
- Contents match disk — no write needed
- Simply overwrite the frame
- Service time: 8 ms (one disk read for the new page)
Dirty victim (dirty bit = 1):
- Contents differ from disk — must write back first
- Write old page to disk, then read new page
- Service time: 20 ms (one disk write + one disk read)
Since the replacement algorithm picks a dirty victim 60% of the time, the average service time is:
Solving the Inequality
We want , with and :
Problem 24 [Paging]: Logical and Physical Address Calculations
Section titled “Problem 24 [Paging]: Logical and Physical Address Calculations”Consider a logical address space of 8 pages of 1024 bytes each, mapped onto a physical memory of 32 frames.
(a) How many bits are there in the logical address?
(b) How many bits are there in the physical address?
(c) If the OS requires all pages of process to be in memory for it to run, how many processes can the OS load to memory at the same time?
Instructor Solution
(a)
There are 13 bits in the logical address. This is calculated by taking pages (for 8 pages) and adding bytes per page (for 1024 bytes), resulting in total addresses.
(b)
There are 15 bits in the physical address. This is calculated by taking frames (for 32 frames) and adding bytes per frame, resulting in total physical addresses.
(c)
If the OS requires all 8 pages of a process to be in memory simultaneously, the system can load 4 processes at the same time ((32 total frames)/(8 frames per process) = 4).
Elaboration (by LLM)
The General Recipe for Address Size Problems
A logical (virtual) address must encode two independent pieces of information: which page and where within that page. These pieces sit in separate bit fields, and the total address width is just their sum.
Similarly for physical addresses, replace “pages” with “frames.”
Part (a): Logical Address
| Field | Value | Bits needed |
|---|---|---|
| Page number | 8 pages | bits |
| Page offset | 1024 bytes/page | bits |
| Logical address total | 13 bits |
Logical Address (13 bits):┌───────────┬───────────────────┐│ Page # │ Offset ││ 3 bits │ 10 bits │└───────────┴───────────────────┘ (0–7) (0–1023)Part (b): Physical Address
The frame size always equals the page size (1024 bytes = bytes):
| Field | Value | Bits needed |
|---|---|---|
| Frame number | 32 frames | bits |
| Frame offset | 1024 bytes/frame | bits |
| Physical address total | 15 bits |
Physical Address (15 bits):┌───────────────┬───────────────────┐│ Frame # │ Offset ││ 5 bits │ 10 bits │└───────────────┴───────────────────┘ (0–31) (0–1023)Notice that the offset field is identical in both addresses (10 bits). The MMU replaces only the page number field with the frame number — the offset passes through unchanged.
Part (c): Concurrent Processes
This is a simple resource-division problem. Each process requires all 8 of its pages to be simultaneously resident in physical memory:
Problem 25 [EAT]: Single-Level Paging Parameters
Section titled “Problem 25 [EAT]: Single-Level Paging Parameters”Consider a 32-bit computer that has 1GB of physical memory. This machine employs single-level paging with 8192 byte frames.
(a) Show the parts of a virtual address, i.e., how many bits are used for offset, how many bits for indexing the page table?
(b) How many physical frames does the machine have? How many virtual pages does the machine have? How many bytes does a process page table occupy in memory?
(c) A user process generates the virtual address 0x345672F3. Compute the page number and offset from the virtual address and explain how the system establishes the corresponding physical location.
(d) Assume that memory access takes 100 microseconds. This machine uses TLB and TLB access takes 100 nano seconds. Assume a 90% TLB hit ration, compute the effective memory access time.
Instructor Solution
(a)
Offset: The page size is bytes, so 13 bits are used for the offset.
Page Table Index: With a 32-bit virtual address, the remaining 19 bits (32 - 13) are used for the page table index (page number).

(b)
Physical Frames: 1 GB / 8 KB = / = frames
Virtual Pages: / = pages
Page Table Size: Assuming a standard 4 bytes (32 bits) per Page Table Entry (PTE), the table occupies x 4 bytes = bytes = 2MB.
(c)
The offset is the last 13 bits (3 hex digits + 1 bit): 0x12F3.
The page number is the remaining upper bits: 0x34567 >> 1 (or 0x1A2B3).
Physical memory computation: The MMU extracts the page number, looks up the corresponding frame number in the Page Table (or TLB), and concatenates that frame number with the offset to form the physical address.
(d)
Effective Access Time (EAT) = 0.90 x (100 + 100,000) + 0.10 x (100 + 100,000 + 100,000)
EAT = 90,090 + 20,010 = 110,100 ns.
Elaboration (by LLM)
Part (a): Virtual Address Layout
8192 bytes = bytes, so the offset is 13 bits. The remaining bits are the page number:
32-bit Virtual Address:┌─────────────────────┬──────────────────────┐│ Page Number │ Offset ││ 19 bits │ 13 bits │└─────────────────────┴──────────────────────┘ bits 31 – 13 bits 12 – 0Part (b): Counting Frames, Pages, and Table Size
Physical frames:
Virtual pages:
Page table size:
Every process needs its own 2 MB page table resident in memory — a significant overhead for single-level paging.
Part (c): Parsing Virtual Address 0x345672F3
First, convert to binary to clearly see the bit boundary at bit 13:
0x345672F3 in binary (32 bits):
0011 0100 0101 0110 0111 0010 1111 0011 ─────────────────────────┬──────────── Page Number │ Offset bits 31 – 13 (19 bits) │ bits 12 – 0 (13 bits)The offset is the low 13 bits. Since 13 bits = 12 bits + 1 bit, we take the last 3 hex digits plus bit 12:
- Low 12 bits of
0x2F3=0x2F3; bit 12 is the1in0x12F3→ Offset =0x12F3
The page number is the upper 19 bits = 0x345672F3 >> 13:
Page number = 0x1A2B3
The MMU then:
-
- Checks the TLB for
VPN = 0x1A2B3. On a hit, retrieves the frame number directly. - On a miss, indexes into the page table at entry
0x1A2B3, reads the frame number from the PTE. - Concatenates
[frame number | 0x12F3]to produce the physical address. - Accesses physical memory at that address.
Part (d): EAT with TLB
All times must be in the same unit. Convert: 100 μs = 100,000 ns.
| Path | Probability | Time |
|---|---|---|
| TLB hit | 0.90 | TLB access + 1 memory access = ns |
| TLB miss | 0.10 | TLB access + page table access + data access = ns |
Problem 26 [EAT]: TLB Hit Ratio and EAT
Section titled “Problem 26 [EAT]: TLB Hit Ratio and EAT”The percentage of time that any page number is found in the TLB is called the hit ratio. Assume a TLB hit ratio of 90% and a single-level page table. If it takes 10 nanoseconds to lookup the TLB, and 100 nanoseconds to access memory, calculate the effective memory-access time.
Instructor Solution
The effective memory access time (EAT) is calculated based on whether the page mapping is found in the TLB (hit) or requires a lookup in the page table in main memory (miss)
-
TLB Hit (90%): TLB lookup + Main memory access = 10 ns + 100 ns = 110 ns
-
TLB Miss (10%): TLB lookup + Page table access in memory + Main memory access = 10ns + 100 ns + 100 ns = 210 ns
-
Calculate the weighted average: EAT = (0.90 x 110 ns) + (0.10 x 210 ns) = 99 ns + 21 ns = 120 ns
Elaboration (by LLM)
The Effective Memory Access Time (EAT) formula accounts for the fact that the system sometimes finds a translation quickly (TLB hit) and sometimes must go the slow route (TLB miss). It’s a weighted average over those two scenarios.
Why Two Scenarios?
Every memory access begins with address translation: the CPU has a virtual (logical) address and needs to find the corresponding physical frame number. There are two paths:
Virtual Address │ ▼ ┌────────┐ Hit (90%) ┌──────────────┐ │ TLB │ ─────────────►│ Physical RAM │ Cost: TLB + 1 RAM └────────┘ └──────────────┘ │ Miss (10%) ▼ ┌───────────┐ ┌──────────────┐ │ Page Table│ ──────────► │ Physical RAM │ Cost: TLB + 2 RAM │ (in RAM) │ └──────────────┘ └───────────┘- TLB Hit: The frame number is cached in the TLB. One TLB lookup, then one RAM access for the actual data.
- TLB Miss: The TLB doesn’t have the entry. One TLB lookup (which fails), then one RAM access to walk the page table and find the frame, then one more RAM access for the actual data.
Step-by-Step Calculation
Given values: TLB lookup = 10 ns, memory access = 100 ns, hit ratio = 0.90.
TLB Hit cost (happens 90% of the time):
TLB Miss cost (happens 10% of the time):
Weighted average (EAT):
Problem 27 [EAT]: 16-bit Single-Level Paging
Section titled “Problem 27 [EAT]: 16-bit Single-Level Paging”Consider a 16-bit architecture that uses single-level paging. Assume the frame size is 256 bytes, and the total physical memory size is 16KB.
(a) What’s the total virtual memory size? How many frames does the physical memory have?
(b) Draw the virtual address and show how many bits are used for offset and how many bits are used for page number.
(c) How many entries does a process’s page table have? What’s the size of a process’s page table?
(d) Show a diagram that shows how address translation occurs. Draw TLB, page table and physical memory. Assume all pages of a process are in the memory for the process to run.
(e) Assume TLB search takes 1ns and memory access takes 100ns. For a TLB hit rate of 90%, compute the effective memory access time.
Instructor Solution
(a)
Total Virtual Memory: A 16-bit architecture supports addresses, which is 64KB.
Physical Frames: 16KB/256bytes = / = = 64 frames.
(b)
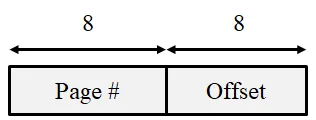
(c)
Entries: The number of entries equals the number of virtual pages (/ = ), which is 256 entries.
Size: Assuming a 2-byte (16-bit) entry to hold the frame number and control bits, the table size is 256 x 2 bytes = 512 bytes.
(d)
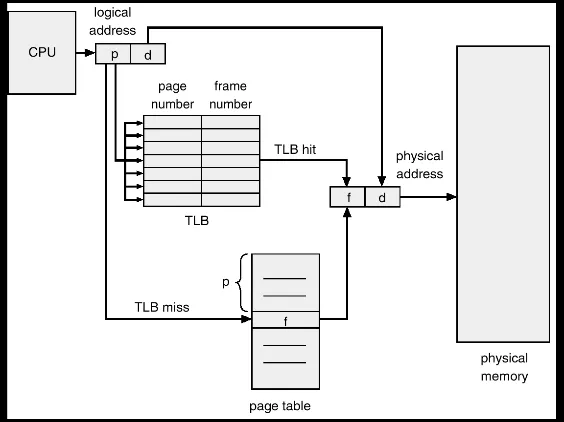
(e)
TLB Hit (90%): TLB_search + RAM_access = 1ns + 100ns = 101ns
TLB Miss (10%): TLB_search + PageTable_access + RAM_access = 1ns + 100ns + 100ns = 201ns
EAT: 0.90 x 101ns + 0.10 x 201ns = 90.9ns + 20.1ns =111ns
Elaboration (by LLM)
This problem builds intuition for how the bit widths of a virtual address are derived from hardware constraints. Let’s work through each part conceptually.
Part (a): Virtual Memory Size and Physical Frames
The virtual address space is determined entirely by the number of bits in the address. With a 16-bit architecture, the CPU can generate distinct addresses — that’s 64KB of virtual address space, regardless of how much physical RAM exists.
For physical frames, we divide:
Part (b): Virtual Address Layout
The virtual address is split into two fields. Since the page/frame size is 256 bytes = bytes, the offset field needs 8 bits (to address any byte within a 256-byte page). The remaining bits form the page number field:
So the 16-bit address looks like this:
Bit 15 ──────── Bit 8 │ Bit 7 ──────── Bit 0┌───────────────────────┼───────────────────────┐│ Page Number (8 bits)│ Offset (8 bits) │└───────────────────────┴───────────────────────┘Part (c): Page Table Size
The page table has one entry per virtual page. Since the page number is 8 bits, there are virtual pages, so the page table has 256 entries.
Each entry must store at minimum a frame number (6 bits to address 64 frames) plus some control bits (valid, dirty, referenced, etc.). Rounded up to a convenient size of 2 bytes (16 bits), the total page table size is:
Part (d): Address Translation Flow
The address translation process works as follows:
CPU generates virtual address │ ▼ ┌─────────────┐ Page # ┌─────────┐ Hit: frame # │ Virtual │ ────────────►│ TLB │ ──────────────┐ │ Address │ └─────────┘ │ │ [Page│Off] │ │ Miss │ └─────────────┘ ▼ │ ┌─────────────┐ │ │ Page Table │ │ │ (in RAM) │ │ └─────────────┘ │ │ frame # │ ▼ ▼ ┌──────────────────────────────┐ │ Physical Address │ │ [Frame # │ Offset] │ └──────────────────────────────┘ │ ▼ Physical MemoryThe offset passes through unchanged — the byte’s position within a page is the same whether you refer to it by virtual or physical address. Only the page number is translated to a frame number.
Part (e): EAT Calculation
With TLB search = 1 ns and memory access = 100 ns:
TLB Hit (90%):
TLB lookup (succeeds) + data access.
TLB Miss (10%):
TLB lookup (fails) + page table in RAM + data access.
Problem 28 [EAT]: 32-bit Single-Level Paging
Section titled “Problem 28 [EAT]: 32-bit Single-Level Paging”Consider a 32-bit computer that has 1GB of physical memory. This machine employs single-level paging with 8KB frames.
(a) Show the parts of a virtual address, i.e., how many bits are used for offset, how many bits for indexing the page table?
(b) How many physical frames does the machine have? How many bytes does a process page table occupy in memory?
(c) A user process generates the virtual address 0x345612F3. What’s the page number, what is the offset?
(d) Explain how the system establishes the corresponding physical location. Distinguish between software and hardware operations.
(e) Assume that memory access takes 100 microseconds. This machine uses TLB and TLB access takes 100 nano seconds. Assume a 90% TLB hit ration, compute the effective memory access time.
Instructor Solution
(a)
Offset: The page size is bytes, so 13 bits are used for the offset.
Page Table Index: With a 32-bit virtual address, the remaining 19 bits (32 - 13) are used for the page table index.
(b)
Physical Frames: 1GB / 8KB = / = frames.
Page Table Size: There are virtual pages. Assuming each Page Table Entry (PTE) is 4 bytes, the table size is x 4 bytes = bytes = 2MB.
(c)
Virtual Address (Hex): 0x345612F3
Binary Representation: 0011 0100 0101 0110 0001 0010 1111 0011Offset (Lower 13 bits): 1 0010 1111 0011 🡪 0x12F3
Page Number (Upper 19 bits): 0011 0100 0101 0110 000 🡪 0x1A2B0
(d)
Hardware (MMU/TLB): The CPU extracts the page number from the virtual address and checks the TLB. If found (TLB hit), the hardware immediately concatenates the frame number with the offset to form the physical address. If a miss occurs, the MMU automatically walks the page table in memory to find the mapping.
Software (OS): The Operating System is generally not involved in every translation. It only intervenes during a page fault (if the page isn’t in RAM), where it must load the page from disk and update the page table, or during a context switch to update the page table base register.
(e)
TLB Hit (90%): TLB + RAM = 100ns + 100,000ns = 100,100ns
TLB Miss (10%): TLB + RAM (table) + RAM (data) = 100ns + 100,000ns + 100,000ns = 200,100ns
EAT: (0.90 x 100,100) + (0.10 x 200,100) = 90,090 + 20,010 = 110,100ns (or 110.1us).
Elaboration (by LLM)
Part (a): Virtual Address Bit Layout
8KB = bytes, so 13 bits are needed for the byte offset within a page. The remaining bits form the page table index:
Bit 31 ─────────── Bit 13 │ Bit 12 ──────── Bit 0┌────────────────────────────┼──────────────────────┐│ Page Table Index (19 bits)│ Offset (13 bits) │└────────────────────────────┴──────────────────────┘Part (b): Physical Frames and Page Table Size
The page table must have one entry per virtual page (not physical frame):
Part (c): Decomposing 0x345612F3
First convert the hex address to binary, then split at the 13-bit boundary:
Hex: 3 4 5 6 1 2 F 3Bin: 0011 0100 0101 0110 0001 0010 1111 0011 └────────────────────────────────────────┘ 32 bits total
Split at bit 13 (from the right): Upper 19 bits → Page number: 001 1010 0010 1011 0000 = 0x1A2B0 Lower 13 bits → Offset: 1 0010 1111 0011 = 0x12F3Notice that the offset value 0x12F3 = 4851, which is less than 8192 (8KB), confirming it’s a valid within-page offset.
Part (d): Hardware vs. Software Roles
Hardware (MMU) — happens on every memory access, in nanoseconds:
- Extracts page number from virtual address
- Looks up TLB
- On TLB hit: forms physical address immediately
- On TLB miss: walks the page table in RAM
- Concatenates frame number + offset → physical address
Software (OS kernel) — only intervenes on exceptions, takes milliseconds:
- Handles page faults (page not in RAM → load from disk)
- Updates page table after loading a page
- Updates page table base register (CR3 on x86) during context switch
- Runs page replacement algorithm when RAM is full
The separation is intentional: hardware speed handles the common case (TLB hit), while the OS handles the rare but complex cases (faults, context switches).
Part (e): EAT with Mixed Units
This part requires careful unit handling. Memory access = 100 µs = 100,000 ns; TLB = 100 ns.
TLB Hit (90%):
TLB Miss (10%):
Problem 29 [Paging]: Page Table Entry Structure
Section titled “Problem 29 [Paging]: Page Table Entry Structure”A certain computer provides its users with a virtual address space of bytes. The computer has bytes of physical memory. The virtual memory is implemented by paging with 2-level page tables, and the page size is 64 bytes.
(a) Show the parts of a virtual address, i.e., how many bits are used for offset, how many bits for indexing the outer page table, and how many bits for indexing the inner page table?
(b) A user process generates the virtual address 0x12F3. What’s the outer page number, the inner page number and the offset?
(c) Explain how the system establishes the corresponding physical location. Distinguish between software and hardware operations.
Instructor Solution
(a)
Offset: Since the page size is bytes, the offset is 6 bits
Total Page Number Bits: 16 total bits - 6 offset bits = 10 bits for the page indices
Inner and Outer Page Tables: With 2-level paging, these 10 bits are typically split. Assuming a balanced approach where each table fits within one page (64 bytes) and each entry is 2 bytes, each table would have 32 () entries. This results in: Outer Page Table Index: 5 bits, Inner Page Table Index: 5 bits
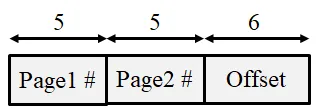
(b)
0x12F3 = 0001 0010 1111 0011
Outer Page Number (First 5 bits): 00010 = 0x02
Inner Page Number (Next 5 bits): 01011 = 0x0B
Offset (Last 6 bits): 110011 = 0x33
(c)
Hardware (MMU/TLB): The CPU extracts the page number from the virtual address and checks the TLB. If found (TLB hit), the hardware immediately concatenates the frame number with the offset to form the physical address. If a miss occurs, the MMU automatically walks the page table in memory to find the mapping.
Software (OS): The Operating System is generally not involved in every translation. It only intervenes during a page fault (if the page isn’t in RAM), where it must load the page from disk and update the page table, or during a context switch to update the page table base register.
Elaboration (by LLM)
Why 2-Level Page Tables?
A single-level page table for this machine would need entries (one per virtual page). That’s manageable here, but in general, 2-level page tables allow the structure to be sparse — inner page tables only exist for regions of the virtual address space that are actually used, saving memory.
Part (a): Deriving the Bit Split
Step 1 — Offset bits: Page size = 64 bytes = , so 6 offset bits.
Step 2 — Remaining bits for page indices: bits total for the two-level page index.
Step 3 — Split the 10 bits between two levels: The constraint is that each page table must fit within one page (64 bytes). With 2-byte entries, each table can hold entries, requiring 5 bits to index. So the split is 5 + 5.
Bit 15 ──── Bit 11 │ Bit 10 ─── Bit 6 │ Bit 5 ─── Bit 0┌────────────────────┼─────────────────┼────────────────────┐│ Outer Index (5b) │ Inner Index (5b)│ Offset (6 bits) ││ (Page1 #) │ (Page2 #) │ │└────────────────────┴─────────────────┴────────────────────┘Part (b): Decomposing 0x12F3
0x12F3 = 0001 0010 1111 0011 (16 bits)
Bits labeled right-to-left (bit 0 = rightmost): Bit 15..11 (5 bits) = 0 0010 = 0x02 ← Outer page index Bit 10..6 (5 bits) = 0 1011 = 0x0B ← Inner page index Bit 5..0 (6 bits) = 11 0011 = 0x33 ← OffsetPart (c): 2-Level Translation Walk
On a TLB miss, the MMU performs a page table walk through two levels:
CPU register: Page Directory Base Register (PDBR) │ ▼┌─────────────────────┐│ Outer Page Table │ ← indexed by outer index (0x02)│ (Page Directory) │ → gives base address of inner table└─────────────────────┘ │ ▼┌─────────────────────┐│ Inner Page Table │ ← indexed by inner index (0x0B)│ (Page Table) │ → gives physical frame number└─────────────────────┘ │ ▼ Frame number + Offset → Physical AddressEach level requires one RAM access on a TLB miss, so a full miss costs 3 memory accesses in total (outer table + inner table + data).
Problem 30 [Paging]: Page Replacement Algorithms
Section titled “Problem 30 [Paging]: Page Replacement Algorithms”Consider a logical (virtual) address space of eight pages of 1024 words each, mapped onto a physical memory of 32 frames.
(a) How many bits are there in the logical address space?
(b) How many bits are there in the physical address space?
Instructor Solution
(a)
The logical address is the sum of the bits needed to identify a page and the bits needed to identify the offset within that page. Page Index: 8 pages = , so 3 bits. Offset: 1024 words = , so 10 bits. Total: 3 + 10 =13 bits.
(b)
Frame Index: 32 frames = , so 5 bits. Offset: words, so 10 bits. Total: 5 + 10 = 15 bits.
Elaboration (by LLM)
This problem illustrates a key asymmetry in paging: the virtual address and physical address can have different bit widths, because the number of virtual pages and the number of physical frames are independent quantities.
Part (a): Logical (Virtual) Address Bits
The logical address must identify:
- Which virtual page: 8 pages = , so 3 bits
- Which word within that page: 1024 words = , so 10 bits
Logical Address (13 bits):┌──────────────┬────────────────────────────┐│ Page (3b) │ Offset (10b) │└──────────────┴────────────────────────────┘Part (b): Physical Address Bits
The physical address must identify:
- Which physical frame: 32 frames = , so 5 bits
- Which word within that frame: same page/frame size = , so 10 bits
Physical Address (15 bits):┌──────────────┬────────────────────────────┐│ Frame (5b) │ Offset (10b) │└──────────────┴────────────────────────────┘Problem 31: FIFO Page Replacement
Section titled “Problem 31: FIFO Page Replacement”Consider a system with an average memory access time of 100 nano-seconds, a three level page table (meta-directory, directory, and page table). For full credit, your answer must be a single number and not a formula.
(a) If the system had an average page fault rate of for any page accessed (data or page table related), and an average page fault took 1msec to service, what is the effective memory access time (assume no TLB or memory cache)?
(b) Now assume the system has no page faults, we are considering adding a TLB that will take 1 nano-second to lookup an address translation. What hit rate in the TLB is required to reduce the effective access time to 160ns?
(c) Somebody suggests increasing the page size to improve the system’s performance. List 2 advantages and 2 disadvantages of making such a decision.
Instructor Solution
(a)
EAT = 4 x 100ns + // You have to access the page no matter what
x 1ms // Time to handle a page fault
EAT = 4 x 100ns + 1 x 100ns = 500ns
(b)
EAT = 1ns + p x 100ns + // TLB hit
(1-p) x 400ns // TLB miss
We want EAT to be 160ns. So 160ns = 401ns - 300ns x p
p = 241/300 = 0.8033. So 80.33% hit rate is necessary
(c)
Advantages: (1) Smaller page tables, (2) Less page faults may result due to locality of reference. Disadvantages: (1) More internal fragmentation, (2) More data to move between memory and disk during page fault handling.
Elaboration (by LLM)
Part (a): EAT with 3-Level Page Tables and Page Faults
With a 3-level page table and no TLB, translating a single virtual address requires walking all three table levels before reaching the data — that’s 4 memory accesses total in the fault-free case:
Access 1: Meta-directory (level 1 page table)Access 2: Directory (level 2 page table)Access 3: Page table (level 3 page table)Access 4: The actual dataOn top of the 4 base accesses, the problem gives a page fault rate of per memory reference, with each fault costing 1 ms to service:
Note that :
Part (b): Solving for Required TLB Hit Rate
With a TLB (1 ns lookup), there are two cases per memory access:
- TLB hit (probability ): 1 ns (TLB) + 100 ns (data) = 101 ns
- TLB miss (probability ): 1 ns (TLB) + 3×100 ns (3-level walk) + 100 ns (data) = 401 ns
Set EAT = 160 ns and solve:
So roughly an 80.3% hit rate is needed to achieve 160 ns EAT.
Part (c): Trade-offs of Larger Page Size
Advantages of larger pages:
- Smaller page tables — fewer entries needed (fewer pages in the address space)
- Fewer page faults — spatial locality means larger pages capture more of the working set per fault; fewer total faults
Disadvantages of larger pages:
- More internal fragmentation — the last page of a process is more likely to be mostly unused
- More I/O per fault — loading a larger page from disk takes more time and bandwidth when a fault does occur
Problem 32 [Paging]: Optimal Page Replacement
Section titled “Problem 32 [Paging]: Optimal Page Replacement”Consider a memory management system that uses paging. The page size is 512 bytes. Assume that the memory contains 16 pages labeled 0 through 15 and the OS is resident on the first 4 pages of the memory. Assume that there is a single process in the system using up 3 pages of memory. Specifically, the process is resident on physical blocks 5, 7, and 11.
(a) Show the current snapshot of the memory and the page table of the current process.
(b) Assume now that a new process arrives and requires 2000 bytes of memory. Allocate space for this process, show its page table, and depict the current snapshot of the memory.
(c) What’s internal fragmentation as it applies to memory management. How many bytes are wasted for the newly arriving process in (b) due to internal fragmentation?
Instructor Solution
(a)
(b)
The new process requires 4 pages: 4x512 = 2048 bytes. Let’s say that the OS allocates frames 4, 6, 8 and 9 for the new process. Then the new snapshot becomes:
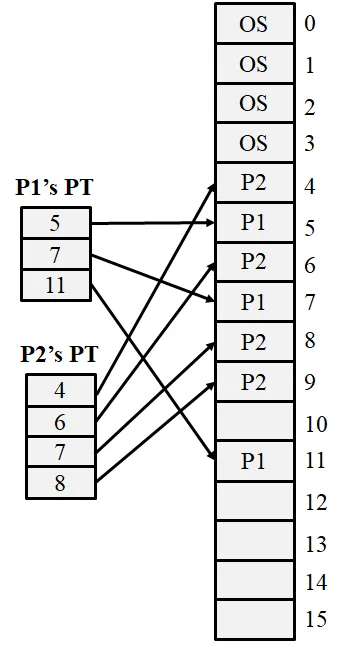
(c)
Internal Fragmentation occurs when the memory allocated to a process is slightly larger than the memory requested. This happens because the system allocates memory in fixed-size chunks (pages/frames), and the process’s last chunk is often not completely filled. Wasted Bytes for the new process: Total space allocated: 4 pages x 512 bytes = 2048 bytes. Space requested: 2000 bytes. Wasted (Internal Fragmentation): 2048 - 2000 = 48 bytes
Elaboration (by LLM)
Part (a): Reading a Page Table
The page table maps virtual page numbers (the process’s view) to physical frame numbers (actual RAM locations). P1 has 3 pages, so its page table has 3 entries:
P1's Page Table:┌────────────┬──────────────┐│ Virt Page │ Phys Frame │├────────────┼──────────────┤│ 0 │ 5 ││ 1 │ 7 ││ 2 │ 11 │└────────────┴──────────────┘
Physical Memory (16 frames):Frame: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [OS][OS][OS][OS][ ][P1][ ][P1][ ][ ][ ][P1][ ][ ][ ][ ]Frames 4, 6, 8, 9, 10, 12–15 are free. The OS occupies frames 0–3 (pinned; never paged out).
Part (b): Allocating for a New Process
P2 requests 2000 bytes. Since pages are 512 bytes each:
Four frames must be allocated from the free list. The OS picks any available frames (e.g., 4, 6, 8, 9):
P2's Page Table:┌────────────┬──────────────┐│ Virt Page │ Phys Frame │├────────────┼──────────────┤│ 0 │ 4 ││ 1 │ 6 ││ 2 │ 8 ││ 3 │ 9 │└────────────┴──────────────┘
Physical Memory after P2 arrives:Frame: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [OS][OS][OS][OS][P2][P1][P2][P1][P2][P2][ ][P1][ ][ ][ ][ ]Note: the frames for P1 and P2 are interleaved — this is perfectly fine in paging because each process has its own page table to maintain the correct mapping. From each process’s perspective, its pages appear contiguous in virtual memory even though they’re scattered in physical memory.
Part (c): Internal Fragmentation
Internal fragmentation is wasted space inside allocated memory — the allocated unit is larger than what was requested:
P2 requested: 2000 bytes ──────────────────────────────────┐P2 allocated: 2048 bytes ─────────────────────────────┐ │ ▼ ▼Page 0 [512 bytes - FULL] ████████████████████████████████Page 1 [512 bytes - FULL] ████████████████████████████████Page 2 [512 bytes - FULL] ████████████████████████████████Page 3 [512 bytes - PARTIAL] ██████████████████████░░░░░░░░ └── 464 bytes used └── 48 bytes wastedProblem 33: LRU Page Replacement
Section titled “Problem 33: LRU Page Replacement”Consider an OS running on the following machine: (1) a two level page table (the pointer to the page directory is stored in a register) (2) a memory reference takes 100 nanoseconds
(a) If there is no TLB in the system, and 0.001% of attempts to access physical memory cause a page fault that takes 10msec to service, what is the effective memory access time?
(b) If we add a TLB and 75% of all page-table references are found there, and 0.001% of the remaining memory references to access physical memory cause a page fault that takes 10msec to service, what is the effective access time of user space memory?
Instructor Solution
(a)
Assume that page directories and tables are pinned down (always) in memory. We need to access the page dir, the page table, and then the data reference. The reference to data could cause a page fault. EAT = 300ns + x 10ms = 400 ns.
(b)
Adding a TLB implies that 75% of the time we can skip the memory address translation using page tables. Also if the item is in the TLB, we know it is in memory (not paged out). EAT = .75 x 100ns + .25 x 400 ns = 175ns.
Elaboration (by LLM)
Part (a): 2-Level Page Tables, No TLB, With Page Faults
Key assumption: The page directory and page table are pinned in physical memory (they cannot be paged out). This means only the final data access can cause a page fault.
With 2-level paging, every memory reference requires:
-
- Page directory access (pinned — no fault possible)
- Page table access (pinned — no fault possible)
- Data access (can cause a page fault)
Base cost (no fault):
Page fault probability = 0.001% = , fault service time = 10 ms = ns:
Part (b): Adding a TLB
With a 75% TLB hit rate, the system splits into two cases. The TLB implicitly confirms the page is in memory (if it’s in the TLB, it was recently accessed and therefore in RAM):
TLB Hit (75%):
No page table walk needed. Page is known to be in memory.
TLB Miss (25%):
Must walk the 2-level page table, then access data (which can fault).
Problem 34 [Page replacement]: Not Frequently Used (NFU)
Section titled “Problem 34 [Page replacement]: Not Frequently Used (NFU)”Consider an operating system that uses paging in order to provide virtual memory capability; the paging system employs both a TLB and a single-level page table. Assume that page tables are pinned in physical memory. Draw a flow chart that describes the logic of handling a memory reference. Your chart must include the possibility of TLB hits and misses, as well as page faults. Be sure to mark which activities are accomplished by hardware, and which are accomplished by the OS’s page fault exception handler.
Instructor Solution
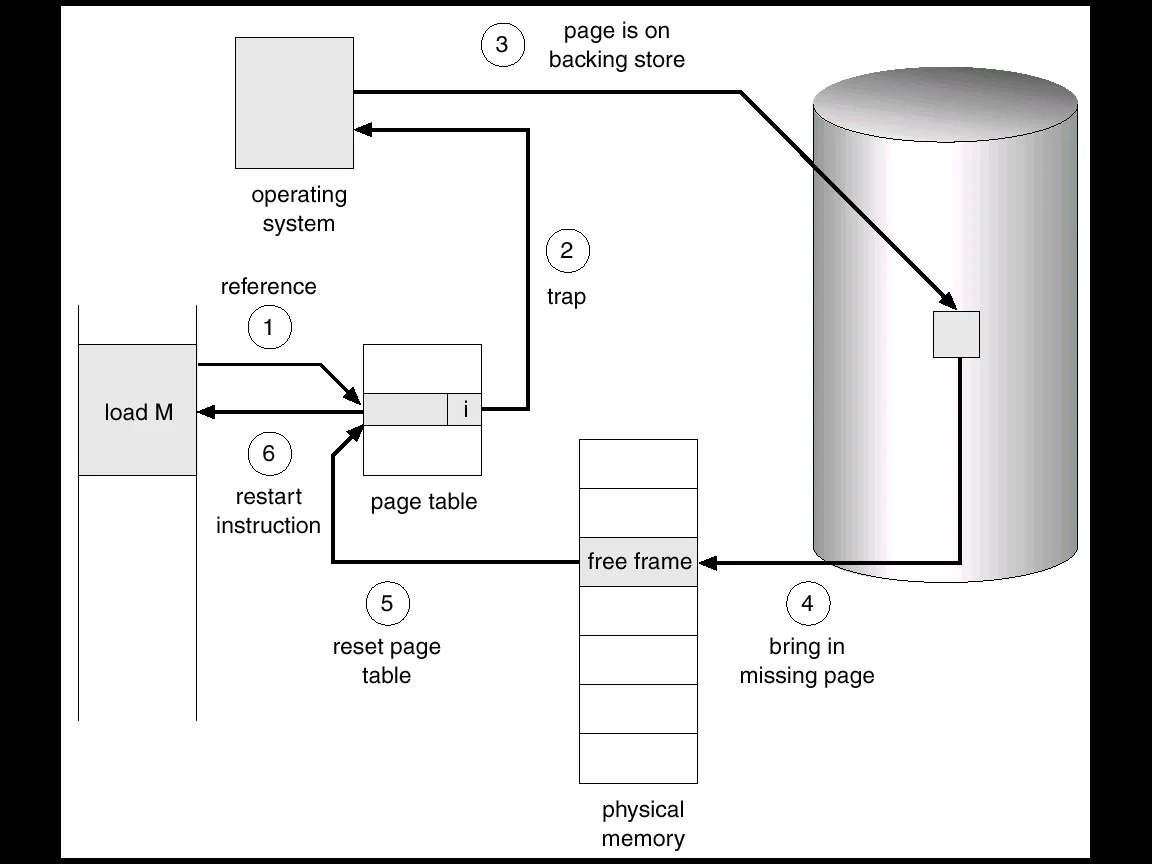
Elaboration (by LLM)
This problem asks you to trace the complete lifecycle of a memory reference, from CPU to RAM, including the exception-handling path. Here’s a detailed flowchart of that logic:
CPU issues virtual address │ ┌─────────▼─────────┐ │ Check TLB │ ← HARDWARE (MMU) └─────────┬─────────┘ HIT / │ \ MISS │ └──────────────────────┐ ┌─────────▼─────────┐ ┌─────────▼──────────┐ │ Get frame # from │ │ Look up page table │ ← HARDWARE │ TLB cache │ │ (page table pinned) │ └─────────┬─────────┘ └─────────┬──────────┘ │ VALID / │ \ INVALID │ │ └──────────────────┐ │ ┌─────────────▼──────────┐ ┌────────▼────────┐ │ │ Update TLB with entry │ │ PAGE FAULT │ │ │ (frame #, page #) │ │ TRAP to OS │ ← HARDWARE │ └─────────────┬──────────┘ └────────┬────────┘ │ │ │ │ │ ┌─────────▼──────────────┐ └─────────────────────────────┘ │ OS: is access legal? │ ← SOFTWARE │ └─────────┬──────────────┘ │ ILLEGAL / │ \ LEGAL │ │ └──────────────────────┐ │ ┌─────────────▼──────┐ ┌───────────────▼──────┐ │ │ Terminate process │ │ Is there a free frame?│ ← SOFTWARE │ │ (SIGSEGV) │ └───────────┬──────────┘ │ └─────────────────────┘ YES / │ \ NO │ │ └──────────────────┐ │ ┌────────────▼──┐ ┌────────────────▼──┐ │ │ Use free frame│ │ Run page replacement│ ← SOFTWARE │ └────────────┬──┘ │ evict victim page │ │ │ └────────────────┬──┘ │ └──────────┬───────────┘ │ ┌───────────▼──────────────┐ │ │ Disk I/O: load page │ ← SOFTWARE │ │ into allocated frame │ │ └───────────┬──────────────┘ │ ┌───────────▼──────────────┐ │ │ Update page table entry: │ ← SOFTWARE │ │ set frame #, valid bit=1 │ │ └───────────┬──────────────┘ │ ┌───────────▼──────────────┐ │ │ Restart faulting │ ← SOFTWARE │ │ instruction │ │ └───────────┬──────────────┘ │ │ │ (now TLB miss path runs again, │ this time page table valid) │ ┌─────────▼──────────┐ │ Form physical addr: │ ← HARDWARE │ frame # + offset │ └─────────┬──────────┘ │ ┌─────────▼──────────┐ │ Access RAM │ ← HARDWARE └────────────────────┘Summary: Hardware vs. Software Responsibilities
Hardware (MMU) handles:
- TLB lookup (hit or miss)
- Page table walk on TLB miss
- Detecting invalid page table entry → raising page fault trap
- Forming physical address (frame # + offset)
- Performing the actual RAM access
Software (OS kernel) handles:
- Receiving the page fault trap
- Validating the memory access (legal vs. illegal)
- Choosing a free frame (or running replacement algorithm)
- Scheduling and completing disk I/O to load the page
- Updating the page table entry (frame number + valid bit)
- Restarting the faulting instruction
Problem 35 [Page replacement]: Page Fault Statistics
Section titled “Problem 35 [Page replacement]: Page Fault Statistics”Briefly explain how a page fault occurs and the steps that the memory management system takes to handle a page fault.
Instructor Solution
A page fault occurs when a running process attempts to access a virtual memory address that is not currently mapped to a physical frame in RAM. This is detected by the Memory Management Unit (MMU) when it finds the “valid-invalid” bit in the page table set to “invalid.” Here are the steps to handle a page fault:
-
Trap to the OS: The MMU generates a trap, pausing the process and switching control to the operating system kernel.
-
Internal Table Check: The OS looks at an internal table (often in the Process Control Block) to verify if the memory access was a legitimate request to a valid virtual address or an illegal access.
-
If illegal, the process is terminated (Segmentation Fault).
-
If legal, the OS proceeds to fetch the page.
-
Find a Free Frame: The OS searches the Free Frame List in physical memory. If no frames are free, a page replacement algorithm (like LRU) is run to evict a “victim” page.
-
Disk I/O (The “Swap In”): The OS schedules a disk operation to read the desired page from the swap space or executable file into the newly allocated physical frame.
-
Update Page Table: Once the I/O is complete, the OS updates the process’s page table by entering the new frame number and changing the status bit from “invalid” to “valid.”
-
Restart Instruction: The OS restores the process state and restarts the specific CPU instruction that caused the fault. The process can now access the data as if it had been in memory all along.
Private Concise answer (by LLM)
A page fault occurs when the MMU finds the present/valid bit cleared in a PTE; the OS validates the access (terminating the process if illegal), finds or frees a physical frame, loads the missing page from disk, updates the PTE, and restarts the faulting instruction transparently.
Concise answer (by LLM):
A page fault occurs when the MMU finds a page’s valid bit cleared (the page isn’t in RAM); the OS validates the access, finds or frees a frame, loads the page from disk, updates the PTE, and restarts the faulting instruction.
Elaboration (by LLM)
A page fault is the mechanism that makes virtual memory larger than physical RAM practical. The OS uses disk (swap space) as a slow extension of RAM, bringing pages in only when they’re needed. Here’s a deeper look at each step.
Step 0: What Triggers a Page Fault?
Each page table entry has a valid bit (also called present bit). When the OS evicts a page to disk (to free up a frame), it clears this bit. The next time the CPU tries to access that page, the MMU sees the invalid bit and raises a trap — the page fault.
Page Table Entry:┌─────────────┬────────────────────────────────────┐│ Frame Number │ Valid │ Dirty │ Referenced │ ... │├─────────────┼────────────────────────────────────┤│ 0x3A │ 1 │ 0 │ 1 │ ... │ ← Page in RAM, fine│ — │ 0 │ — │ — │ ... │ ← PAGE FAULT on access!└─────────────┴────────────────────────────────────┘The Page Fault Handling Steps
-
-
MMU raises a trap (hardware): The CPU stops the current instruction and transfers control to the OS page fault handler. The faulting virtual address is saved (in a register like CR2 on x86).
-
OS validates the access (software): The OS checks whether the faulting address belongs to a legitimate virtual memory region of the process (checked against the process’s VMA — Virtual Memory Area — list in the PCB). If not →
SIGSEGV(segmentation fault) and process termination. -
Find a free frame (software): The OS checks the free frame list. If frames are available, take one. If not, run a page replacement algorithm (FIFO, LRU, Clock, etc.) to select a victim page to evict. If the victim’s dirty bit is set (it was modified), it must first be written back to disk.
-
Disk I/O — swap in (software + hardware): The OS issues a read from the swap device or file system to bring the needed page into the allocated frame. The process is blocked during this I/O (it may be context-switched out so the CPU can do other work).
-
Update the page table (software): Once I/O completes, the OS writes the new frame number into the page table entry and sets the valid bit to 1. The TLB entry (if any, for this page) is also invalidated/updated.
-
Restart the faulting instruction (software/hardware): The OS restores the process’s register state and restarts the exact instruction that faulted. This time, the MMU finds the valid bit set, translates successfully, and the access proceeds normally.
Why Is a Page Fault So Expensive?
The disk I/O step dominates the cost:
TLB access: ~1 nsRAM access: ~100 nsPage fault: ~5–10 ms (disk seek + rotational latency + transfer)A single page fault can cost the equivalent of ~50,000–100,000 normal memory accesses. This is why working set management matters: if a process’s actively-used pages (its working set) fit in RAM, faults are rare. If the working set exceeds available frames, thrashing occurs — the system spends most of its time handling page faults rather than executing useful instructions.
Problem 36 [Page replacement]: Belady Anomaly
Section titled “Problem 36 [Page replacement]: Belady Anomaly”What’s Belady’s anomaly? Briefly explain.
Instructor Solution
Belady’s Anomaly is a counterintuitive phenomenon in operating systems where increasing the number of physical page frames results in an increase in the number of page faults for a specific memory access sequence. In most page replacement algorithms (like LRU), adding more memory always helps or at least doesn’t hurt. However, for the FIFO (First-In, First-Out) page replacement algorithm, it is possible to get more page faults by increasing the physical memory. This is called Belady’s anomaly.
Private Concise answer (by LLM)
Belady’s Anomaly is the counterintuitive phenomenon where FIFO can produce more page faults with more frames because FIFO’s arrival-order eviction policy is insensitive to future access patterns — algorithms like LRU that satisfy the stack property are immune to it.
Concise answer (by LLM):
Belady’s Anomaly is the counterintuitive result that giving FIFO more physical frames can actually increase page faults, because FIFO’s arrival-order eviction can produce worse frame sets with additional memory.
Elaboration (by LLM)
The intuition for most people is simple: more memory should always mean fewer page faults. Belady’s Anomaly is surprising precisely because it violates this intuition for certain algorithms.
Why Does It Happen?
The key insight is that some page replacement algorithms — especially FIFO — don’t track how useful a page is. FIFO evicts the page that has been in memory the longest, not the page that is least needed. When you add more frames, FIFO can load and keep pages in a different order, which might mean it evicts a page that would have been needed very soon — causing more faults than before.
A Classic Minimal Example
The canonical example uses reference string 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5 under FIFO:
- 3 frames: 9 page faults
- 4 frames: 10 page faults ← more frames, more faults!
Which Algorithms Are Immune?
Algorithms that satisfy the stack property are immune to Belady’s Anomaly. An algorithm has the stack property if the set of pages in memory with frames is always a subset of the set that would be in memory with frames. Intuitively, adding a frame only ever adds a page to the loaded set — it never changes which pages are already there.
| Algorithm | Immune to Belady’s? | Reason |
|---|---|---|
| Optimal | ✅ Yes | Stack property holds |
| LRU | ✅ Yes | Stack property holds |
| FIFO | ❌ No | No stack property |
| Clock (2nd Chance) | ❌ No | Approximate, not stack-based |
Practical Takeaway
Belady’s Anomaly is mostly a theoretical concern. Real systems use LRU approximations (like the Clock algorithm), which are immune or nearly immune. However, it is a strong reminder that page replacement algorithm design matters, and that a naive “first-in, first-out” approach can backfire.
Problem 37 [Page replacement]: Working Set Model
Section titled “Problem 37 [Page replacement]: Working Set Model”Consider the following sequence of virtual memory references generated by a single process in a pure paging system: 10, 11, 104, 170, 73, 309, 185, 245, 246, 434, 458, 364
(a) Assuming a page size of 100 words, what is the reference string corresponding to these memory references?
Instructor Solution
The page number is calculated as Address/(Page Size). With a page size of 100 words:
10, 11 🡪 0
104, 170 🡪 1
73 🡪 0
309 🡪 3
185 🡪 1
245, 246 🡪 2
434, 458 🡪 4
364 🡪 3
Reference String: 0, 0, 1, 1, 0, 3, 1, 2, 2, 4, 4, 3
Simplified for unique transitions: 0, 1, 0, 3, 1, 2, 4, 3
Elaboration (by LLM)
What Is a Reference String?
A reference string is a simplified sequence of page numbers accessed by a process. Instead of working with raw memory addresses (which can be huge), we convert each address to the page it belongs to. This lets us simulate page replacement algorithms step by step.
Converting Addresses to Page Numbers
The formula is straightforward:
With a page size of 100 words, each “page” covers a 100-word range:
- Page 0: addresses 0–99
- Page 1: addresses 100–199
- Page 2: addresses 200–299
- Page 3: addresses 300–399
- Page 4: addresses 400–499
Applying this to each address:
| Address | Calculation | Page |
|---|---|---|
| 10 | 0 | |
| 11 | 0 | |
| 104 | 1 | |
| 170 | 1 | |
| 73 | 0 | |
| 309 | 3 | |
| 185 | 1 | |
| 245 | 2 | |
| 246 | 2 | |
| 434 | 4 | |
| 458 | 4 | |
| 364 | 3 |
This gives the full reference string: 0, 0, 1, 1, 0, 3, 1, 2, 2, 4, 4, 3
Why Simplify to Unique Transitions?
When simulating page replacement, consecutive references to the same page don’t change any algorithm’s behavior — the page is already in memory, so it’s a hit regardless. We compress repeated consecutive entries into a single access:
This simplified string is what we use to count page faults in part (b).
(b) Determine the number of page faults under each of the following page replacement strategies, assuming that two page frames are available to the process: Optimal, FIFO, LRU
Instructor Solution



Elaboration (by LLM)
We simulate each algorithm over the reference string 0, 1, 0, 3, 1, 2, 4, 3 with 2 frames. For each algorithm, the frame grid shows the contents of both frames after every reference (F marks a fault), and the step-by-step table below it explains why each reference was a hit or a fault.
In the step-by-step tables, marks a page fault and marks a hit.
Optimal (5 page faults)
Optimal always evicts the page whose next use is furthest in the future. It requires future knowledge, so it’s theoretical — but it gives a lower bound on page faults.
| Reference | 0 | 1 | 0 | 3 | 1 | 2 | 4 | 3 |
|---|---|---|---|---|---|---|---|---|
| Frame 1 | 0 | 0 | 0 | 3 | 3 | 3 | 3 | 3 |
| Frame 2 | — | 1 | 1 | 1 | 1 | 2 | 4 | 4 |
| Fault? | F | F | F | F | F |
| Reference | Result | Action |
|---|---|---|
| 0 | fault | Free frame — load 0 |
| 1 | fault | Free frame — load 1 |
| 0 | hit | Already resident |
| 3 | fault | Full {0, 1}; page 0 is never used again — evict 0, load 3 |
| 1 | hit | Already resident |
| 2 | fault | Full {3, 1}; page 1 is never used again — evict 1, load 2 |
| 4 | fault | Full {3, 2}; page 2 is never used again — evict 2, load 4 |
| 3 | hit | Already resident |
Total: 5 page faults
FIFO (6 page faults)
FIFO evicts the page that has been in memory the longest — the one that “arrived” earliest, regardless of how recently it was used.
| Reference | 0 | 1 | 0 | 3 | 1 | 2 | 4 | 3 |
|---|---|---|---|---|---|---|---|---|
| Frame 1 | 0 | 0 | 0 | 3 | 3 | 3 | 4 | 4 |
| Frame 2 | — | 1 | 1 | 1 | 1 | 2 | 2 | 3 |
| Fault? | F | F | F | F | F | F |
| Reference | Result | Action |
|---|---|---|
| 0 | fault | Free frame — load 0 |
| 1 | fault | Free frame — load 1 |
| 0 | hit | Already resident |
| 3 | fault | Full; queue [0, 1] — evict 0 (oldest), load 3 |
| 1 | hit | Already resident |
| 2 | fault | Full; queue [1, 3] — evict 1 (oldest), load 2 |
| 4 | fault | Full; queue [3, 2] — evict 3 (oldest), load 4 |
| 3 | fault | Full; queue [2, 4] — evict 2 (oldest), load 3 |
Total: 6 page faults. FIFO has no way to know page 1 is never needed again — it evicts purely by arrival order.
LRU (7 page faults)
LRU evicts the page that was least recently used — the one that hasn’t been accessed for the longest time.
| Reference | 0 | 1 | 0 | 3 | 1 | 2 | 4 | 3 |
|---|---|---|---|---|---|---|---|---|
| Frame 1 | 0 | 0 | 0 | 0 | 1 | 1 | 4 | 4 |
| Frame 2 | — | 1 | 1 | 3 | 3 | 2 | 2 | 3 |
| Fault? | F | F | F | F | F | F | F |
| Reference | Result | Action |
|---|---|---|
| 0 | fault | Free frame — load 0 |
| 1 | fault | Free frame — load 1 |
| 0 | hit | Already resident |
| 3 | fault | Full {0, 1}; 1 is least recently used — evict 1, load 3 |
| 1 | fault | Full {0, 3}; 0 is least recently used — evict 0, load 1 |
| 2 | fault | Full {3, 1}; 3 is least recently used — evict 3, load 2 |
| 4 | fault | Full {1, 2}; 1 is least recently used — evict 1, load 4 |
| 3 | fault | Full {2, 4}; 2 is least recently used — evict 2, load 3 |
Total: 7 page faults
LRU eviction walkthrough
Once both frames are full, every fault must evict the least recently used page. To find it, scan backwards through the reference string up to that point and collect distinct pages in the order you meet them — once you have collected as many distinct pages as there are frames (here, 2), the last one collected is the LRU page.
First eviction — ref 4 (page 3)
Frames are full with {0, 1}. Scanning backwards through the references so far:
Reading right-to-left: 0 (most recent), then 1 (LRU — the 2nd distinct). Evict 1, load 3.
Second eviction — ref 5 (page 1)
Frames are full with {0, 3}. Scanning backwards:
Reading right-to-left: 3 (most recent), then 0 (LRU). Evict 0, load 1.
Third eviction — ref 6 (page 2)
Frames are full with {3, 1}. Scanning backwards:
Reading right-to-left: 1 (most recent), then 3 (LRU). Evict 3, load 2.
Fourth eviction — ref 7 (page 4)
Frames are full with {1, 2}. Scanning backwards:
Reading right-to-left: 2 (most recent), then 1 (LRU). Evict 1, load 4.
Fifth eviction — ref 8 (page 3)
Frames are full with {2, 4}. Scanning backwards:
Reading right-to-left: 4 (most recent), then 2 (LRU). Evict 2, load 3.
Summary
| Algorithm | Page Faults |
|---|---|
| Optimal | 5 (best possible) |
| FIFO | 6 |
| LRU | 7 |
Problem 38 [Page replacement]: Optimal, FIFO, and LRU Page Replacement
Section titled “Problem 38 [Page replacement]: Optimal, FIFO, and LRU Page Replacement”Given the reference string 1, 2, 3, 1, 2, 1, 3, 4, 3, 5, 6, 4, 3 and a physical memory of 3 frames, show the state of the memory with Optimal, FIFO, LRU page replacement algorithms. Count the total number of page faults.
Instructor Solution
Optimal:
| 1 | 2 | 3 | 1 | 2 | 1 | 3 | 4 | 3 | 5 | 6 | 4 | 3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 4 | 4 | 4 |
| 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 5 | 6 | 6 | 6 | |
| 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | ||
| X | X | X | X | X | X |
6 page faults
FIFO:
| 1 | 2 | 3 | 1 | 2 | 1 | 3 | 4 | 3 | 5 | 6 | 4 | 3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 4 | 4 | 3 |
| 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | |
| 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 6 | 6 | 6 | ||
| X | X | X | X | X | X | X |
7 page faults
LRU:
| 1 | 2 | 3 | 1 | 2 | 1 | 3 | 4 | 3 | 5 | 6 | 4 | 3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 5 | 5 | 5 | 3 |
| 2 | 2 | 2 | 2 | 2 | 2 | 4 | 4 | 4 | 6 | 6 | 6 | |
| 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 4 | 4 | ||
| X | X | X | X | X | X | X | X |
8 page faults
Elaboration (by LLM)
We simulate each algorithm over the reference string 1, 2, 3, 1, 2, 1, 3, 4, 3, 5, 6, 4, 3 with 3 frames. The frame grids above (in the instructor solution) show memory contents after each reference; the step-by-step tables below explain why each reference was a hit or a fault. In the tables, marks a page fault and marks a hit.
Optimal (6 page faults)
Optimal evicts the page whose next use is furthest in the future (or never used again).
| Reference | Result | Action |
|---|---|---|
| 1 | fault | Free frame — load 1 |
| 2 | fault | Free frame — load 2 |
| 3 | fault | Free frame — load 3 |
| 1 | hit | Already resident |
| 2 | hit | Already resident |
| 1 | hit | Already resident |
| 3 | hit | Already resident |
| 4 | fault | Full {1, 2, 3}; pages 1 and 2 are never used again — evict 1, load 4 |
| 3 | hit | Already resident |
| 5 | fault | Full {4, 2, 3}; page 2 is never used again — evict 2, load 5 |
| 6 | fault | Full {4, 5, 3}; page 5 is never used again — evict 5, load 6 |
| 4 | hit | Already resident |
| 3 | hit | Already resident |
Total: 6 page faults. When page 4 arrives, both 1 and 2 are never referenced again — either is a valid eviction; the instructor solution evicts 1.
FIFO (7 page faults)
FIFO evicts the page that has been in memory the longest — the one that arrived earliest — regardless of how recently it was used.
| Reference | Result | Action |
|---|---|---|
| 1 | fault | Free frame — load 1 |
| 2 | fault | Free frame — load 2 |
| 3 | fault | Free frame — load 3 |
| 1 | hit | Already resident |
| 2 | hit | Already resident |
| 1 | hit | Already resident |
| 3 | hit | Already resident |
| 4 | fault | Full; queue [1, 2, 3] — evict 1 (oldest), load 4 |
| 3 | hit | Already resident |
| 5 | fault | Full; queue [2, 3, 4] — evict 2 (oldest), load 5 |
| 6 | fault | Full; queue [3, 4, 5] — evict 3 (oldest), load 6 |
| 4 | hit | Already resident |
| 3 | fault | Full; queue [4, 5, 6] — evict 4 (oldest), load 3 |
Total: 7 page faults. On the final reference, FIFO evicts page 4 even though it was just used one step earlier — arrival order, not recency, decides.
LRU (8 page faults)
LRU evicts the page that has gone unused for the longest time.
| Reference | Result | Action |
|---|---|---|
| 1 | fault | Free frame — load 1 |
| 2 | fault | Free frame — load 2 |
| 3 | fault | Free frame — load 3 |
| 1 | hit | Already resident |
| 2 | hit | Already resident |
| 1 | hit | Already resident |
| 3 | hit | Already resident |
| 4 | fault | Full {1, 2, 3}; 2 is least recently used — evict 2, load 4 |
| 3 | hit | Already resident |
| 5 | fault | Full {1, 3, 4}; 1 is least recently used — evict 1, load 5 |
| 6 | fault | Full {3, 4, 5}; 4 is least recently used — evict 4, load 6 |
| 4 | fault | Full {3, 5, 6}; 3 is least recently used — evict 3, load 4 |
| 3 | fault | Full {4, 5, 6}; 5 is least recently used — evict 5, load 3 |
Total: 8 page faults
LRU eviction walkthrough
Once all 3 frames are full, every fault evicts the least recently used page. Scan backwards through the reference string up to that point and collect distinct pages in the order you meet them — once you have 3 distinct pages, the last one collected is the LRU.
First eviction — ref 8 (page 4)
Frames are full with {1, 2, 3}. Scanning backwards:
Reading right-to-left: 3 (most recent), 1, then 2 (LRU — the 3rd distinct). Evict 2, load 4.
Second eviction — ref 10 (page 5)
Frames are full with {1, 3, 4}. Scanning backwards:
Reading right-to-left: 3 (most recent), 4, then 1 (LRU). Evict 1, load 5.
Third eviction — ref 11 (page 6)
Frames are full with {3, 4, 5}. Scanning backwards:
Reading right-to-left: 5 (most recent), 3, then 4 (LRU). Evict 4, load 6.
Fourth eviction — ref 12 (page 4)
Frames are full with {3, 5, 6}. Scanning backwards:
Reading right-to-left: 6 (most recent), 5, then 3 (LRU). Evict 3, load 4.
Fifth eviction — ref 13 (page 3)
Frames are full with {4, 5, 6}. Scanning backwards:
Reading right-to-left: 4 (most recent), 6, then 5 (LRU). Evict 5, load 3.
Summary
| Algorithm | Page Faults |
|---|---|
| Optimal | 6 |
| FIFO | 7 |
| LRU | 8 |
Problem 39 [Page replacement]: LRU Implementation
Section titled “Problem 39 [Page replacement]: LRU Implementation”Given the reference string 1, 2, 4, 3, 2, 4, 3, 5, 4, 3, 5, 6, 1, 3, 5 and a physical memory of 3 frames, show the state of the memory after each reference with Optimal, FIFO, LRU page replacement algorithms. Count the total number of page faults.
Instructor Solution
Optimal:
| 1 | 2 | 4 | 3 | 2 | 4 | 3 | 5 | 4 | 3 | 5 | 6 | 1 | 3 | 5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| 2 | 2 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | |
| 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 6 | 1 | 1 | 1 | ||
| X | X | X | X | X | X | X |
7 page faults
FIFO:
| 1 | 2 | 4 | 3 | 2 | 4 | 3 | 5 | 4 | 3 | 5 | 6 | 1 | 3 | 5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 1 | 1 | 1 |
| 2 | 2 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | 5 | 5 | 3 | 3 | |
| 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 6 | 6 | 6 | 5 | ||
| X | X | X | X | X | X | X | X | X |
9 page faults
LRU:
| 1 | 2 | 4 | 3 | 2 | 4 | 3 | 5 | 4 | 3 | 5 | 6 | 1 | 3 | 5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 1 | 1 | 1 |
| 2 | 2 | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | 5 | 5 | 3 | 3 | |
| 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 6 | 6 | 6 | 5 | ||
| X | X | X | X | X | X | X | X | X |
9 page faults
Elaboration (by LLM)
We simulate each algorithm over the reference string 1, 2, 4, 3, 2, 4, 3, 5, 4, 3, 5, 6, 1, 3, 5 with 3 frames. The frame grids above (in the instructor solution) show memory contents after each reference; the step-by-step tables below explain why each reference was a hit or a fault. In the tables, marks a page fault and marks a hit.
Optimal (7 page faults)
Optimal evicts the page whose next use is furthest in the future (or never used again).
| Reference | Result | Action |
|---|---|---|
| 1 | fault | Free frame — load 1 |
| 2 | fault | Free frame — load 2 |
| 4 | fault | Free frame — load 4 |
| 3 | fault | Full {1, 2, 4}; page 1 is used furthest away (position 13) — evict 1, load 3 |
| 2 | hit | Already resident |
| 4 | hit | Already resident |
| 3 | hit | Already resident |
| 5 | fault | Full {2, 3, 4}; page 2 is never used again — evict 2, load 5 |
| 4 | hit | Already resident |
| 3 | hit | Already resident |
| 5 | hit | Already resident |
| 6 | fault | Full {3, 4, 5}; page 4 is never used again — evict 4, load 6 |
| 1 | fault | Full {3, 5, 6}; page 6 is never used again — evict 6, load 1 |
| 3 | hit | Already resident |
| 5 | hit | Already resident |
Total: 7 page faults
FIFO (9 page faults)
FIFO evicts the page that has been in memory the longest — the one that arrived earliest — regardless of how recently it was used.
| Reference | Result | Action |
|---|---|---|
| 1 | fault | Free frame — load 1 |
| 2 | fault | Free frame — load 2 |
| 4 | fault | Free frame — load 4 |
| 3 | fault | Full; queue [1, 2, 4] — evict 1 (oldest), load 3 |
| 2 | hit | Already resident |
| 4 | hit | Already resident |
| 3 | hit | Already resident |
| 5 | fault | Full; queue [2, 4, 3] — evict 2 (oldest), load 5 |
| 4 | hit | Already resident |
| 3 | hit | Already resident |
| 5 | hit | Already resident |
| 6 | fault | Full; queue [4, 3, 5] — evict 4 (oldest), load 6 |
| 1 | fault | Full; queue [3, 5, 6] — evict 3 (oldest), load 1 |
| 3 | fault | Full; queue [5, 6, 1] — evict 5 (oldest), load 3 |
| 5 | fault | Full; queue [6, 1, 3] — evict 6 (oldest), load 5 |
Total: 9 page faults. The three consecutive hits at refs 5–7 and again at 9–11 keep the count down; only the tail (6, 1, 3, 5) faults repeatedly.
LRU (9 page faults)
LRU evicts the page that has gone unused for the longest time.
| Reference | Result | Action |
|---|---|---|
| 1 | fault | Free frame — load 1 |
| 2 | fault | Free frame — load 2 |
| 4 | fault | Free frame — load 4 |
| 3 | fault | Full {1, 2, 4}; 1 is least recently used — evict 1, load 3 |
| 2 | hit | Already resident |
| 4 | hit | Already resident |
| 3 | hit | Already resident |
| 5 | fault | Full {2, 3, 4}; 2 is least recently used — evict 2, load 5 |
| 4 | hit | Already resident |
| 3 | hit | Already resident |
| 5 | hit | Already resident |
| 6 | fault | Full {3, 4, 5}; 4 is least recently used — evict 4, load 6 |
| 1 | fault | Full {3, 5, 6}; 3 is least recently used — evict 3, load 1 |
| 3 | fault | Full {5, 6, 1}; 5 is least recently used — evict 5, load 3 |
| 5 | fault | Full {6, 1, 3}; 6 is least recently used — evict 6, load 5 |
Total: 9 page faults
LRU eviction walkthrough
Once all 3 frames are full, every fault evicts the least recently used page. Scan backwards through the reference string up to that point and collect distinct pages in the order you meet them — once you have 3 distinct pages, the last one collected is the LRU.
First eviction — ref 4 (page 3)
Frames are full with {1, 2, 4}. Scanning backwards:
Reading right-to-left: 4 (most recent), 2, then 1 (LRU — the 3rd distinct). Evict 1, load 3.
Second eviction — ref 8 (page 5)
Frames are full with {2, 3, 4}. Scanning backwards:
Reading right-to-left: 3 (most recent), 4, then 2 (LRU). Evict 2, load 5.
Third eviction — ref 12 (page 6)
Frames are full with {3, 4, 5}. Scanning backwards:
Reading right-to-left: 5 (most recent), 3, then 4 (LRU). Evict 4, load 6.
Fourth eviction — ref 13 (page 1)
Frames are full with {3, 5, 6}. Scanning backwards:
Reading right-to-left: 6 (most recent), 5, then 3 (LRU). Evict 3, load 1.
Fifth eviction — ref 14 (page 3)
Frames are full with {5, 6, 1}. Scanning backwards:
Reading right-to-left: 1 (most recent), 6, then 5 (LRU). Evict 5, load 3.
Sixth eviction — ref 15 (page 5)
Frames are full with {6, 1, 3}. Scanning backwards:
Reading right-to-left: 3 (most recent), 1, then 6 (LRU). Evict 6, load 5.
Summary
| Algorithm | Page Faults | Notes |
|---|---|---|
| Optimal | 7 | Theoretical minimum |
| FIFO | 9 | Ties with LRU on this string |
| LRU | 9 | Good approximation of Optimal |
Here FIFO and LRU happen to tie at 9 faults — on this reference string they evict the same page at every fault — and both stay reasonably close to Optimal’s 7.
Problem 40 [Page replacement]: LRU Approximation
Section titled “Problem 40 [Page replacement]: LRU Approximation”Consider the following page reference string: 1, 2, 3, 4, 2, 1, 5, 6, 2, 1, 2, 3, 7, 6, 3, 2, 6, 5, 3, 2, 2, 1. How many page faults would occur for Optimal, FIFO, LRU page replacement algorithms assuming 4 memory frames. Remember that all frames are initially empty, so your first unique pages will all cost one fault each. Also show the state of the memory after each page reference and indicate the victim page when a page fault occurs.
Problem 41 [Page replacement]: Clock Algorithm
Section titled “Problem 41 [Page replacement]: Clock Algorithm”Consider a reference string 1, 2, 3, 4, 2, 5, 7, 2, 3, 2, 1, 7, 8. How many page faults would occur for Optimal, FIFO, LRU page replacement algorithms assuming 4 memory frames? Remember all frames are initially empty, so your first unique pages will all cost one fault each.
Problem 42 [Page replacement]: Reference Bit Usage
Section titled “Problem 42 [Page replacement]: Reference Bit Usage”Consider the following page reference string: 1, 2, 3, 4, 2, 1, 2, 5, 7, 6, 3, 2, 1, 2, 3, 4. How many page faults would occur for Optimal, FIFO, LRU page replacement algorithms assuming 4 memory frames? Remember all frames are initially empty, so your first unique pages will all cost one fault each.
Problem 43 [Page replacement]: Clock vs LRU
Section titled “Problem 43 [Page replacement]: Clock vs LRU”Consider the following page reference string: 1, 3, 2, 5, 1, 3, 4, 1, 3, 2, 5. How many page faults would occur for Optimal, FIFO, LRU page replacement algorithms assuming 3 memory frames? Remember all frames are initially empty, so your first unique pages will all cost one fault each.
Problem 44 [Page replacement]: Recently Used Pages
Section titled “Problem 44 [Page replacement]: Recently Used Pages”Consider the reference string 1, 2, 3, 4, 5, 2, 3, 4, 3, 2, 4, 2, 4. Assuming the working set strategy, determine the minimum window size such that the string generates at most 5 page faults. Show which pages are in the working set (and, thus, in memory) at each reference.
Instructor Solution
First of all, notice that regardless of the WS size, the first 5 page references will each cause a page fault. After that we must never have a page fault so that the total number of page faults is 5 at the end. If we analyze the rest of the string after 5, the only referenced pages are {2, 3, 4}. This means that these 3 pages must always be in the WS after page 5 is referenced. Using this information, if WS = 5, after page reference 5, WS = {1, 2, 3, 4, 5}. Then in the rest of the page references, we won’t have any page faults. So we have a total of 5 page faults.
Is 5 the minimum possible WS size? Let’s see if WS = 4 works. After the first 4 references, WS = {1, 2, 3, 4}. After page 5 is referenced, we must evict a page. Given that we will need pages 2, 3, and 4 in the future, we will evict page 1. So WS = {2, 3, 4, 5}. In the rest of the reference string, we are only referencing pages 2, 3 and 4, all of which are in the WS. So, no more page faults. So WS=4 also works.
How about WS = 3? After the first 3 page references, WS = {1, 2, 3}. When we reference page 4, we have to evict one page. Given that we need 2 and 3 in the future, we have to evict 1. So, WS = {2, 3, 4}. Now, when we reference page 5, we have to evict a page from WS. But we need al of these pages in the future. So regardless of which page we evict from the WS, that evicted page will result in an page fault in the future. This means that WS size = 3 does not work.
So, WS must have a size of at least 4 in order for us to have at most 5 page faults.
Private Concise answer (by LLM)
The minimum window size is 4: the first 5 references always cause compulsory faults, and after that the tail only uses pages {2, 3, 4} — a window of 4 can hold all three while accommodating page 5, but a window of 3 cannot hold all of {2, 3, 4} simultaneously and will generate additional faults.
Concise answer (by LLM):
The minimum window size is 4: the first 5 references cause unavoidable compulsory faults, and after reference 5 the remaining string only uses pages {2, 3, 4} — a window of 4 is needed to keep all three in memory while bringing in page 5, whereas a window of 3 cannot hold all of {2, 3, 4} simultaneously.
Elaboration (by LLM)
This problem asks about the Working Set strategy and asks you to reason backward from a fault budget.
What Is the Working Set Strategy?
The working set strategy says: keep in memory exactly the set of pages referenced during the last (delta) time units — the window size. Pages outside the working set are evicted. The key idea is that a process’s locality — the small cluster of pages it actively uses — changes slowly over time. The window captures this locality.
As time (references) progresses, the window slides forward and pages fall in or out of the working set.
Reasoning From the Fault Budget
The key observation the instructor makes:
- The first 5 references (pages 1, 2, 3, 4, 5) are all unique → 5 compulsory faults, unavoidable.
- The remaining 8 references (2, 3, 4, 3, 2, 4, 2, 4) only touch pages {2, 3, 4}.
- To hit exactly 5 total faults, we need zero additional faults after ref 5.
- That means pages 2, 3, and 4 must always be in the working set from ref 5 onward.
Testing WS = 4 (the Answer)
Let’s trace the working set with :
| Ref # | Page | Window (last 4) | Working Set |
|---|---|---|---|
| 1 | 1 | {1} | {1} — fault |
| 2 | 2 | {1,2} | {1,2} — fault |
| 3 | 3 | {1,2,3} | {1,2,3} — fault |
| 4 | 4 | {1,2,3,4} | {1,2,3,4} — fault |
| 5 | 5 | {2,3,4,5} | {2,3,4,5} — fault (1 drops out) |
| 6 | 2 | {3,4,5,2} | {2,3,4,5} — hit |
| 7 | 3 | {4,5,2,3} | {2,3,4,5} — hit |
| 8 | 4 | {5,2,3,4} | {2,3,4,5} — hit |
| 9 | 3 | {2,3,4,3} | {2,3,4} — hit (5 drops out) |
| 10 | 2 | {3,4,3,2} | {2,3,4} — hit |
| 11 | 4 | {4,3,2,4} | {2,3,4} — hit |
| 12 | 2 | {3,2,4,2} | {2,3,4} — hit |
| 13 | 4 | {2,4,2,4} | {2,4} — hit (3 falls out of window but still hit for page 4) |
After ref 5, the working set always contains {2, 3, 4} — no additional faults. Total: 5 faults. ✅
Why WS = 3 Fails
With , after refs 1–3, WS = {1,2,3}:
- Ref 4 (page 4): window = {2,3,4}, page 1 drops out — fault (load 4).
- Ref 5 (page 5): window = {3,4,5}, page 2 drops out — fault (load 5).
- But then ref 6 is page 2 — and 2 is no longer in memory! → Another fault.
The working set of size 3 cannot hold all three of {2, 3, 4} simultaneously alongside the new pages, so additional faults accumulate beyond 5.
Key Insight
The minimum working set size equals the number of distinct pages needed simultaneously after the initial compulsory faults. Here, that’s {2, 3, 4} = 3 pages, but we also need room to bring in page 5 before evicting page 1, which requires a window of at least 4.
Problem 45 [Page replacement]: Not Recently Used (NRU)
Section titled “Problem 45 [Page replacement]: Not Recently Used (NRU)”Why is it difficult to perfectly implement LRU page replacement algorithm? What bit(s) in the PTE do OSs use to approximate LRU?
Instructor Solution
Implementing a perfect Least Recently Used (LRU) algorithm is difficult because it requires the hardware to maintain a precise chronological record of every memory access. To do this perfectly, the system would need to:
-
Update a timestamp or a stack on every single memory reference.
-
Search or sort through these values during a page fault to find the oldest one.
Doing this in software is too slow, and doing it in hardware is too expensive and complex for high-speed CPU cycles. Instead of perfect LRU, most Operating Systems use the Reference Bit found in the Page Table Entry (PTE). When a page is referenced (read or written), the hardware automatically sets this bit to 1. The OS periodically clears these bits to 0. By checking which bits are still 1, the OS identifies “recently used” pages versus “not recently used” pages.
Private Concise answer (by LLM)
Perfect LRU requires updating a timestamp or stack on every memory reference — far too expensive at CPU speeds; instead, OSes use the Reference (Accessed) bit in each PTE: hardware sets it on any access, and the OS periodically clears it, so pages with a cleared bit are “not recently used” candidates for eviction.
Concise answer (by LLM):
Perfect LRU is impractical because tracking exact per-page access order in hardware is too expensive; instead, OSes use the Reference bit in each PTE — the hardware sets it on access and the OS periodically clears it — to approximate which pages haven’t been used recently.
Elaboration (by LLM)
Why Perfect LRU Is Impractical
LRU sounds simple in theory: “evict the page you used longest ago.” But implementing it perfectly requires knowing, at every point in time, the exact order in which pages were last used. There are two hardware approaches that would work in theory:
Option 1: Timestamps
On every memory access, record the current clock value in the page’s PTE:
PTE: [ frame# | valid | dirty | timestamp ]To evict: scan all PTEs and find the smallest timestamp.
Problem: Memory is accessed billions of times per second. Updating a timestamp on each access requires a hardware write to the page table — very expensive.
Option 2: Hardware Stack
Maintain a stack of page numbers. On each access, move the referenced page to the top. The bottom is always the LRU page.
Problem: Moving an arbitrary page to the top of a hardware stack requires shifting all pages between — complex, expensive circuitry for potentially hundreds of frames.
Both options are impractical because memory accesses happen at CPU speed — every nanosecond. Any hardware bookkeeping must also happen in nanoseconds or it becomes the bottleneck.
The Reference Bit: A Practical Approximation
Modern hardware adds a single Reference bit (also called the Accessed bit) to each Page Table Entry:
PTE Layout (simplified):┌─────────────┬───────┬───────┬────────┬─────────────────┐│ Frame # │ Valid │ Dirty │ Ref │ (other flags) │└─────────────┴───────┴───────┴────────┴─────────────────┘ ↑ Hardware sets to 1 on any access OS periodically resets to 0How it works:
- The hardware sets Ref = 1 automatically whenever the page is read or written.
- The OS periodically (e.g., on a timer interrupt) scans all PTEs and resets Ref bits to 0.
- During a page fault, pages with Ref = 0 are “not recently used” candidates for eviction; pages with Ref = 1 are “recently used” and spared.
Limitations of the Reference Bit
The reference bit is a coarse approximation:
- It only tells you whether a page was used since the last reset — not how many times or in what order.
- Two pages both referenced recently (both Ref = 1) are treated equally, even if one was accessed 1 ms ago and the other 500 ms ago.
This is why real OS designs layer additional techniques on top — like the shift register approach (keeping a history of reference bits over multiple intervals) or the Clock algorithm (see Problems 46 and 47).
Problem 46 [Page replacement]: LRU Clock or Second Chance
Section titled “Problem 46 [Page replacement]: LRU Clock or Second Chance”Briefly explain how LRU clock or second chance algorithm works.
Instructor Solution
The Clock (Second Chance) algorithm approximates LRU by using a Reference Bit in each Page Table Entry and a “clock hand” pointing to the next victim candidate. Here is how it works:
-
Hardware Action: When a page is accessed, the hardware sets its Reference Bit to 1.
-
Software Action (on Page Fault): The OS inspects the page at the clock hand:
-
If Bit is 1: The page gets a “second chance.” The OS clears the bit to 0 and moves the hand to the next page.
-
If Bit is 0: This page hasn’t been used since the last pass. The OS selects it as the victim for eviction.
- Advance Hand: After an eviction and replacement, the clock hand moves to the next position for the next fault.
Private Concise answer (by LLM)
The Clock algorithm arranges frames in a circular buffer with a hand pointer; on a page fault it walks the buffer evicting the first frame with reference bit = 0, while frames with bit = 1 get a second chance by having the bit cleared as the hand passes — approximating LRU with low overhead.
Concise answer (by LLM):
The Clock (Second Chance) algorithm arranges frames in a circular buffer with a hand pointer; on a page fault it evicts the first frame whose reference bit is 0, while frames with reference bit 1 get a second chance by having the bit cleared as the hand passes them.
Elaboration (by LLM)
The Clock algorithm is one of the most widely used page replacement approximations in real operating systems. The name comes from its data structure: pages in memory are arranged in a circular list like the face of a clock, with a “hand” pointer that sweeps around.
The Clock Structure
┌─── clock hand ↓ ┌─────────┐ ┌──┤ Page A │ ref=1 │ └─────────┘ │ ┌─────────┐ │ │ Page B │ ref=0 ← hand finds this first → EVICT │ └─────────┘ │ ┌─────────┐ │ │ Page C │ ref=1 │ └─────────┘ │ ┌─────────┐ └──│ Page D │ ref=0 └─────────┘ ↑ (circular)Step-by-Step Algorithm
On a page fault (a page must be loaded but frames are full):
-
- Inspect the page at the current clock hand position.
- If ref bit = 1: Give it a “second chance” — clear the bit to 0, advance the hand, and go back to step 1.
- If ref bit = 0: This page hasn’t been touched since the hand last passed it. Evict it, load the new page in its place, set the new page’s ref bit to 1, and advance the hand.
Between faults, the hardware continuously sets ref bits to 1 as pages are accessed.
A Worked Mini-Example
Suppose we have 4 frames and a fault occurs. The circular state is:
| Position | Page | Ref Bit |
|---|---|---|
| 0 (hand) | A | 1 |
| 1 | B | 1 |
| 2 | C | 0 |
| 3 | D | 1 |
The algorithm proceeds:
- Position 0 (A): ref=1 → clear to 0, advance hand.
- Position 1 (B): ref=1 → clear to 0, advance hand.
- Position 2 (C): ref=0 → evict C, load new page here, set ref=1. Hand advances to position 3.
After eviction, state:
| Position | Page | Ref Bit |
|---|---|---|
| 0 | A | 0 |
| 1 | B | 0 |
| 2 | New | 1 |
| 3 (hand) | D | 1 |
Why Is It Called "Second Chance"?
A page with ref=1 is not immediately evicted — it gets a second chance by having its bit cleared. This mimics LRU’s preference for recently used pages: a page used recently will have ref=1 and survive the sweep. A page untouched since the last sweep will have ref=0 and be evicted.
Performance Characteristics
- Best case: The hand finds a ref=0 page immediately — O(1).
- Worst case: All pages have ref=1 — the hand sweeps the entire circle, clearing all bits, then evicts the first page it started at — O(n). This degenerates to FIFO.
- In practice: Clock is much closer to LRU than to FIFO, with very low overhead.
Problem 47 [Page replacement]: Enhanced Second Chance Algorithm
Section titled “Problem 47 [Page replacement]: Enhanced Second Chance Algorithm”Briefly explain how LRU enhanced second chance algorithm works.
Instructor Solution
The Enhanced Second Chance algorithm improves the basic Clock algorithm by considering both the Reference (R) bit and the Modify/Dirty (M) bit. This prioritizes keeping pages that have been modified to avoid the high cost of writing them back to disk. The OS searches for a victim by categorizing pages into four classes (in order of preference for eviction):
-
(0, 0): Neither recently used nor modified (Best candidate).
-
(0, 1): Not recently used, but modified (Requires a disk write).
-
(1, 0): Recently used, but clean (Likely to be used again).
-
(1, 1): Recently used and modified (Worst candidate).
The process: The “clock hand” scans the circular buffer. It looks for the first page in the lowest available class. During the scan, it may also clear the Reference bits (changing a class 3 to a class 2, or a class 4 to a class 2) to give pages a “second chance” before they are eventually evicted. By favoring the eviction of clean pages (Classes 1 and 3), the system significantly reduces total I/O overhead.
Private Concise answer (by LLM)
Enhanced Second Chance extends Clock by scoring pages with both the reference (R) and dirty (M) bits into four eviction-priority classes:
- (0, 0): unused and clean — cheapest to evict (just discard)
- (0, 1): unused but dirty — requires a disk write-back before eviction
- (1, 0): recently used, clean — spared to reduce re-faults
- (1, 1): recently used and dirty — most expensive; evicted last
The clock hand scans for the lowest-priority class available, clearing R bits on (1,x) pages it passes to demote them for future scans.
Concise answer (by LLM):
The Enhanced Second Chance algorithm extends Clock by using both the reference (R) and dirty (M) bits to prioritize evictions into four classes:
- (0, 0): unused and clean — evicted first (just discard)
- (0, 1): unused but dirty — requires a disk write-back
- (1, 0): recently used, clean — spared over dirty unused pages
- (1, 1): recently used and dirty — evicted last
The clock hand seeks the lowest-priority class available, clearing R bits on recently-used pages it passes so they become candidates on the next scan.
Elaboration (by LLM)
The Enhanced Second Chance algorithm (also called NRU+ or Enhanced Clock) adds a critical insight to the basic Clock: not all evictions are equally costly.
The Cost of Eviction
When you evict a clean page (ref=0, dirty=0): just discard it. The disk copy is already up-to-date.
When you evict a dirty page (dirty=1): you must write it back to disk first before loading the new page. This disk write is orders of magnitude slower (milliseconds vs. nanoseconds).
The Enhanced Second Chance algorithm uses this to make smarter eviction choices.
The Four Classes
Every page falls into one of four priority classes based on its (R, M) bits:
| Class | (R, M) | Meaning | Eviction Cost |
|---|---|---|---|
| 1 | (0, 0) | Unused, clean | Cheapest — just discard |
| 2 | (0, 1) | Unused, dirty | Medium — must write to disk |
| 3 | (1, 0) | Used recently, clean | Medium — likely needed again |
| 4 | (1, 1) | Used recently, dirty | Most expensive — likely needed AND must write |
The algorithm always tries to evict the lowest-numbered class available.
The Search Process
The clock hand makes multiple passes over the circular buffer:
-
- Pass 1: Look for a Class 1 (0,0) page. Do not modify any bits during this pass.
- Pass 2: Look for a Class 2 (0,1) page. During this pass, clear R bits of any Class 3/4 pages encountered (turning them into Class 1/2 candidates for future evictions).
- If neither pass finds a victim, repeat from Pass 1 — but by now some Class 3/4 pages will have had their R bits cleared, demoting them.
Eventually a victim is always found (in the worst case, after all R bits are cleared, every page is class 1 or 2).
Visual Summary
On fault: search for victim ↓ ┌──────────────────────┐ │ Pass 1: Find (0,0) │ ← cheapest eviction └──────────┬───────────┘ Not found? ↓ ┌──────────────────────┐ │ Pass 2: Find (0,1) │ ← also clear R bits on (1,x) pages └──────────┬───────────┘ Not found? ↓ ┌──────────────────────┐ │ Repeat (R bits now │ ← previously (1,0) → now (0,0) │ cleared from Pass 2)│ previously (1,1) → now (0,1) └──────────────────────┘Why Prioritize (0,1) Over (1,0)?
This is the counterintuitive part of the Enhanced Second Chance algorithm. Class 2 (not recently used, dirty) is preferred over Class 3 (recently used, clean) for eviction — even though Class 2 requires a disk write.
The reasoning: a Class 3 page was used recently, which strongly suggests it will be needed again soon. Evicting it would likely cause an immediate page fault on re-access. A Class 2 page hasn’t been used recently, so it’s less likely to cause an immediate re-fault — the disk write overhead is worth it to avoid the re-fault.
Problem 48 [Page replacement]: Working Set of a Process
Section titled “Problem 48 [Page replacement]: Working Set of a Process”What’s meant by the working set of a process. Given the reference string 1, 2, 3, 2, 1, 3, 2, 1 and a reference window size of 5, what’s the process’s working set at the end of the last page reference?
Instructor Solution
The Working Set of a process is the collection of unique pages referenced by that process during a specific most recent time interval (defined by a window size Delta). It represents the set of pages the process actively needs in memory to avoid excessive page faults (thrashing). Notice that the only pages we reference in the reference string are 1, 2 and 3. Given a WS size of 5, all of these pages will be in the WS. So the final WS = {1, 2, 3}.
Private Concise answer (by LLM)
A process’s working set is the collection of distinct pages it has accessed within the last Δ references — the OS uses it to determine how many frames to allocate; here with Δ = 5 the window always captures all three unique pages, so the final working set is {1, 2, 3}.
Concise answer (by LLM):
The working set of a process is the set of distinct pages it has referenced within the last references; with over string 1,2,3,2,1,3,2,1, all three unique pages always fall within the window, so the final working set is {1, 2, 3}.
Elaboration (by LLM)
Working Set: Formal Definition
The Working Set at time with window size is the set of distinct pages referenced during the most recent memory references:
Intuitively, it answers: “If I look at the last accesses, which unique pages did this process touch?”
Tracing the Working Set Over Time
Reference string: 1, 2, 3, 2, 1, 3, 2, 1, window size .
| Step (t) | Page Ref | Last 5 References | Working Set |
|---|---|---|---|
| 1 | 1 | {1} | {1} |
| 2 | 2 | {1, 2} | {1, 2} |
| 3 | 3 | {1, 2, 3} | {1, 2, 3} |
| 4 | 2 | {1, 2, 3, 2} | {1, 2, 3} |
| 5 | 1 | {1, 2, 3, 2, 1} | {1, 2, 3} |
| 6 | 3 | {2, 3, 2, 1, 3} | {1, 2, 3} |
| 7 | 2 | {3, 2, 1, 3, 2} | {1, 2, 3} |
| 8 | 1 | {2, 1, 3, 2, 1} | {1, 2, 3} |
Final working set: {1, 2, 3}
Notice that once all three pages are in the working set, the set stabilizes — because the reference string only ever uses these three pages, and with , all three always fall within the window.
Why Does the Working Set Matter?
The working set model is used by the OS to decide how many frames to allocate to each process:
- The OS tries to keep in memory for each process.
- If a process’s working set cannot fit in its allocated frames, it will page fault repeatedly — this is the beginning of thrashing (see Problem 49).
- By monitoring working set sizes, the OS can decide to suspend processes (to free frames for others) rather than letting all processes thrash simultaneously.
Working Set vs. Fixed Frame Allocation
| Approach | How frames are allocated | Problem |
|---|---|---|
| Fixed | Give each process a fixed number of frames | Some processes get too many, others too few |
| Working Set | Give each process exactly its working set size | Dynamic, adapts to locality changes |
The working set approach naturally adapts to phase changes in a program — when a program transitions from one phase (e.g., processing arrays) to another (e.g., recursive calls), its working set changes, and the OS adjusts allocations accordingly.
Problem 49 [Page replacement]: Thrashing
Section titled “Problem 49 [Page replacement]: Thrashing”What’s trashing and how does it occur? Briefly explain.
Instructor Solution
Thrashing is a state of extreme performance degradation where the OS spends significantly more time swapping pages in and out of disk than actually executing instructions. It occurs when the sum of the working sets of all active processes exceeds the total number of available physical memory frames.
-
High Multiprogramming: The OS admits too many processes into memory.
-
Frame Depletion: Each process receives fewer frames than it needs to store its active “working set.”
-
Continuous Faulting: A process faults, evicts a page from another process, which then immediately faults to get that page back.
-
CPU Idle Time: Because processes are constantly waiting for disk I/O, CPU utilization drops. The OS may mistakenly try to increase multiprogramming to compensate, making the problem even worse.
Private Concise answer (by LLM)
Thrashing happens when the combined working sets of all active processes exceed available physical frames — each process constantly page-faults and evicts pages that other processes immediately need back, so the CPU spends most of its time waiting on disk I/O and naively adding more processes only makes it worse.
Concise answer (by LLM):
Thrashing occurs when the combined working sets of all active processes exceed available physical frames — processes constantly page-fault and evict each other’s pages, so the CPU spends most of its time waiting on disk I/O rather than executing instructions.
Elaboration (by LLM)
The Thrashing Cascade
Thrashing is a positive feedback loop — once it starts, naive OS responses make it worse:
Too many processes admitted ↓Each process gets too few frames ↓Processes page fault constantly ↓CPU spends time waiting for disk I/O ↓CPU utilization appears low ↓OS (wrongly) admits MORE processes to "use" the CPU ↓ ↺ (makes thrashing worse)The OS scheduler sees idle CPU time and thinks “I should run more processes.” But CPU is idle because processes are waiting on disk, not because there’s nothing to do. Adding more processes only deepens the memory shortage.
The CPU Utilization Curve
The relationship between degree of multiprogramming and CPU utilization looks like this:
CPUUtil. 100% | ╭──────────╮ | ╭╯ ╲ | ╭╯ ╲ | ╭╯ ╲ ← Thrashing begins here | ╱ ╲ | ╱ ↓ 0%└────────────────────────────────── 0 N* N processes ↑ Optimal degree of multiprogrammingPast the optimal point , adding more processes reduces CPU utilization because memory becomes the bottleneck, not the CPU.
Formal Condition for Thrashing
Thrashing occurs when:
where is the working set of process . When the sum of all working sets exceeds available memory, it is mathematically impossible for all processes to have their working sets resident simultaneously.
How OSes Prevent or Recover From Thrashing
- Working Set Model: Only admit a new process if enough free frames exist to hold its working set. Proactive prevention.
- Page Fault Frequency (PFF) Control: Monitor each process’s page fault rate. If it’s too high → give it more frames. If it’s too low → take frames away. If no frames are available when a process needs more → suspend a process.
- Process Suspension: Swap out an entire process to disk (freeing all its frames) to relieve memory pressure. The suspended process’s working set is temporarily sacrificed so others can run cleanly.
- Swapping / Swap Space: Related to suspension — the entire address space of a process is written to a swap partition, completely freeing its frames.