Lec 04-30-2026: Lines & Planes (cont.) & Support Vector Machines | MATH 245
Lines & Planes (cont)
Section titled “Lines & Planes (cont)”(Ending of our Linear Algebra recap)
In our last lecture, we introduced the notion of a hyperplane. Recall that a hyperplane is a flat -dimensional surface in - a line in , a flat plane in , and so on. Algebraically, a hyperplane is given by :
In 2D, this becomes . Rearranging to isolate (which plays the role of ):
Note: the "" in slope-intercept form here is , which is a different value from the in the original hyperplane equation - they just happen to share the same letter.
Theorem: is Orthogonal to the Hyperplane
Section titled “Theorem: w⃗\vec{w}w is Orthogonal to the Hyperplane”Proof
To show is orthogonal to the entire hyperplane, it suffices to show it is orthogonal to any vector lying parallel to the hyperplane (since such vectors span all directions within the hyperplane). Let be an arbitrary vector parallel to the hyperplane, with & pointing from the origin to the base & tip of respectively.

Since & begin from the origin, we have:
Since the tips of & lie on the hyperplane , they each satisfy the hyperplane equation:
Subtracting the second equation from the first eliminates , leaving:
Hence is orthogonal to . Since is parallel to the hyperplane, then is also orthogonal to the hyperplane.
Corollary
Section titled “Corollary”(Another structure of math)
This follows immediately from the theorem: is just scaled by the positive scalar , so it points in the exact same direction as . Since orthogonality depends only on direction, is orthogonal to the hyperplane too.
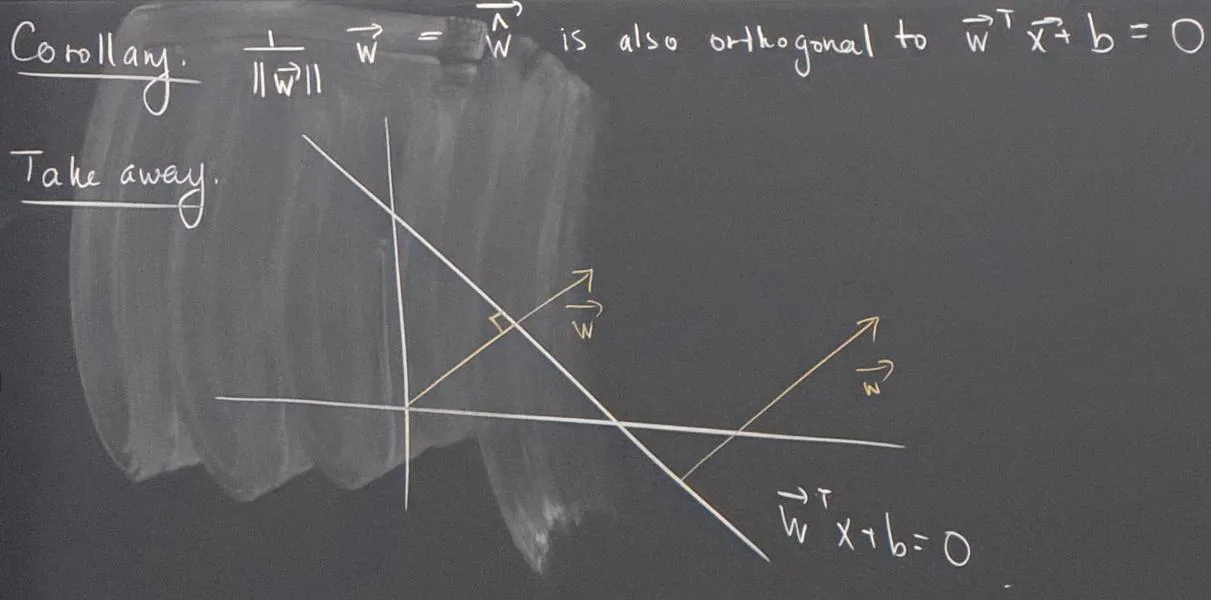
Take Away
Section titled “Take Away”By default, we draw with its tail at the origin. However, since represents a direction (perpendicular to the hyperplane), we can translate it to start from any point and it still correctly describes the orientation of the hyperplane - as the diagram below illustrates.
Distance from a Point to a Hyperplane
Section titled “Distance from a Point to a Hyperplane”Given a point not on the hyperplane, we want the shortest distance from to the hyperplane. As before, the hyperplane is defined by .
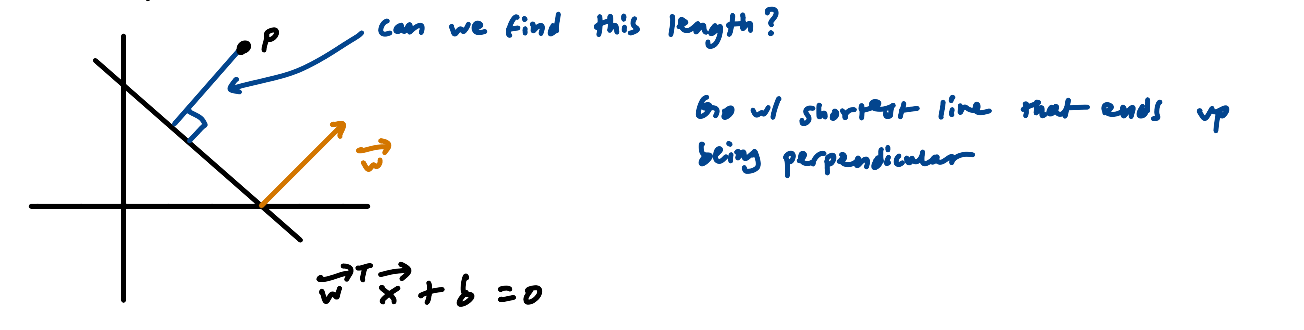
There are infinitely many line segments connecting to some point on the hyperplane, but the shortest one is always the perpendicular one. (Any non-perpendicular segment forms the hypotenuse of a right triangle whose leg includes the perpendicular segment, making it strictly longer.) So we go with the perpendicular segment.
Setting Up Variables
Section titled “Setting Up Variables”Step 1: Project P onto the hyperplane:
- Call the vector from the origin to the projection of :
- Call the vector between & :
- Call the vector between the origin & :

From the diagram:
Deriving the Distance
Section titled “Deriving the Distance”Since the tip of lies on the hyperplane, then .
Since is the perpendicular segment from to the hyperplane, it is orthogonal to the hyperplane. But is also orthogonal to the hyperplane. Two vectors that are both perpendicular to the same surface must be parallel to each other, so is a scalar multiple of :
Again our goal is to use this to find the length between P & the hyperplane, aka .
Substituting Eq 1 into :
Since , by Eq 3:

Support Vector Machines (SVM)
Section titled “Support Vector Machines (SVM)”
SVMs are a type of supervised learning.
Idea: Given a bunch of data points which belong to 1 of 2 classes, the goal is to decide which class a new datapoint will belong to.
Example: In medicine, a tumor is an abnormal growth of cells which may or may not be cancerous.
Wisconsin Breast Cancer Dataset (1995)
Section titled “Wisconsin Breast Cancer Dataset (1995)”Let’s develop a model which can attempt to differentiate if a tumor is/isn’t cancerous based on the following training data.
Each patient’s data contains 13 features (size of tumor, cell density, length of tumor, …) and 1 label (C = cancerous, N = non-cancerous), giving 14 dimensions total. The data for patient is represented as where is encoded as or .

Each data point is a pair : a feature vector and a label. Since the output is categorical, we encode the label numerically:
Let denote the feature of patient .
- is the first feature of patient (pt) 1.
- is the second feature of patient (pt) 1.
- is either C or N.
Since cancerous tumors rapidly divide & grow uncontrollably, they tend to have measurable differences in properties like tumor size and cell density. The hypothesis is that a few of the 13 features can reliably discriminate between the two classes.
We’ll start with just 2 of the 13 features to visualize the idea, then generalize to all dimensions. The output we predict is the label for a new patient.
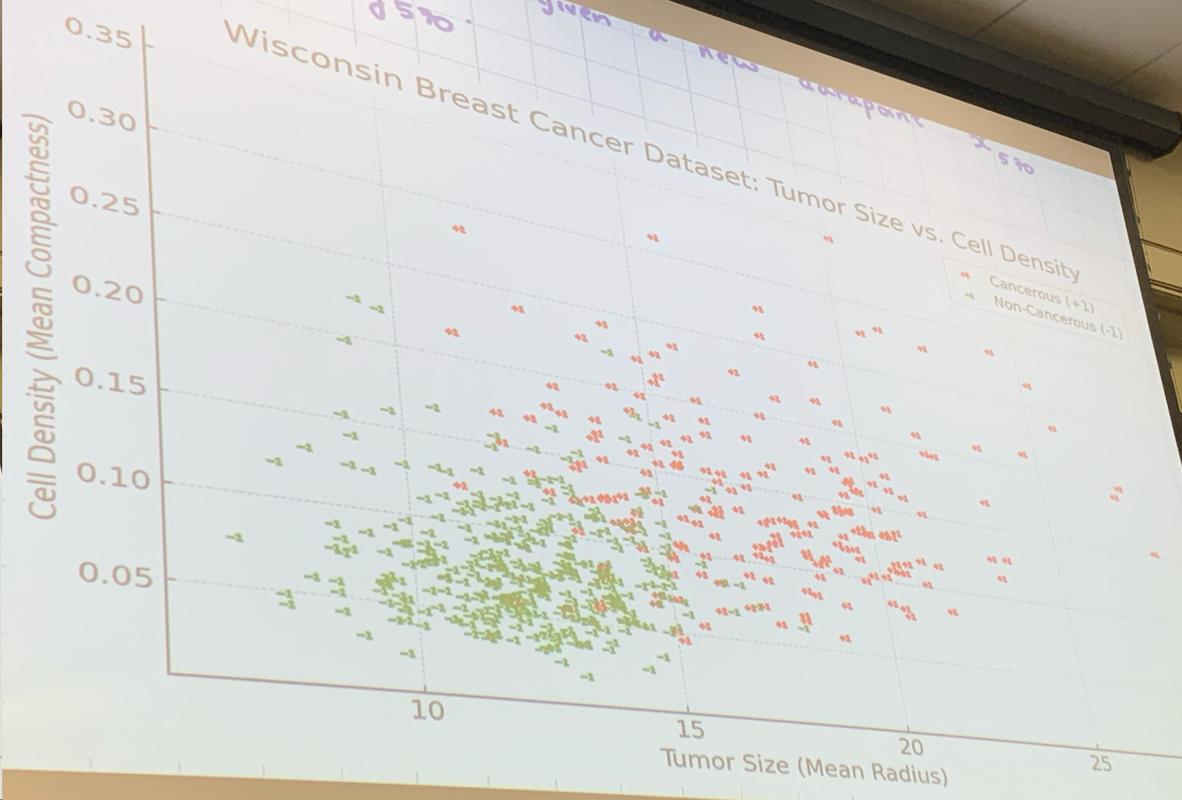
With 569 training patients plotted, now imagine a patient walks in. Their features give a new point on this scatter plot - the question is: which class does it belong to, and how do we draw the boundary that separates them?